






当我们用Flume采集日志时,由于数据源的多样性,则往往需要配置多个Flume进行采集,如果只是使用单层Flume的话,那么往往会产生很多个文件夹,单个文件夹也只是来自同一个节点的数据组成的。而实际开发中,为了减少HDFS的压力,同时提高后续MR的处理效率。往往会将同一组多个节点的数据汇聚到同一个文件中,这样同时也较少了数据从生产到分析的时间。
如下图,第一次agent负责采集原始数据,第二层agent负责对第一层数据进行汇聚。这种多层代理的方式尤其适合source源数据量庞大的时候,效率会高很多。
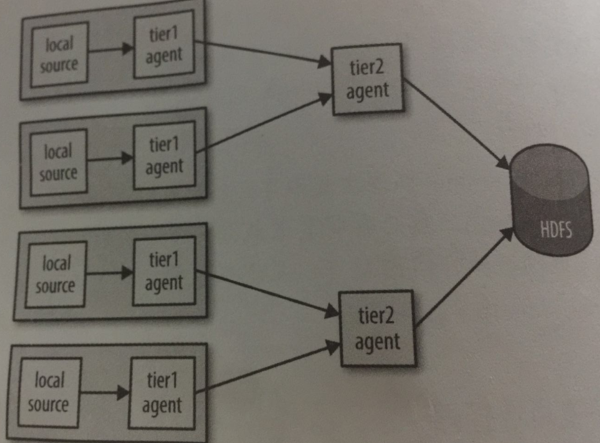
注意:1.如果要构建分层的代理结构,必然牵扯到数据的网络传输和分发问题。所以第一层代理需要某种特殊的sink来进行网络发送事件,再加上相应的source来接受这些事件。Avro sink 通过Avro RPC将事件发送给运行在另一个Flume代理上的其他Avro。事实上Avro的sink和source不提供写入和读取Avro文件的能力,它们仅用于代理层是事件分发,并且为了做到这一点,它们需要通过Avro RPC来进行通信。这里要区别Avro文件,如果想将事件写入到Avro文件,则可以使用HDFS sink实现。
2.如果第二层的agent停止运行,那么事件将被保存到第一层agent的channel中,等到第二层agent的重新启动。但是channel的存储是由限制的,如果第一层agent的channel已经填满数据时,第二层agent还没启动恢复运行,那么任何新采集的事件都会丢失。默认情况下,file channel能够恢复的事件数量不超过100万条(可以通过capacity属性来设置,实际要设置的大一些),此外,当检查点checkpointdir的可用磁盘空间小于500M时(minimumRequiredSpace属性设置),也将停止接收事件,造成新事件的丢失。
3.不管第一层某个代理还是第二层某个代理一旦有停止运行或者失败的情况出现,都会出现Flume丢失数据的情况发生。这也是常见开发中,或者面试中常问的Flume数据丢失问题,如果防止丢失?对于这个问题如果是第一层某个代理失败,那么可以考虑由第一层的其他节点来接管故障节点。如果是第二层代理停止运行,则为了防止数据丢失,只能让每一个第一层代理具有多个冗余的Avro sink,然后把这些sink安排到同一个sink组中,如果第二层代理中的某个代理出现问题,则该事件会被传递给该层sink组的其他代理来完成,以此来实现故障转移和负载均衡。下面博客继续sink组的实现。
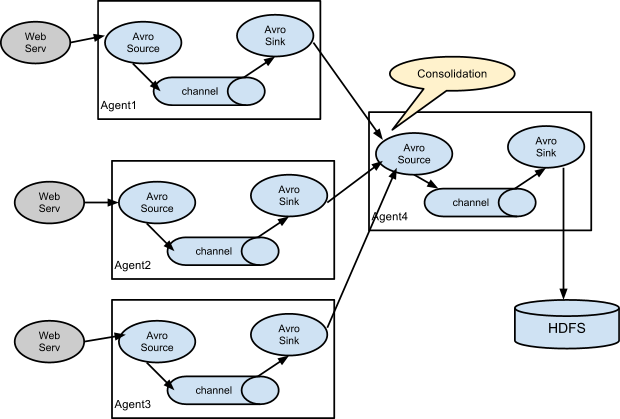
案例演示多层代理的实现:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











