









在本节中,主要是对掘金中一些基本的功能进行讲解。
新建策略
当我们建立一个空策略后,代码显示如下图所示:
# coding=utf-8
from __future__ import print_function, absolute_import
# 引用掘金数据库
from gm.api import *
# 策略中必须有init方法,初始化
def init(context):
pass
if __name__ == '__main__':
'''
strategy_id策略ID, 由系统生成
filename文件名, 请与本文件名保持一致
mode运行模式, 实时模式:MODE_LIVE回测模式:MODE_BACKTEST
token绑定计算机的ID, 可在系统设置-密钥管理中生成
backtest_start_time回测开始时间
backtest_end_time回测结束时间
backtest_adjust股票复权方式, 不复权:ADJUST_NONE前复权:ADJUST_PREV后复权:ADJUST_POST
backtest_initial_cash回测初始资金
backtest_commission_ratio回测佣金比例
backtest_slippage_ratio回测滑点比例
backtest_match_mode市价撮合模式,以下一tick/bar开盘价撮合:0,以当前tick/bar收盘价撮合:1
'''
run(strategy_id='自己的ID',
filename='main.py',
mode=MODE_BACKTEST,
token='自己的token码',
backtest_start_time='2020-11-01 08:00:00',
backtest_end_time='2020-11-10 16:00:00',
backtest_adjust=ADJUST_PREV,
backtest_initial_cash=10000000,
backtest_commission_ratio=0.0001,
backtest_slippage_ratio=0.0001,
backtest_match_mode=1)
掘金量化交易系统虽然支持python编译,但是直观性上没有第三方IDE好,所以我采用的方法是将代码直接copy到pycharm中进行编译。
在第三方软件进行编译时,需要注意的有三点:
(1)策略ID:策略 ID 用于终端识别策略身份,如识别不同策略发来的日志、消息、回测报表,交易信号等。可在策略编辑页面点击右下角的设置按钮查看、复制策略 ID。必须和策略里run()的strategy_id一致。
(2)token:token ID 用于服务端识别用户登录身份,如从服务器提取数据。
如需获取,点击掘金量化终端顶部的“系统设置”即可。同时,也可以选择重新生成 token ID,此时旧的 token ID 将失效。
(3)filename:这个需要与第三方IDE设置的文件名相同,比如在pycharm中设置的文件名为test1.py,那么这里的main.py就需要改成test1.py。
获取数据
量化投资的第一步就是如何获取股市的数据。
交易标的:股票、期货、可转债、ETF、指数、基金
交易市场:上交所(SHSE)、深交所(SZSE)、中金所(CFFEX)、上期所(SHFE)、大商所(DCE)、郑商所(CZCE)、上海国际能源交易中心(INE),广期所(GFEX)
数据类型:实时行情数据、历史行情数据、基本面数据。
其中,实时行情数据和历史行情数据均包含 tick 行情、bar 行情。
基本面数据包含财务指标、指数成分、行业概念和交易日等数据。
我这里采用第三方IDE获取数据,数据仅返回一次。
# coding=utf-8
import gm.api as gm
import talib
import numpy as np
import pandas as pd
gm.set_token("自己的token码")
"""
1、set_token 设置用户token, 如果token不正确, 函数调用会抛出异常;
2、调用数据查询函数, 直接进行数据查询。
"""
data = gm.history_n(symbol="SZSE.002415",frequency="1d",count=100,end_time="2024-5-24",fields="close",fill_missing="last",adjust=gm.ADJUST_PREV,df=True)
close = np.asarray(data["close"].values)
data.to_csv("data.csv")
print(close)
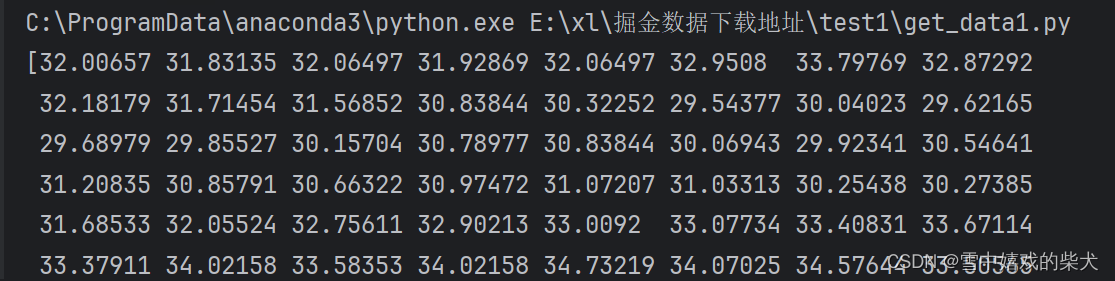
这里用到了gm.history_n()这个函数,目的是为了获取历史的N条数据,我上面的代码就是获取了海康威视仅100天的收盘价,并存储到excel中,同时打印出来。
返回值:
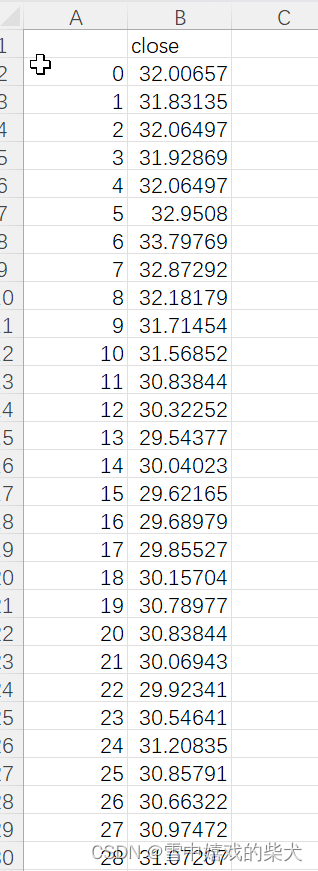
返回的CSV数据:
gm.history_n() 函数
history_n(symbol, frequency, count, end_time=None, fields=None, skip_suspended=True,
fill_missing=None, adjust=ADJUST_NONE, adjust_end_time='', df=False)
参数:
| 参数名 | 类型 | 说明 |
|---|---|---|
| symbol | str | 标的代码(只允许单个标的的代码字符串),如SZSE.002415代表深圳交易所上市的海康威视 |
| frequency | str | 频率,支持’tick’(交易所服务器刷新频率),‘1d’,‘60s’等,默认为’1d’。 |
| count | int | 数量(正整数) |
| end_time | str or datetime.datetime | 结束时间(%Y-%m-%d %H:%M:%S 格式),也支持datetime.datetime格式,默认None时,用了实际当前时间,非回测当前时间 |
| fields | str | 指定返回对象字段,如有多个字段,中间用,隔开,默认所有,如(open,high,low,price)等。 |
| skip_suspended | bool | 是否跳过停牌,默认跳过 |
| fill_missing | str or None | 填充方式,None——不填充;‘NaN’——用空值填充,‘Last’——用上一个填充,默认None |
| adjust | int | ADJUST_NONE or 0:不复权;ADJUST or 1:前复权;ADJUST_POST or 2:后复权 默认不复权 |
| adjust_end_time | str | 复权基点时间,默认当前时间 |
| df | bool | 是否返回dataframe格式(有时间戳),默认False,返回list[dict] |
注意:
- 返回的list/DataFrame是以参数eob/bob的升序来排序的
- 若输入无效标的代码,返回空列表/空DataFrame
- 若输入代码正确,但查询字段包含无效字段,返回的列表、DataFrame 只包含 eob、symbol和输入的其他有效字段
- end_time 中月,日,时,分,秒均可以只输入个位数,例:‘2017-7-30 20:0:20’,但若对应位置为零,则0不可被省略,如不可输入’2017-7-30 20: :20’
- skip_suspended 和 fill_missing 参数暂不支持
- 单次返回数据量最大返回 33000, 超出部分不返回
- end_time 输入不存在日期时,会报错 details = “Can’t parse string as time: 2020-10-40 15:30:00”
转载请注明出处:雪中嬉戏的柴犬

















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









