







请注意:
-
如果你想看完这篇文章之后,此后的八股背诵之路就如同开挂一般,变得轻松+愉快+记忆牢固,那你可以直接把这个页面关掉了。
-
相反,如果你想用短暂的痛苦,换来思维方式的改变,进而让你对八股的记忆更加牢固和准确,那么可以接着往下看!
先看看大多数人背书的几个误区
1.逐字逐句背诵
想象这样一个场景:小六同学刚学完涤生大数据的Spark课程,准备复习一下八股然后找老师答辩。打开Wiki的八股页面,第一个问题是:Spark的特点。
具体八股长这样:

小六同学背诵到第3条通用性的时候,卡了半天,因为小六同学认为只有一字不差地背诵下来才算真正掌握。
但是小六同学总是把交互式查询(Spark SQL)、实时流处理(SparkStreaming)、机器学习(Spark MLlib)和图计算(Graphx)的顺序背错,并且图计算(Graphx)中的Graphx总是读错且不会拼,为此浪费了半个小时的时间。
然后死磕了1个小时之后,还是没有背过这个问题,于是决定今天先暂时放弃,明天再说...
我的评价是:同学你这是在背古诗吗?古诗起码也是押韵的把!
2.缺乏理解和思考
还是以上面这个八股和场景为例,小六同学虽
然把前两个特点(快 + 易用)背过了,但是第二天来复习的时候,发现啥也不记得了,因为他第一天是这样背的:
-
快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上..........
-
快:与Hadoop的MapReduce相比,Spark基于内存的运算要快100倍以上..........
然后小六同学重复了10遍之后,终于记下来了,然后开始去背诵易用是啥,继续重复10遍....
我的评价是:小六同学看似很努力的在背诵八股,重复了好多遍,但其实大脑都没咋思考这个问题的答案为啥是这样?我能理解这个答案吗?这个答案和哪些知识点有关系?
3.缺乏背诵计划
凡事预则立,不预则废。
对于校招同学来说,准备的越早,路径规划的越清晰越合理,上岸的概率也越大,机会总是先到先得。准备的早,就是”预“,当然,只是准备的早还不够,还需要有清晰正确的路径规划,当然这一点可以放心的交给涤生大数据。
而对于八股背诵,也是一样。
制定合理正确的背诵计划,每天坚持完成,效果总是比每天抽时间继续接着昨天的背,要强的多!当然,还需要根据自己的实际情况和进度调整计划,保持背诵的连续性和稳定性。
4.缺乏背诵效果的反馈和评估
很多同学在背诵八股的时候,会出现这样一个情况:明明已经花了很多时间去背诵八股了,但是之前背过的问题在面试中总是回答不好,这其实就是缺乏对自己背诵效果评估的一个机制。
试想一下,如果没有一次次的考试,怎么能精准找出自己的知识盲区并攻克他们呢?考试其实就是一种对于学习效果的反馈和评估机制。
其实背诵八股,也是一样的道理,我们也需要建立一套合理且有效的对自己背诵效果的评估机制,进而找到自己相对薄弱的地方去重点攻克。
认识一下 “思考密度”
在讲述如何背诵八股之前,不如咱们先聊聊,什么是“思考密度”,带你打破认知误区。
举个非常简单的例子:
-
一个关于小文件治理参数的八股,照着答案读10遍,思考密度就是0
-
盖住答案,尝试独立去背诵小文件治理相关的参数,思考密度是1.
-
闭上眼睛,不断追问自己:我们为什么要关注小文件呢?小文件危害有哪些?哪些最严重?为什么这一种是影响最大的?有哪些处理手段呢?这些处理手段哪些是最推荐的?为什么?思考密度就是6!
所以,思考密度指的是在一定的时间和思考范围内,所包含的有效思考内容的多少。它可以体现一个人思考的细致程度、深入程度以及思维的活跃度。简单来说,思考密度的口径就是:提问的数量 / 知识点的数量。
很多同学平时无论是看课程,还是看相关的PDF,都只是通读一遍,追求速通,但是全程几乎没有任何思考【例如:想想当前学的知识点属于整个课程体系中的哪部分?这部分知识点相关的应用场景是啥?是面试容易问的还是工作常用的?】,这种情况下的思考密度几乎为0!表面上大家都是在看课程,有些同学硬是只看了2个小时,而有些学习习惯好的同学则会在看课程的同时去联想记忆,比如当前这部分知识点是在讲啥?之前讲的啥?哪部分我要重点关注?不仅仅是听课,看课程PDF文档、背诵八股等等都是一个道理。
当然,在背诵八股的时候,重复提问自己这么多问题对大脑来说确实是很痛苦的,远远不如直接背完就结束的体验友好。
但这背后有两个核心的记忆原理:
-
大脑越痛苦,记忆效果越好
-
这涉及到一些脑科学原理,具体细节就不展开了,总而言之,让背八股真正是在”背“,而不是看八股、听八股、读八股,要让自己的大脑”痛哭起来“,才能形成有效的记忆。
-
记住的东西越多,记忆速度越快
-
这句话就比较抽象了,啥叫”记住的东西越多,记忆速度越快“呢?
-
举个例子你就明白了:还是上面那个小文件治理参数的八股,如果你只是把小文件治理的参数背诵下来了,你就只是背诵下来了这一个知识点,它就像是游离在你大脑里的小碎片,说不定哪天就被完全忘记了。但是你在看这个问题的时候,能够同时想到:我们为什么要关注小文件呢?小文件危害有哪些?哪些最严重?为什么这一种是影响最大的?有哪些处理手段呢?这些处理手段哪些是最推荐的?为什么?参数调优还有哪些方法?性能调优除了参数调优,还有其他手段吗?除了代码调优和参数调优,还有没有其他去优化任务执行时间的方案?
-
那么这个小小的小文件治理参数的八股,就被你大脑中庞大的知识点网络给捕获了。当这个小知识点融入你大脑中庞大的知识网络时,就如同为精密的机械装置添上了关键的零件,使其运转更加流畅,结构愈发稳固。此后,知识网络里任意一个小节点被触发,都会牵一发而动全身,带动整个网络产生连锁反应,让你对知识网络的记忆深度在一次次的触动中不断强化,最终达到无懈可击的境地。
-
按照这种方式,你背诵八股的过程就像是一个指数级的加速循环:思考密度越高 => 连接的知识点就越广 => 你记住的内容就越多 => 新的知识就越容易发生关联 => 思考密度就越高 => up!
-
-
八股背诵 “独家秘籍”
1.巧用图片和口诀,让知识点“生动化”
很多八股整体的内容还是非常多的,想要记住并且背过八股本身都并非易事,更别说去串联其他知识点了。这个时候,我们就需要一些技巧来帮助我们”攻破“这种长难八股。
例如:请列举Spark中的行动算子,并简述其功能。
要知道,整个Spark中的行动算子是非常多的,并且需要全部记住很难,如果硬去记的话,需要花费非常多的时间不说,且非常容易遗忘。而且,记忆的习惯往往会决定回答问题的逻辑性。如果你记忆问题时就是按照顺序一个算子一个算子往脑子里进,那么回答这个问题时大概率也会一个词一个词的往外蹦,这样的回答方式会让你的回答很没有逻辑性,而且大概率会让你回答问题时出现非常多的”废话连接词“,比如”嗯...“,"然后嗯...",也会影响面试官对你的最终评价。
所以!我们在记忆这种”罗列类“的八股时,可以尽量用口诀和图片来辅助记忆,将整个知识点封装起来。这样,如果在面试中如果遇到对应的问题时,第一时间想到的是你封装好的图片和口诀整体,而不是一个一个零碎的算子。然后,根据图片或者口诀去慢慢说出整个八股的所有内容。
下面,是两种完全不同的背诵方式最终影响面试时第一直觉想到的回答的直观展示:
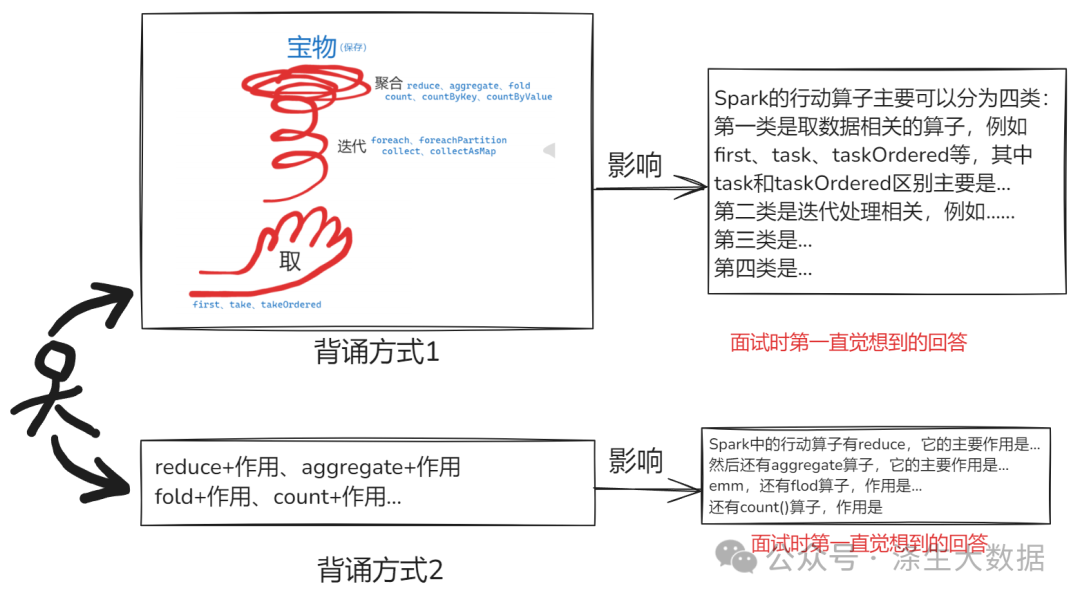
其中,背诵方式1就是用一张有趣的图片将整个Spark中的行动算子进行了封装,将其封装成一张图片。而且这张图片是可以想象的场景的,也非常容易记住:
想象一下,一个法师在施展魔法,魔法从手中呈丝缕状徐徐上升,不断【迭代】盘旋上升,上升到一定高度时,会慢慢【聚合】到一起,最终形成一件魔法【宝物】。
我这里甚至可以用大模型来生成上述场景(忽略这个人有六根手指头):

那么问题来了,有了一个有趣的场景,怎么和知识点映射呢?也非常简单:
从图片的最下面往上想象,获取图片的元素:
-
张开手 => 取东西的感觉 => 获取RDD的数据元素 => first、task、takeOrdered算子
-
魔法不断【迭代】盘旋上升 => 进行迭代判断的RDD算子 => foreach、foreachPartition、collect、collectAsMap
-
魔法慢慢【聚合】到一起 => 进行数据聚合类的RDD算子 => reduce、aggregate、fold、count、countByKey、countByValue
-
获取到宝物 => 近义词【宝】=【保】=【save(保存)】 => 保存数据相关的RDD算子 => SaveAsXXX相关的算子
我相信当你按照这种方式记忆完之后,肯定很难忘记,而且面试中如果真遇到这个问题,脑海中很快就能想到你自己构造的场景图片,回答问题也会很有逻辑性:
Spark的行动算子主要可以分为四类:
-
第一类是取数据相关的算子,例如frst、task、taskOrdered等,其中task和taskOrdered区别主要是..
-
第二类是迭代处理相关,例如.…
-
第三类是...
-
第四类是...
后续每次复习时,只需要把这张图片重新回忆一下,复习效率也非常高。重点就在第一次记忆时,确实需要好好思考怎么样记忆这个知识点比较好,怎么样构造具体的场景呢?真正让大脑燃烧起来,这就是前面所提到的:大脑越痛苦,记忆效果越好。
2.善用思维导图,让碎片知识点”网状化“
前面讲的巧用图片和口诀,让知识点“生动化”的内容,主要是针对一些“长难八股”或者”罗列类八股“而言的,更偏向于对单个八股知识点进行背诵和记忆。
但很多八股之间都是有关联的,就像前面介绍思考密度时所提到的:记住的东西越多,记忆速度越快。那么面对那么多的知识点,如何保证记忆更多东西的同时,相关知识点分类明确,便于检索和记忆呢?答案就是借助思维导图等工具,帮助记忆。
大脑具有强大的联想能力,思维导图通过将知识点以图形、线条和关键词的形式相互连接,模拟了大脑的联想思维过程。例如,当我们看到 “水果” 这个中心主题时,思维导图中与 “水果” 相连的分支可能会有 “苹果”“香蕉”“橙子” 等,每个分支还可以继续延伸出关于它们的颜色、口感、营养成分等细节。这种关联方式能够激发大脑的联想,让我们在记忆一个知识点时,能够自然地联想到与之相关的其他知识点,形成知识网络,从而提高记忆的效率和容量。这和我们想要在记忆问题时提高思考密度的想法如出一辙,完美契合!
另外,当你尝试用思维导图将知识点梳理贯穿到一起的过程,思考密度是极高的,这个整理梳理的过程,甚至比思维导图本身还要重要!
而且,当你整理完思维导图时,后续复习起来也非常方便,只需要对着思维导图去联想知识点,忘记的时候再去回顾相关的细枝末节即可,复习效率会大大提升。
3.尝试过度思考+冗余背诵
什么是过度思考?什么是冗余背诵?其实两者想表达的思想都是一致的:在背诵某个知识点时,尽量把这个知识点相关的知识点都拿出来背诵一遍(哪怕是读一遍,脑海中理解一遍也好,不会花费太多时间),因为记住的东西越多,记忆速度越快。
还是以小文件参数治理这个知识点为例:
如果你只是把小文件治理的参数背诵下来了,你就只是背诵下来了这一个知识点,它就像是游离在你大脑里的小碎片,说不定哪天就被完全忘记了。
但是你在看这个问题的时候,能够同时想到:我们为什么要关注小文件呢?小文件危害有哪些?哪些最严重?为什么这一种是影响最大的?有哪些处理手段呢?这些处理手段哪些是最推荐的?为什么?参数调优还有哪些方法?性能调优除了参数调优,还有其他手段吗?除了代码调优和参数调优,还有没有其他去优化任务执行时间的方案?
那么这个小小的小文件治理参数的八股,就被你大脑中庞大的知识点网络给捕获了。当这个小知识点融入你大脑中庞大的知识网络时,就如同为精密的机械装置添上了关键的零件,使其运转更加流畅,结构愈发稳固。此后,知识网络里任意一个小节点被触发,都会牵一发而动全身,带动整个网络产生连锁反应,让你对知识网络的记忆深度在一次次的触动中不断强化,最终达到无懈可击的境地。
4.制定合理的背诵计划
有目标,才有行动的动力。
背诵计划,不仅仅指计划好要背诵什么东西,还指计划好要复习哪些东西。
建议按照周为单位,来设置一个总的目标,然后每天晚上去制定明天需要背诵哪些东西。
比如:下周需要完成整个Spark的背诵任务。然后每天晚上去制定一下明日整体的背诵计划,包括什么时间段去背诵,背诵哪些知识点等等。这样做的好处在于可以灵活应对一些突发情况,时间上也更自由一些,避免因为计划制定过早而完不成给自己带来“挫败感”。
合理分配时间:合理的背诵计划能够根据知识点的难易程度和重要性,将背诵任务分配到不同的时间段,避免时间安排的盲目性和随意性。例如,对于较难的知识点,可以安排在大脑清醒、注意力集中的时间段进行背诵;对于相对简单的知识点,可以利用碎片化时间进行巩固。这样可以充分利用时间,提高单位时间内的背诵效率。
避免过度疲劳:如果没有计划,可能会出现长时间连续背诵的情况,导致大脑疲劳,记忆效果下降。合理的背诵计划会设置适当的休息时间,让大脑有足够的时间恢复精力,从而保持良好的学习状态。比如,每背诵 40-50 分钟,安排 10-15 分钟的休息时间,这样可以有效缓解大脑的疲劳,提高后续的背诵效率。
5.制定对背诵效果的自查反馈机制
一个非常简单有效的方式就是:
-
把某个模块下所有的八股问题都整理好,注意是只整理问题,不要答案。
-
然后打开手机录音,假装现在你就是在面试,你整理的一个个问题就是面试官问你的问题,现在要求你回答。录音的目的是为了给你一种自己说的每一句话都被别人听着的感觉。
-
不要看任何资料,试试能不能独立的把所有的八股问题都回答上来呢?
-
全部问题都模拟回答完毕之后,我想你应该就知道自己哪里需要补充学习了把!注意,不要遇到想不起来的问题就终止模拟面试,而是硬着头皮说下去,硬着头皮背下去,锻炼一下遇到不会问题临场发挥的能力。
在每次评估后,对自查结果进行综合分析,计算自己在不同类型知识点上的正确率,统计错误出现的频率和类型,如哪些内容总是容易忘记,哪些部分经常出现理解错误等,从而了解自己的学习状况和薄弱环节。


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











