










爬什么?爬代理服务器网站的服务器 端口 代理种类 所在地区 更新日期 今日评分 总的评分 可用 速度测评信息,这样的网页有七八个,好在网址明名很规则

具体说就是爬很多的这样的html代码里的信息
<span class="tbBottomLine" style="width:140px;">
58.222.254.11
</span>
<span class="tbBottomLine" style="width:50px;">
3128
</span>
<span class="tbBottomLine " style="width:70px;">
高匿
</span>
<span class="tbBottomLine " style="width:70px;">
中国
</span>
<span class="tbBottomLine " style="width:80px;">
09月05日
</span>
<span class="tbBottomLine " style="width:80px;">
3.44(70票)
</span>
<span class="tbBottomLine " style="width:60px;">
3.44
</span>
<span class="tbBottomLine " style="width:30px;">
14天
</span>- 怎么爬?利用python里的这个库urllib2,当然也要用正则,这里不得说我的正则好复杂(实在是想不到怎么简化)
import re
import urllib2
orgi=r'http://www.proxy360.cn/Region/'
proxywebs=['China','Brazil','America','Taiwan','Japan','Thailand','Vietnam','bahrein']
def get_Proxy_Info():
f=open('proxy.txt','w+')
p=re.compile("<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>[\s]*<span[^>]*>[\s]*(\S+?)[\s]*</span>")
'''
服务器 端口 代理种类 所在地区 更新日期 今日评分 总的评分 可用 速度测评 '''
for s in proxywebs:
target=orgi+s;
req=urllib2.urlopen(target)
mystr=req.read()
tmp=p.findall(mystr)
for t in tmp:
f.write('\t'.join(t))
f.write('\n')
f.flush()
f.close()
if __name__=="__main__":
get_Proxy_Info()原理,或流程
超简单,获取指定网页的源代码,返回类型是字符串,我们利用正则表达式匹配到我们想抓去的部分,利用分组进一步提取出来,然后保存或者之后的数据分析,显然这一步我没有做注意事项
网页的编码,一般是UTF8,万一不是呢?我写的时候,保存的时候乱码了,后来才知道要注意编码格式
正则的编写,这个考功底,其实也不然,你也可以很死的写,虽然我不推荐,但是我一开始只会这样写
<span class="tbBottomLine" style="width:140px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine" style="width:50px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:70px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:70px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:80px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:80px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:60px;">\r\n(.+?)\r\n</span>
<span class="tbBottomLine " style="width:30px;">\r\n(.+?)\r\n</span>很糟糕,但是能爬下来-_-#
- 结果
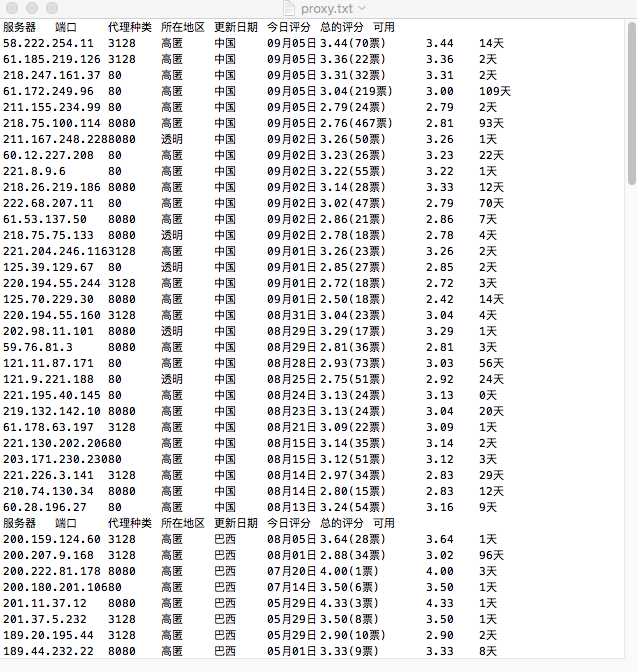
注:环境:python2.7 WingIDE















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









