







cs231n课程源网页 点击打开链接
记录一下看教程过程中的自己的一些想法(顺便吐槽一下这个编辑器写公式好像有点疼,以后考虑用markdown),仅写一下一些自认为较为难理解的部分,跳过了很多较简单的内容......
图片分类任务主要分为两个过程,首先得到一个得分方程,即将一张图片利用一些函数(Linear、MLP或者神经网络都是在做这个事)得出其对所有类别的得分,而要怎么评价一个这样的函数的好坏以便我们改进我们的模型,则需要定义一个损失函数(loss function),这也有很多方式,例如利用Softmax将所有分数归一化,转化为一个概率,或者利用SVM计算真实标记与计算类别之间的差值,这里较简单,可以看cs231n的前一节......
如何最优化我们建立的模型这就是优化的问题,例如在Linear model中找到最优的W,使得loss最小。
由于W维度较高,要使loss function可视化,可以通过固定W的某些维度进行,这个与二维空间其实类似,例如在二维空间中有一点Wi(xi, yi),通过计算L(W+aWi)的值与a的关系,就可以获取L在Wi轴上的变化情况。在二维空间中就相当于在由(0, 0)与(xi, yi)决定的直线l 上L的变化情况,加上其他维度类似这一过程(二维平面,三维空间......),所以利用loss function L(W + aW1 + bW2),就可以通过a与b的变化得到不同的loss值,便可以可视化loss function在W1和W2组成的平面上的变化情况。
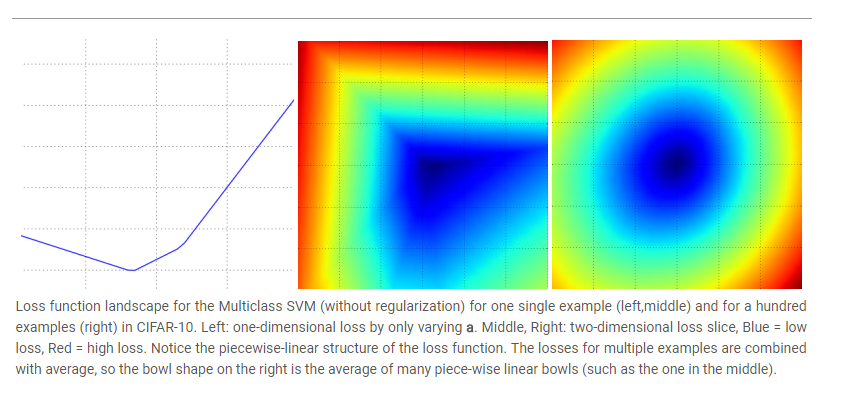
图引自cs231n课程网站, 第一幅图是只使用一个W1得到的。
optimization有三种方法,随机搜索(每次使用新的W以及加入一个δW)以及梯度下降方法,前两种比较简单
在计算梯度的方法中,有两种方式计算梯度,数值梯度(numerical gradient)和解析梯度(analytic gradient)
数值梯度(numerical gradient)
课程网页上面写了一种比较simple、naive的方式,其实也就是对每个维度,加上一个较小的数,求函数值,然后利用导数的定义近似计算,即利用下式计算
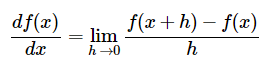
这种方法计算较为精确,但是如果x的维度(a)特别特别大的话每次计算梯度就要花费大量的时间(o(a)时间复杂度)......
代码如下所示:
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient at
"""
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) # 对x的所有元素进行迭代
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad在实际中使用|f(x+h)-f(x-h)|/2h更多一些,利用计算的梯度可以进行W的更新,W = W - step_size * df,这里使用负方向,表示沿loss变小的方向,这里的step_size就是神经网络中常用的一个超参,这个步长对训练影响很大。步长太大可能导致无法收敛,步长太小则速度太慢。
解析梯度(analytic gradient)
其实也就是数学上的求导数(多变量求偏导),然后可以直接代入得到一个点的梯度值,但是这种方式容易出错,所以就引入了梯度检查(gradient check)来对比解析梯度和数值梯度的值。
例如SVM的loss function如下:
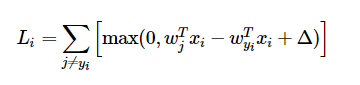
其对wyi的偏导数为:
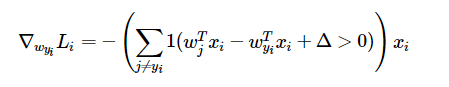
其实很好理解,L是由多个max函数组成,而每个max函数是一个hinge函数,max()函数的后部分对于某一个w而言,就是一个线性关系,即wj * xi - wyi * xi + delta = wyi * a + b, wyi为变量,a和b是参数,所以其导数在后面一项小于0时是0,在其大于零时导数为a(也即是xi)
对于j不等于yi的情况,wj的偏导数是:
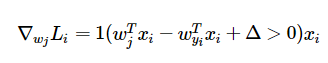
梯度下降(Gradient Descent)
梯度下降就是各种NN中使用较多的优化器了,也就是沿负梯度方向使loss值减小,代码如下:
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # perform parameter update














 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









