






scala的main目录下新建scala class
package main
import java.text.SimpleDateFormat
import java.util.Calendar
import com.alibaba.fastjson.{JSON, TypeReference}
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import utils.{PropertyUtil, RedisUtil}
import scala.collection.JavaConverters._
object SparkConsumer {
def main(args: Array[String]): Unit = {
// 1 初始化sparkConf
// import org.apache.spark.SparkConf
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("TrafficStreaming")
// 2 初始化SparkContext
// import org.apache.spark.SparkContext
val sc = new SparkContext(sparkConf)
// 3 初始化SparkStreamingContext
// import org.apache.spark.streaming.Seconds
val ssc = new StreamingContext(sc, Seconds(5))
// 4 启用 checkpoint,需要设置一个支持容错的、可靠的文件系统(如 HDFS、s3 等)目录来保存 checkpoint 数据。
ssc.checkpoint("./ssc/checkpoint")
// 5 配置kafka参数apply
// import utils.PropertyUtil
val kafkaParams = Map("metadata.broker.list" -> PropertyUtil.getProperty("metadata.broker.list"))
// 6 配置主题
val topics = Set(PropertyUtil.getProperty("kafka.topics"))
// 7 读取kafka中的value数据
// import org.apache.spark.streaming.kafka.KafkaUtils
val kafkaLineDStream = KafkaUtils.createDirectStream[
String,
String,
// import kafka.serializer.StringDecoder
StringDecoder,
StringDecoder](ssc, kafkaParams, topics)
.map(_._2)
// 8 解析读取到的数据
val event = kafkaLineDStream.map(line => {
// 9 JSON解析
// import com.alibaba.fastjson.JSON
// import com.alibaba.fastjson.TypeReference
val lineJavaMap = JSON.parseObject(line, new TypeReference[java.util.Map[String, String]]() {})
// 10 将JavaMap转为ScalaMap
// import scala.collection.JavaConverters._(手动导入,mapAsScalaMapConverter需要)
val lineScalaMap: collection.mutable.Map[String, String] = mapAsScalaMapConverter(lineJavaMap).asScala
// 11 打印lineScalaMap
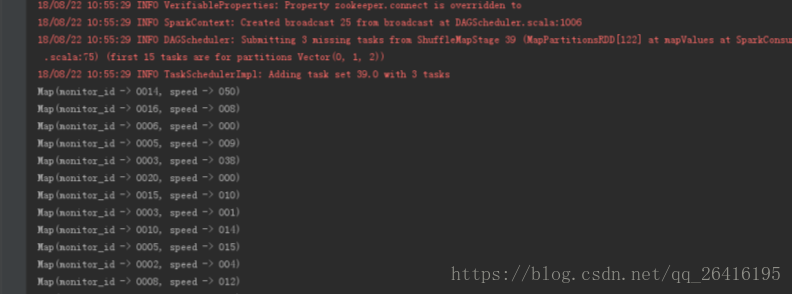
println(lineScalaMap)
// 12 返回值
lineScalaMap
})
// 13 将数据进行简单聚合:tuple
// 目前数据格式:{"monitor_id":"0001","speed":"50"}
// 目标:(0001,(500,10))(元祖的嵌套)
// (monitor_id,(sumOfSpeed,Count))
// event scala集合
val sumOfSpeedAndCount = event
// map函数将集合中的每一个元素映射到后面的函数
// map.get("key")返回some集合
// map.get("key").get返回value
// ("0001", "50")
// (monitor_id,Speed)
.map(e => (e.get("monitor_id").get, e.get("speed").get))
// (monitor_id,(Speed,1))
// ("0001", (50,1))
.mapValues(v => (v.toInt, 1))
// (monitor_id,(sumOfSpeed,Count))
// ("0001", (500,10))
.reduceByKeyAndWindow((t1: (Int, Int), t2: (Int, Int)) => (t1._1 + t2._1, t1._2 + t2._2), Seconds(20), Seconds(10))
// 14 将处理好的数据存放于redis中
val dbIndex = 1
// 15 数据处理
sumOfSpeedAndCount.foreachRDD(rdd => {
rdd.foreachPartition(partitionRecord => {
// 过滤数据
partitionRecord
// 删除车辆数小于等于0情况
.filter((tuple: (String, (Int, Int))) => tuple._2._2 > 0)
.foreach(pair => {
// 获取redis链接
// import utils.RedisUtil
val jedis = RedisUtil.pool.getResource
// monitor_id
val monitorID = pair._1
// sumOfSpeed
val sumOfSpeed = pair._2._1
// Count
val sumOfCarCount = pair._2._2
// 将数据实时保存到redis中
// import java.util.Calendar
val currentTime = Calendar.getInstance().getTime
// HHmm
// import java.text.SimpleDateFormat
val hmSDF = new SimpleDateFormat("HHmm")
// yyyyMMdd
val dateSDF = new SimpleDateFormat("yyyyMMdd")
// 对时间进行格式化操作
// 2035
val hourMinuteTime = hmSDF.format(currentTime)
// 20091112
val date = dateSDF.format(currentTime)
jedis.select(dbIndex)
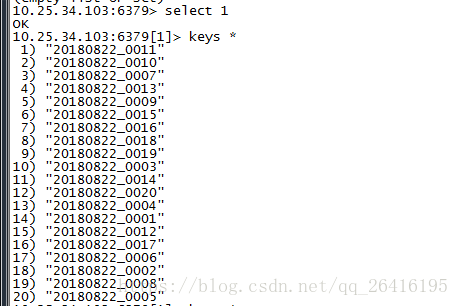
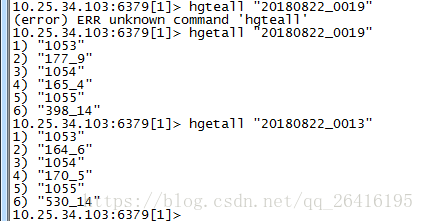
// key ---> 20091112_0001
// firlds ---> 2035
// value ---> 500_10
jedis.hset(date + "_" + monitorID, hourMinuteTime, sumOfSpeed + "_" + sumOfCarCount)
RedisUtil.pool.returnResource(jedis)
// 与上句等价jedis.close()
})
})
})
// 16 启动SparkStreaming
ssc.start
ssc.awaitTermination
}
}
启动redis
redis的src目录下执行
redis-server ../redis.conf 
启动producer
启动SparkConsumer














 5082
5082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









