







购买的服务器最多只支持120个并发连接,限速20Mbps,所以本次测试其实只是检验下当前系统的可用性。
登录
首先测试用户登录,为了方便测试,这里的用户设置为qq邮箱,为1-1000 依次@qq.com ,密码为P****
登录的接口为:
/user/login
'content-type': 'application/json',
需要的数据为:
{
email:"",
password: ""
}
测试接口成功如下:
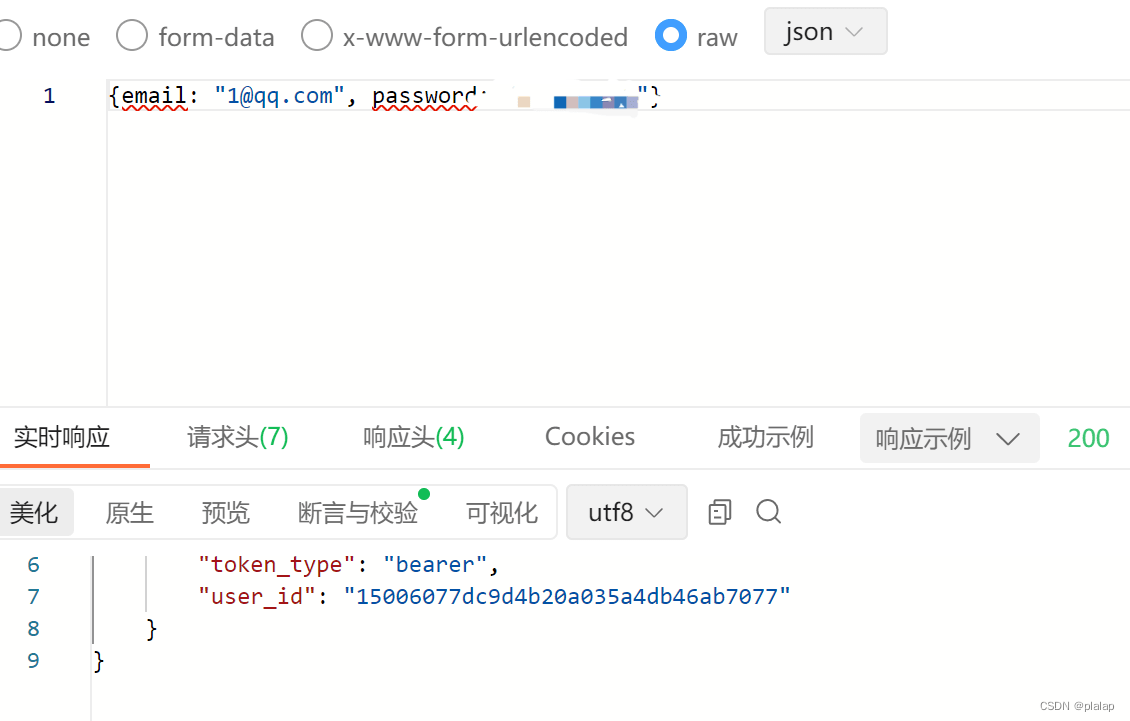
使用JMeter测试接口:
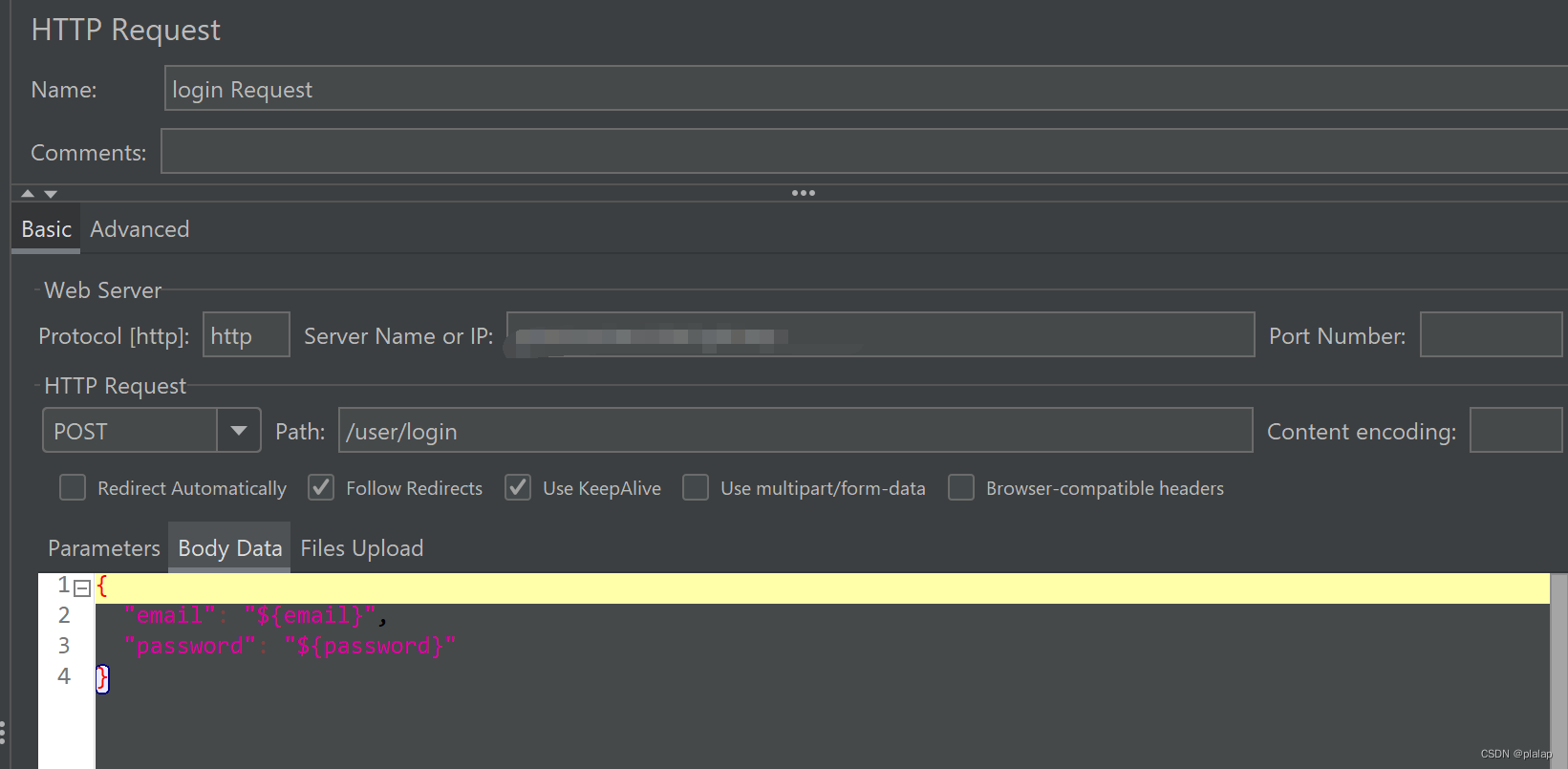
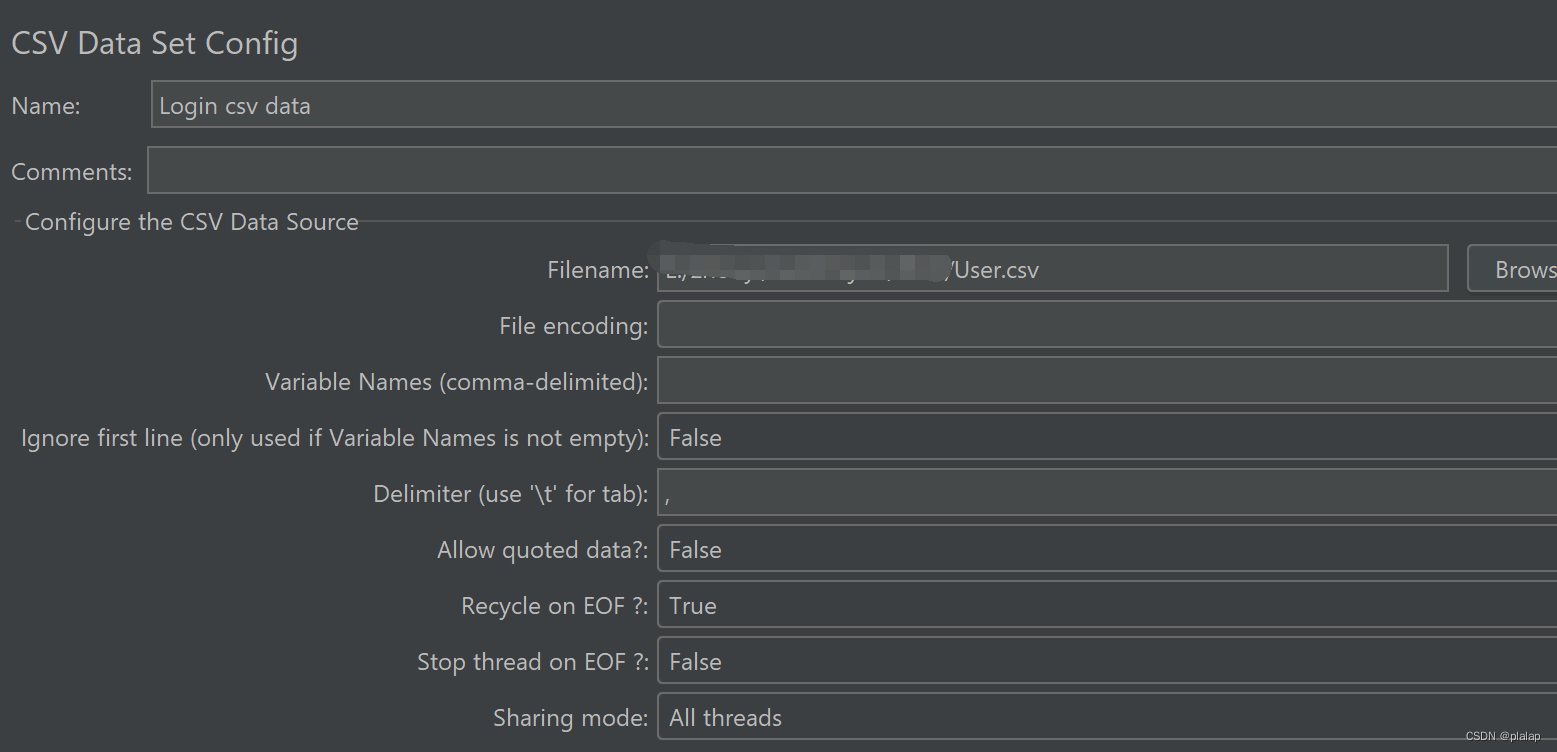
从数据库中导出1000个测试的用户,分别为id,email,password用作参数:
为了可以对response中的中文进行解析,设置BeanShell后置处理程序:
要注意配置http 头管理器:

测试结果如下:
开始测试时报错如下:
detail":[{"type":"model_attributes_type","loc":["body"],"msg":"Input should be a valid dictionary or object to extract fields from","input":"{\"email\":\"1@qq.com\", \"password\": \"P\"}"}]}
发现是空格中可能包含了其他字符,将bodydata写为一行,删除空格即可:
{"email":"${email}","password":"${password}"}
测试50个用户 1s 登录没有问题:
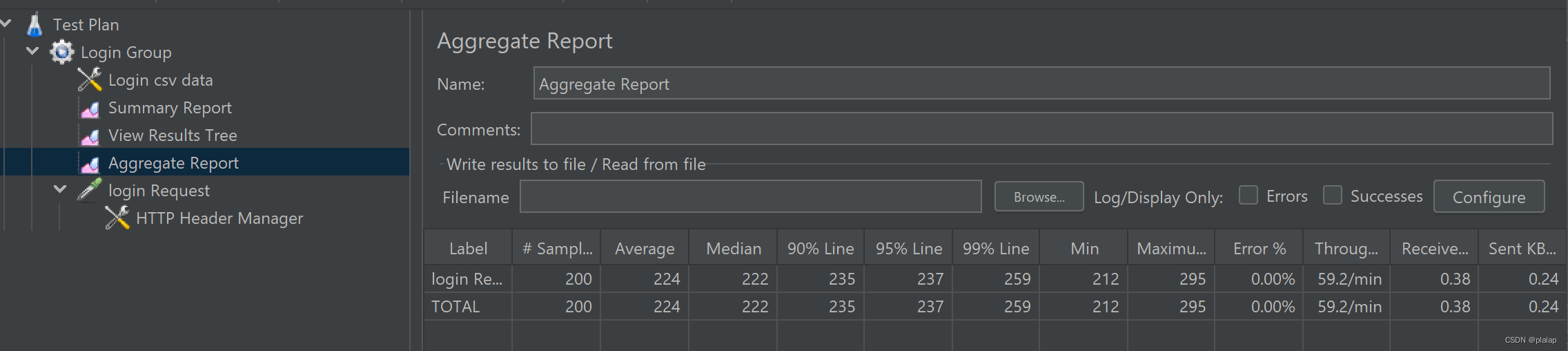
测试120个用户登录 1s并发:

测试150个:

创建对话
目的是测试多用户并发创建对话,然后进行对话,需要获取对话conv_id,并根据生成的conv_id发起请求。
接口为
conversation/new-conversation/
设置body data为:
{"user_id": "${id}","conv_name": "${name}"}
这里的name为用户发起的第一个问题,这里导入周易问答对中的问题作为测试的name:
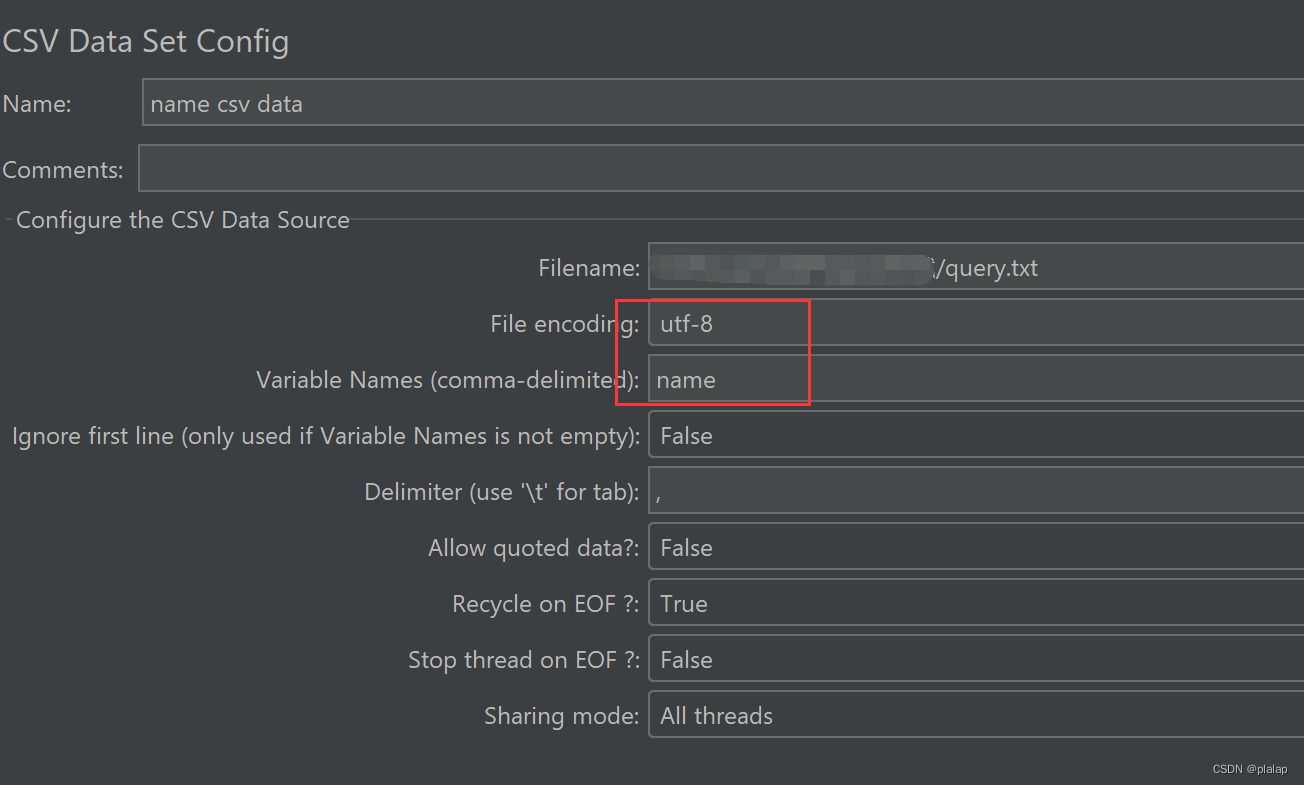
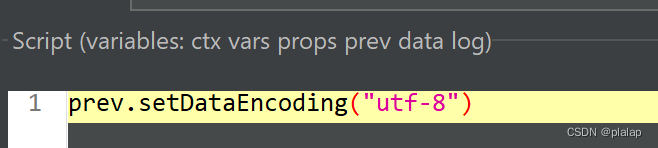
要注意file encoding设置为utf-8,不然jMeter读取中文会乱码,同时注意给定变量名name。
也要加入BeanShell后置处理程序解析response中的中文,同上设置。
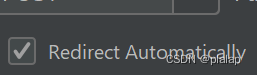
开始测试一直为307报错,应该在http request中选中自动重定向即可:
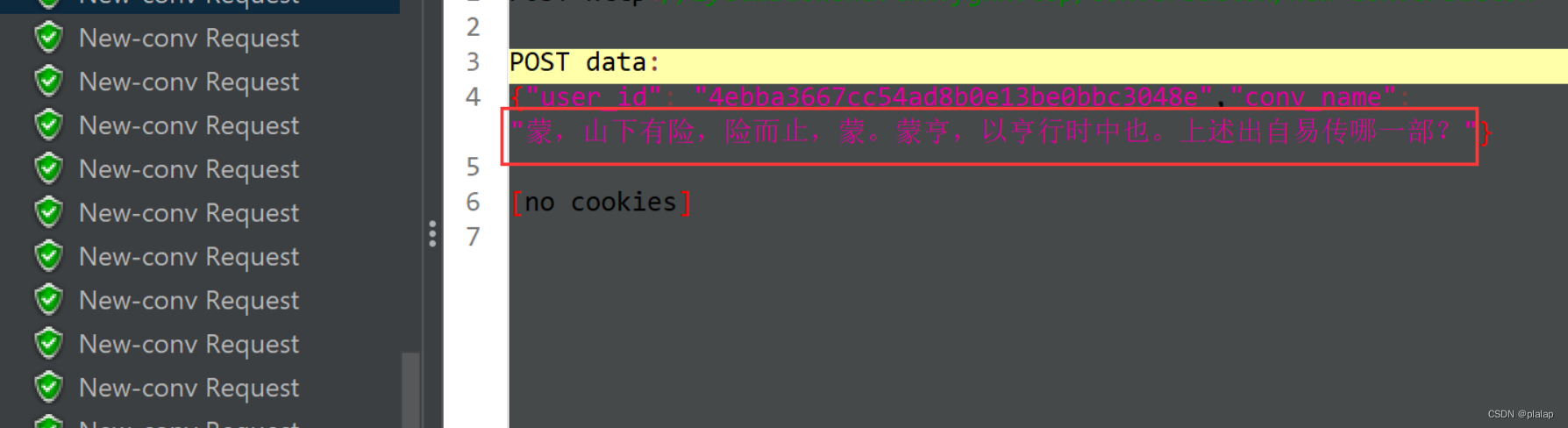
成功测试:
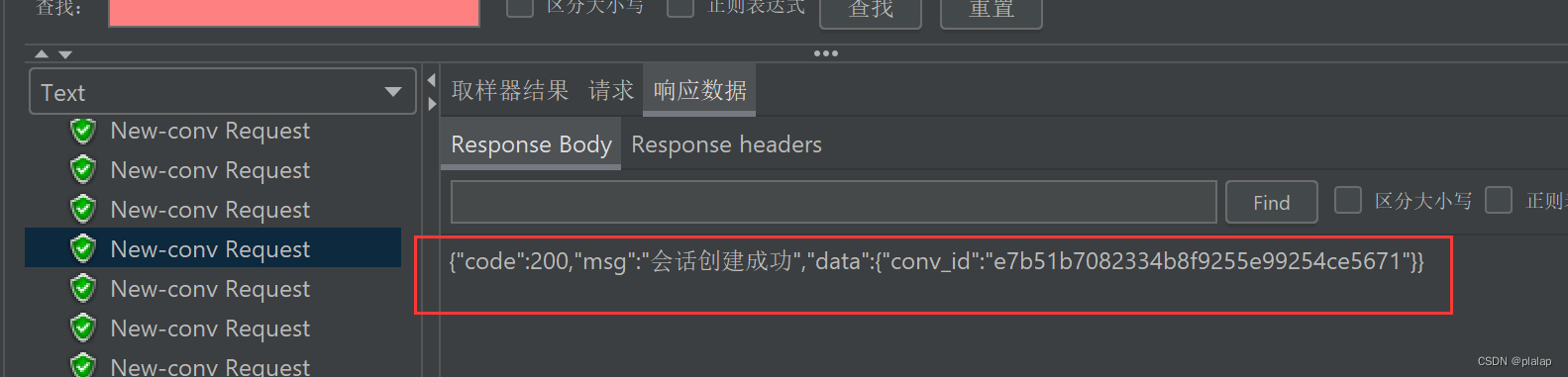
测试120个用户同时发起创建对话:效果如下:只有一个出错,其他基本没问题

测试150个用户并发,设置1s,耗时5s,结果如下:

因为响应为:
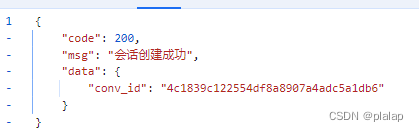
使用JSON Extractor获取返回的conv_id,作为下一个接口测试的参数: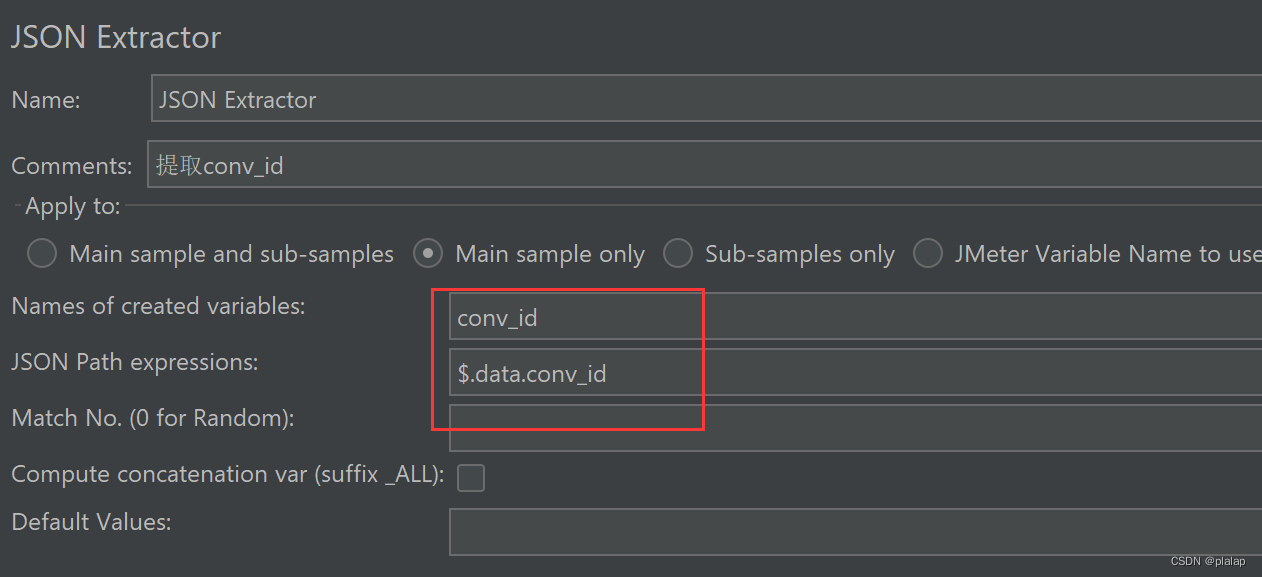
对话问答
接口为:
conversation/mix-chat/
body data为:
{"conv_id": "${conv_id}","query": "${query}","knowledge_base_id": "faiss_zhouyi"}
其他配置都同上。
因为要使用上一个接口的回答,所以ai chat和new -conv在同一个线程组中:
测试50s 50个用户并发创建对话+ai回答:
new_conv:

aichat:

查看回答效果:
首先是docs,对知识库的检索
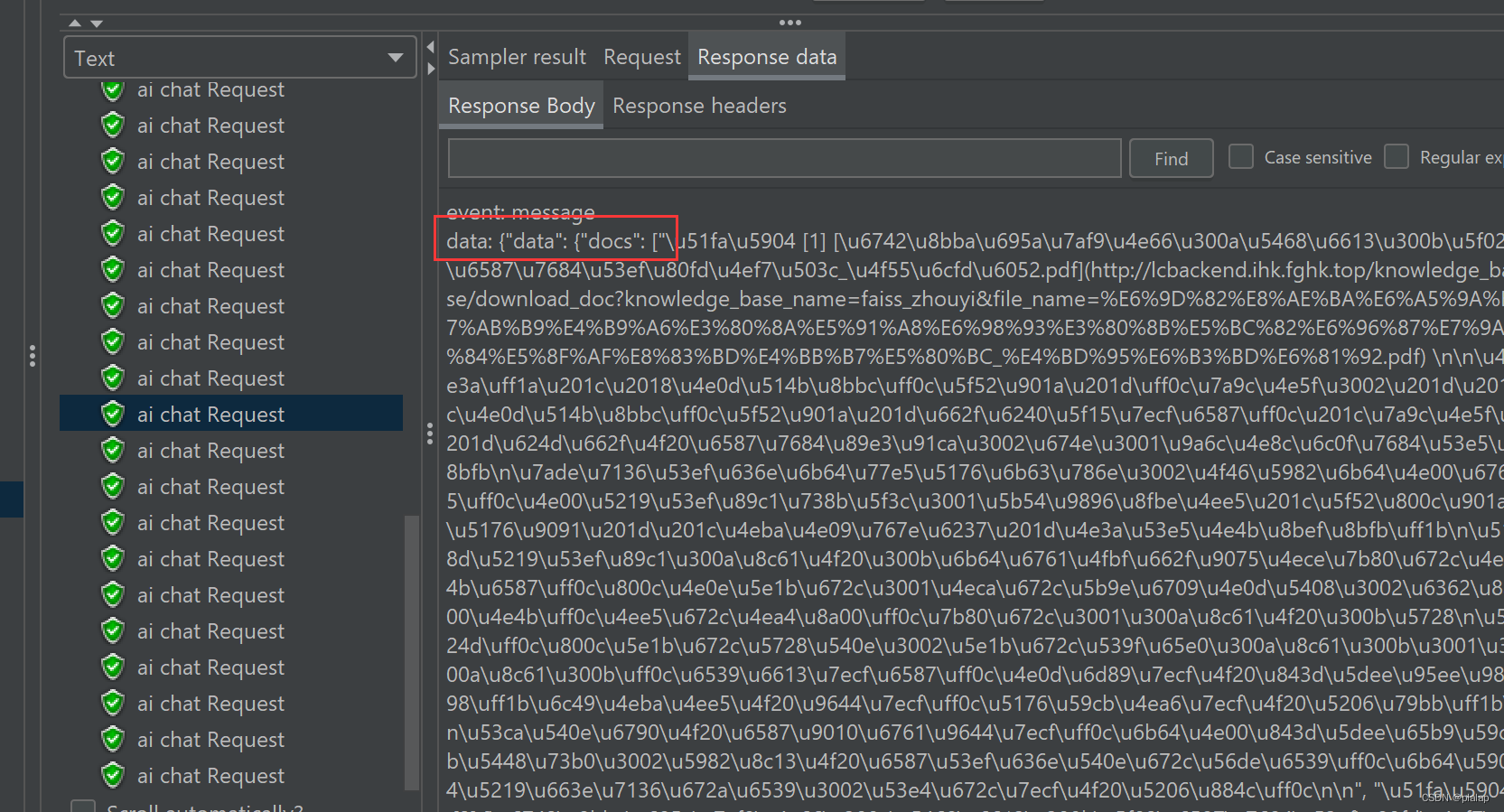
接下来是 text,大模型的回复
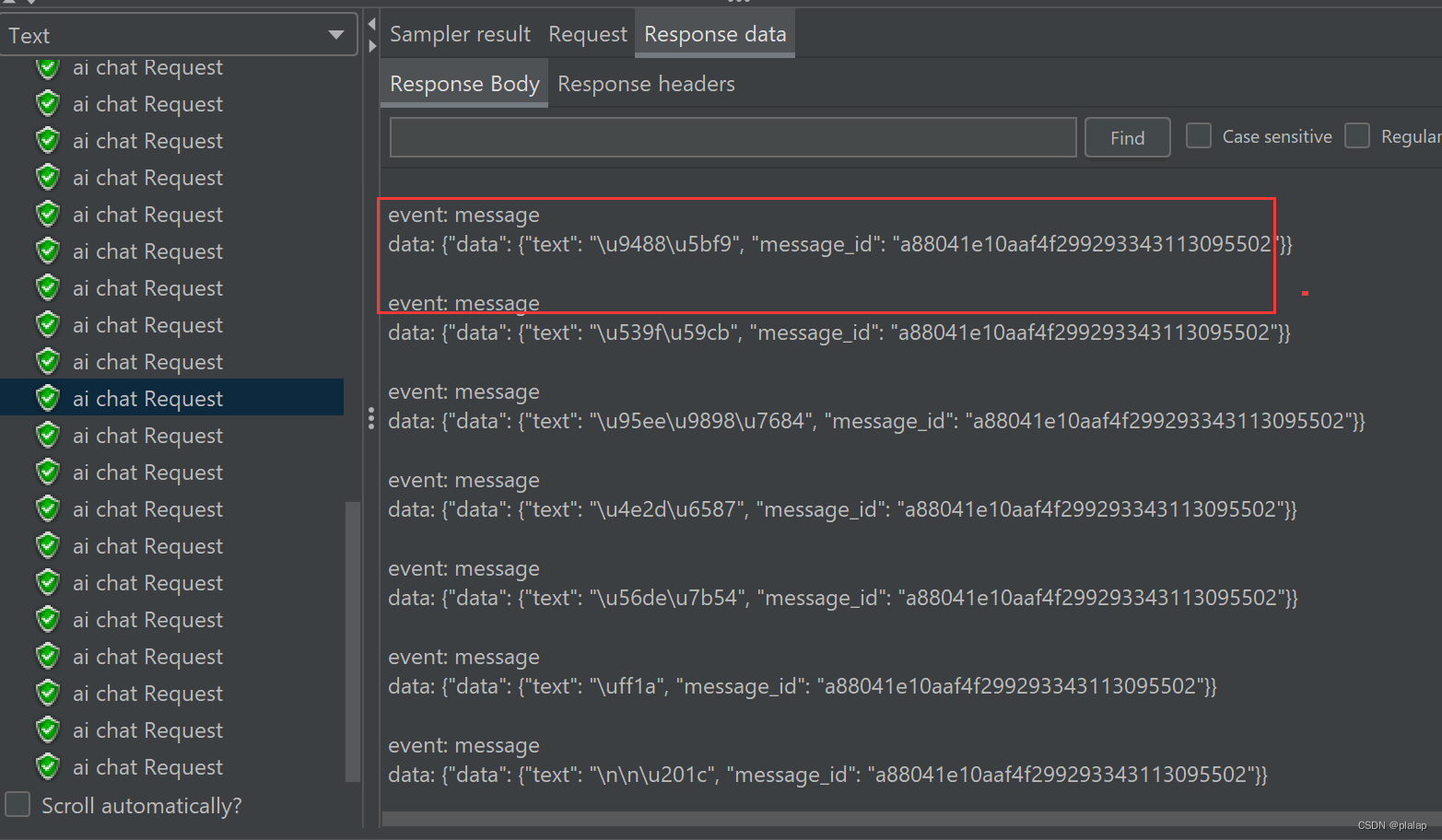
ai检索知识库并查询消耗时间长,同时还要进行sse,上面的结果在可以接受的范围内。

















 1543
1543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









