







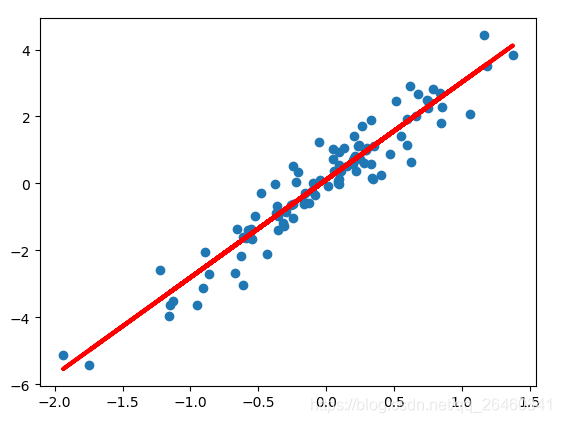
简单的讲,有一堆数据,需要简单的拟合出一条直线,如:
我们知道其表达式是:
y
=
w
x
+
b
y=wx+b
y=wx+b
那么,我们根据损失函数的思路,可以很容易得出其损失函数:
L
o
s
s
=
1
2
m
∑
i
=
0
N
(
y
^
−
y
)
2
=
1
2
m
∑
i
=
0
N
(
w
x
+
b
−
y
)
2
\begin{aligned} Loss & = \frac{1}{2m}\sum_{i=0}^{N}(\widehat{y} - y)^2 \\ &= \frac{1}{2m}\sum_{i=0}^{N}(wx+b - y)^2 \end{aligned}
Loss=2m1i=0∑N(y
−y)2=2m1i=0∑N(wx+b−y)2
我们知道,在求的最后的解的时候,对于这个简单的式子,可以通过求导,然后直接令其导数为0来得到最后的w和b的值。这里为了方便,就直接只计算一项,即:
l
o
s
s
=
1
2
(
w
x
+
b
−
y
)
2
=
1
2
(
y
2
+
(
w
x
+
b
)
2
−
2
y
(
w
x
+
b
)
)
=
1
2
(
y
2
+
w
2
x
2
+
b
2
+
2
w
b
x
−
2
y
w
x
−
2
y
b
)
\begin{aligned} loss &= \frac{1}{2}(wx+b-y)^2 \\ &= \frac{1}{2}(y^2+(wx+b)^2-2y(wx+b)) \\ &= \frac{1}{2}(y^2+w^2x^2+b^2+2wbx-2ywx-2yb) \end{aligned}
loss=21(wx+b−y)2=21(y2+(wx+b)2−2y(wx+b))=21(y2+w2x2+b2+2wbx−2ywx−2yb)
那么,可以求的最后的目标w和b的值:
∂
l
∂
w
=
1
2
(
2
w
x
2
+
2
b
x
−
2
y
x
)
∂
l
∂
b
=
1
2
(
2
w
x
+
2
b
−
2
y
)
\begin{aligned} &\frac{\partial{l}}{\partial{w}} = \frac{1}{2}(2wx^2+2bx-2yx) \\\\ &\frac{\partial{l}}{\partial{b}} = \frac{1}{2}(2wx+2b-2y) \end{aligned}
∂w∂l=21(2wx2+2bx−2yx)∂b∂l=21(2wx+2b−2y)
不难看出,其实这样是计算不出来的,所以我们只能通过这个来得到一个递减的大致趋势,也即是w和b的更新:
w
:
=
w
0
+
α
∂
l
∂
w
b
:
=
b
0
+
α
∂
l
∂
b
\begin{aligned} &w := w_0 + \alpha \frac{\partial{l}}{\partial{w}} \\ &b := b_0 + \alpha \frac{\partial{l}}{\partial{b}} \end{aligned}
w:=w0+α∂w∂lb:=b0+α∂b∂l
代码如下:
import numpy as np
import math
import tqdm
import matplotlib.pyplot as plt
"""
拟合y = ax+b
"""
def update_a(a_0, b_0, alpha, x, y, n):
"""
:param a_0: 上轮的a值
:param b_0: 上轮的b值
:param alpha: 学习率
:param x: 数据x
:param y: 数据y
:param n: 数据个数,计算的是均方误差
:return:
"""
return a_0 - alpha * (2 * a_0 * x * x + 2 * b_0 * x - 2 * y * x) / n
def update_b(a_0, b_0, alpha, x, y, n):
"""
:param a_0: 上一轮a值
:param b_0: 上一轮b值
:param alpha: 学习率
:param x: 数据x
:param y: 数据y
:param n: 数据个数
:return:
"""
return b_0 - alpha * (2 * b_0 + 2 * a_0 * x - 2 * y) / n
def get_current_loss(a, b, datas):
"""
:param a: 在梯度更新时的a
:param b: 在梯度更新时的b
:param datas: [(x, y), ...]
:return:
"""
_sum = 0
for ele in datas:
_sum += math.pow((ele[1] - (a * ele[0] + b)), 2)
return _sum / len(datas)
def train(a_0, b_0, alpha, datas, epoch):
for i in tqdm.tqdm(range(epoch)):
for data in datas:
a_0 = update_a(a_0, b_0, alpha, data[0], data[1], len(datas))
b_0 = update_b(a_0, b_0, alpha, data[0], data[1], len(datas))
print("第"+str(i)+"轮,当前参数:a = "+str(a_0)+", b = "+str(b_0)+", 损失:"+str(get_current_loss(a_0, b_0, datas)))
return a_0, b_0
def generate_datas():
# 生成训练数据(x,y) 取值w,b大约3和0.5
data_num = 100
value_set = []
for i in range(data_num):
x1 = np.random.normal(0.0, 0.6)
y1 = x1 * 3 + np.random.normal(0.0, 0.5)
value_set.append((x1, y1))
return value_set
if __name__ == '__main__':
datas = generate_datas()
a, b = train(1, 2, 1, datas, 10)
plt.scatter([val[0] for val in datas], [val[1] for val in datas])
plt.plot([val[0] for val in datas], [val[0] * a + b for val in datas], color='red', linewidth=3.0, linestyle='-')
plt.show()
拟合的结果也就是上图。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











