







今天在做毕设的时候碰到一个问题:需要一种数据结构实现以下的这种结构(图片来自网络):
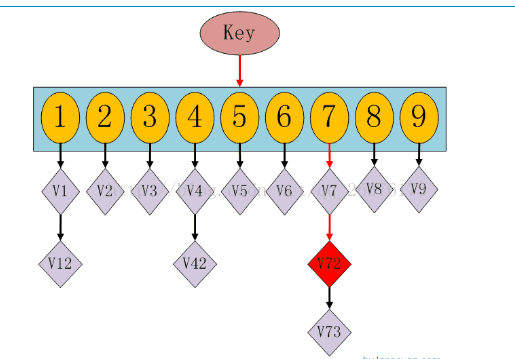
其实就是将n个元素按照某种规则进行hash,并挂在对应的key下面(key的范围是从0到2^22)
我第一反应就是使用python中的dict,结构为 {key:[<list>]}。但是简单的用如下的语句,很显然会报错KeyError:
t = dict()
t[0].append(<obj>)原因是现在我们的value是个list,而不再是一个单一值了,要是正常情况一个key对应一个value的情况下,是不会有KeyError的。
于是我当然想到了先将dict初始化,即先建立一个空字典,key从0~2^22,每个key对应的value为空列表 [],这样在将元素放入每个组的时候就不会出现任何问题了。
mask1 = 2**22
t1 = {v:[] for v in range(0,mask1)}似乎这个问题就这样解决了啊?没任何问题。确实如此,直到我发现,我本来就是想通过这种结构的存储来实现我的毕设算法的优化的,实际耗费时间却比优化前还慢上了整整几秒钟!!!!!!!要不是仔细排查代码,我才不会发现这个我以为类似于C语言中数组开空间一样的语句会那么耗时间!!!!!
问题就在于key的数目太多, 上面这句初始化能花整整2.9s!!!!其实上面这句有点类似于我在C语言中作了一个memset吧,但是其实我只想要声明出一片区域。
于是我开始想办法解决这个问题,最好能做到边放元素,边建立dict。在插入元素时碰到没有key的情况,也不会引起KeyError。所以有了下面的这个代码:
from collections import defaultdict
t1 = defaultdict(list)
t1[key].append(<obj>)这样默认了value是list的类型,就不会出现上面的KeyError错误了。而且没有用到的key也不会出现在字典里,不仅节省了空间,而且一开始建立字典花的时间是0。
注:上面的这种类似于map+链表的数据结构,不能用list嵌套实现。因为我在插入时,key的出现次序是不一定的,如果你非要用list嵌套,还是和上面一样的问题,得事先开出2^22个空list,一样很费时。
所以啊,在想理论的时候觉得一个东西很容易就实现了,实际动起手的时候,真的会碰到各种各样你会想不到的问题。有的问题还特别细枝末节。比如这里,一两句话的不同,造成程序的性能天差地别。所以多动动手还是好的,好多问题,都是在动手的时候,才会遇到,然后积累下来,成为了经验。















 8004
8004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









