






58面试一面
1、ArrayList和LinkedList的区别,是线程安全的吗?
2、什么是重载,返回值不同可以重载吗?
一个类中方法的参数的类型,参数的个数,参数的顺序都想同叫重载。
返回值不同不是重载(访问权限不同也不是重载)
3、Http300怎么处理,post,get,head的区别
客户请求的文档可以在多个位置找到,这些位置已经在返回的文档内列出。如果服务器要提出优先选择,则应该在Location应答头指明。
HEAD: 只请求页面的首部。
GET: 请求指定的页面信息,并返回实体主体。
POST: 请求服务器接受所指定的文档作为对所标识的URL的新的从属实体。
事实上 GET 适用于多数请求,而保留 POST 仅用于更新站点。
在FORM提交的时候,如果不指定Method,则默认为GET请 求,Form中提交的数据将会附加在url之后,以?分开与url分开。字母数字字符原样发送,但空格转换为“+“号,其它符号转换为%XX,其中XX为该符号以16进制表示的ASCII(或ISO Latin-1)值。GET请求请提交的数据放置在HTTP请求协议头中,而POST提交的数据则放在实体数据中;
GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
POST这个方法也是用来传送数据的,但是与GET不同的是,使用POST的时候,数据不是附在URI后面传递的,而是要做为独立的行来传递,此时还必须要发送一个Content_length标题,以标明数据长度,随后一个空白行,然后就是实际传送的数据。网页的表单通常是用POST来传送的。
4、tcp三次握手
客户端向服务器发送一个syn包,此时客户端处于syn_send状态,服务器在接到syn包后,发一个syn+ack包给客户端,此时,服务器端处于syn_rsv状态,客户端在收到服务器端的syn+ack包后,再发送一个ack包给服务器,然后三次握手完成,都处于establish状态。接着就可以发送数据了。
5、TCP滑动窗口
TCP协议作为一个可靠的面向流的传输协议,其可靠性和流量控制由滑动窗口协议保证,而拥塞控制则由控制窗口结合一系列的控制算法实现。
滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。
常用的方法就是:
1. 慢开始、拥塞控制
2. 快重传、快恢复
思路是这样的:
-1. 发送方维持一个叫做“拥塞窗口”的变量,该变量和接收端口共同决定了发送者的发送窗口;
-2. 当主机开始发送数据时,避免一下子将大量字节注入到网络,造成或者增加拥塞,选择发送一个1字节的试探报文;
-3. 当收到第一个字节的数据的确认后,就发送2个字节的报文;
-4. 若再次收到2个字节的确认,则发送4个字节,依次递增2的指数级;
-5. 最后会达到一个提前预设的“慢开始门限”,比如24,即一次发送了24个分组,此时遵循下面的条件判定:
*1. cwnd < ssthresh, 继续使用慢开始算法;
*2. cwnd > ssthresh,停止使用慢开始算法,改用拥塞避免算法;
*3. cwnd = ssthresh,既可以使用慢开始算法,也可以使用拥塞避免算法;
-6. 所谓拥塞避免算法就是:每经过一个往返时间RTT就把发送方的拥塞窗口+1,即让拥塞窗口缓慢地增大,按照线性规律增长;
-7. 当出现网络拥塞,比如丢包时,将慢开始门限设为原先的一半,然后将cwnd设为1,执行慢开始算法(较低的起点,指数级增长);
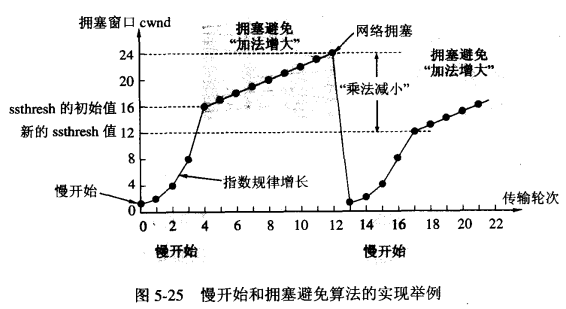
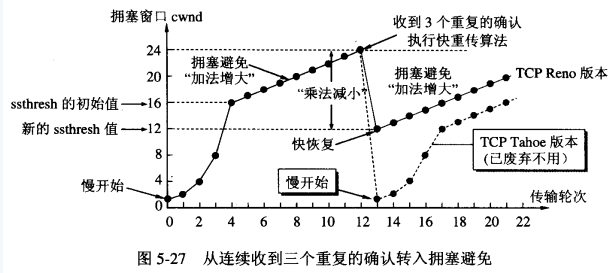
上述方法的目的是在拥塞发生时循序减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够的时间把队列中积压的分组处理完毕。慢开始和拥塞控制算法常常作为一个整体使用,而快重传和快恢复则是为了减少因为拥塞导致的数据包丢失带来的重传时间,从而避免传递无用的数据到网络。快重传的机制是:
1. 接收方建立这样的机制,如果一个包丢失,则对后续的包继续发送针对该包的重传请求;
-2. 一旦发送方接收到三个一样的确认,就知道该包之后出现了错误,立刻重传该包;
-3. 此时发送方开始执行“快恢复”算法:
*1. 慢开始门限减半;
*2. cwnd设为慢开始门限减半后的数值;
*3. 执行拥塞避免算法(高起点,线性增长)
6、红黑树
红黑树是基于二叉平衡树的。它上面只有红节点和黑节点,红节点的子节点一定是黑节点。红黑树的叶子节点都是黑节点。
7、堆和栈的区别(都说)
1)从jvm上说,栈分为虚拟机栈和本地方法栈,虚拟机栈是为虚拟机执行Java方法(字节码)服务的中存放的是局部变量表,操作数栈,动态链接,方法出口等信息,它的生命周期和线程的生命周期一样,它是线程私有的,而本地方法栈是为虚拟机中使用到的native方法服务的,堆是Java虚拟机所管理的内存中最大的一块,是被所有线程所共享的内存区域,唯一的目的是存放对象实例,堆也是垃圾收集器管理的主要区域。
2)从数据结构上说,堆是基于树形数据结构的,栈则是基于顺序表结构的,栈对数据的操作只能是对栈顶的数据进行插入和删除操作,堆对数据的操作和树中节点的操作相似。
8、Tcp如何保证可靠传输
主机每次发送数据时,TCP就给每个数据包分配一个序列号并且在一个特定的时间内等待接收主机对分配的这个序列号进行确认,如果发送主机在一个特定时间内没有收到接收主机的确认,则发送主机会重传此数据包。接收主机利用序列号对接收的数据进行确认,以便检测对方发送的数据是否有丢失或者乱序等,接收主机一旦收到已经顺序化的数据,它就将这些数据按正确的顺序重组成数据流并传递到高层进行处理。
具体步骤如下:
(1)为了保证数据包的可靠传递,发送方必须把已发送的数据包保留在缓冲区; (2)并为每个已发送的数据包启动一个超时定时器; (3)如在定时器超时之前收到了对方发来的应答信息(可能是对本包的应答,也可以是对本包后续包的应答),则释放该数据包占用的缓冲区; (4)否则,重传该数据包,直到收到应答或重传次数超过规定的最大次数为止。(5)接收方收到数据包后,先进行CRC校验,如果正确则把数据交给上层协议,然后给发送方发送一个累计应答包,表明该数据已收到,如果接收方正好也有数据要发给发送方,应答包也可方在数据包中捎带过去。
9、线程的创建和状态
线程可以通过1)继承thread类创建
2)实现runnable接口创建
3)实现callable接口创建,与runnable区别是有返回值
线程的状态:就绪状态,运行状态,阻塞状态
10、项目中的一个算法
11、排序算法,快排
冒泡排序、归并排序、基数排序和插入排序是稳定排序
选择排序、堆排序、希尔排序、快速排序是不稳定的排序
冒泡、选择、插入排序的平均时间复杂度,最好情况,最坏情况都为O(n^2)
堆排序、归并、快排平均时间复杂度为,最好(坏)时间复杂度为O(nlogn),只除了快排最坏是 O(n^2)。
12、数据库中的查找
select * from a left join b on a.id= b.id
select * from a left join (select * from b) c on a.id =c.id
这两个的区别
select id from a group by name
报错,为什么报错,
group by的字段应该和select的字段名一样
13、线程的阻塞队列
14、常用的索引
主键索引,唯一索引,聚集索引,非聚集索引
15、B+树















 3992
3992











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









