







Hadoop文档地址
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
设置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
增加后三行
IPADDR=192.168.32.128
GATEWAY=192.168.32.2
DNS1=192.168.32.2
然后重启网络:service network restart
设置主机名
临时设置主机名:
命令执行hostname bigdata01
永久设置主机名:
vim /etc/hostname 输入你想要设置的主机名
查看主机名命令:hostname
免密码登录设置
执行ssh-keygen -t rsa

然后
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
安装JDK
下载地址:
https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html
环境变量设置:
export JAVA_HOME=/home/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
Hadoop安装
下载地址:
https://archive.apache.org/dist/hadoop/common/
tar -zxvf /home/software/hadoop-3.2.0.tar.gz
配置Hadoop环境变量
export JAVA_HOME=/home/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export HADOOP_HOME=/home/software/hadoop-3.2.0
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin
export PATH=$PATH:${JAVA_PATH}
修改 hadoop-env.sh 文件
增加环境变量信息,添加到 hadoop-env.sh 文件末尾即可
export JAVA_HOME=/home/jdk1.8
export HADOOP_LOG_DIR=/home/hadoop_repo/logs/hadoop修改 core-site.xml 文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop_repo</value>
</property>
</configuration>
修改hdfs-site.xml文件
把hdfs中文件副本的数量设置为1,因为现在伪分布集群只有一个节点
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
修改mapred-site.xml
设置mapreduce使用的资源调度框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml
设置yarn上支持运行的服务和环境变量白名单
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASS</value>
</property>
</configuration>修改workers
设置集群中从节点的主机名信息,在这里就一台集群,所以就填写bigdata01即可
![]()
格式化HDFS
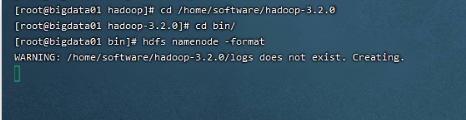
看到successfully formatted这条信息就说明格式化成功了

启动伪分布集群
使用sbin目录下的start-all.sh脚本,报错如下:

解决方式:
修改sbin目录下的 start-dfs.sh , stop-dfs.sh 这两个脚本文件,在文件前面增加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootHDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root[root@bigdata01 sbin]# vi start-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@bigdata01 sbin]# vi stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root然后在启动集群
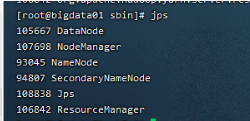
webui界面
通过webui界面来验证集群服务是否正常
HDFS webui界面:http://192.168.32.128:9870
YARN webui界面:http://192.168.32.128:8088















 1758
1758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









