






title: 踩坑 redis 做临时缓存、数据库使用
tags: [‘redis’,‘缓存’,‘python’]
date: 2021-12-15
categories: “磨刀不误砍柴工”
环境
window10
redis
前言
使用到redis的原因,一是之前做的业务逻辑有需要对用户操作连续几个操作的逻辑判断和做一个时间上的有效性,二是做一下热数据的临时缓存。
redis的使用体验是很舒服,简单而又高效。
一点简介
安装就不说了,百度上一大堆教程,常用的几个config设置也比较好找,略略略。
Redis 是一个高性能的key-value数据库,这个对我学习的重点,是 key-value 形式的数据库,这和python的dict基本是一样的逻辑,这也是我觉得它灰常方便的主要原因。
常用操作
python操作
1.1 连接redis
-
普通连接
import redis conn = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True) -
线程池连接
import redis Pool = redis.ConnectionPool(host='127.0.0.1', port=6379,db=0, max_connections=10) conn = redis.Redis(connection_pool=Pool)程序中的
db=0指的是当前(默认)连接第一个数据库,并且redis默认有16个数据库,即db0------db15。不管是那种连接方式,后续操作都会使用这个
conn去执行。
1.2 redis的存储结构及操作
redis使用key-value(键值对)的方式存储数据,key就是一个字符串,没啥要说的,value有几种存储数据的方式。
1.2.1 字符串 String
这种存储的value是一个字符串,比如存储每个人的个性签名:
# -*- coding: utf-8 -*-
import json
import time
import redis
conn = redis.Redis(host='localhost', port=6379, db=8, decode_responses=True)
data_list = {
"路人甲": "天苍苍野茫茫,小灰灰和懒洋洋",
"路人乙": "爱拼才会赢,爱笑才会有朋友",
"路人丙": "随便瞎编一句个性签名吧。",
}
# 写入
for key, value in data_list.items():
conn.set(key, value)
# 读取
for key in conn.keys():
print("{}的个签是\t{}".format(key, conn.get(key)))
# 删除
conn.delete("路人甲")
print("删除路人的信息之后")
# 读取
for key in conn.keys():
print("{}的个签是\t{}".format(key, conn.get(key)))
# 判断是否存在
print("路人甲是否存在\t", conn.exists("路人甲"))
print("路人乙是否存在\t", conn.exists("路人乙"))
# 设置有效时间
conn.expire("路人乙", 3)
for i in range(0, 5):
time.sleep(1)
print("%d秒后,路人乙是否存在\t%d" % (i + 1, conn.exists("路人乙")))
这个地方的key对应的value必须全部都是String字符串形式才可以这样操作,不然会报错。
要提前做好每个库的规划,不要存的太随意了。

1.2.2 json 字典 Hash
这种存储的value是一个字典,比如存储每个人的身高体重血型:
data_list = {
"路人甲": {
"身高": 175,
"体重": 70,
"血型": "A",
},
"路人乙": {
"身高": 160,
"体重": 44,
"血型": "B",
},
"路人丙": {
"身高": 180,
"体重": 180,
"血型": "A",
},
}
# 写入
for key, value in data_list.items():
conn.hset("个人信息", key, json.dumps(value))
# 读取
for key in conn.hgetall("个人信息"):
data = conn.hget("个人信息", key)
data = json.loads(data)
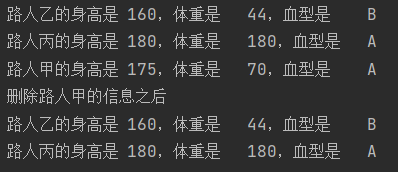
print("{}的身高是\t{},体重是\t{},血型是\t{}".format(key, data['身高'], data['体重'], data['血型']))
# 删除
conn.hdel("个人信息", "路人甲")
print("删除路人甲的信息之后")
# 读取
for key in conn.hgetall("个人信息"):
data = conn.hget("个人信息", key)
data = json.loads(data)
print("{}的身高是\t{},体重是\t{},血型是\t{}".format(key, data['身高'], data['体重'], data['血型']))
1.2.3 列表 list
这种存储的value是一个字典,比如存储个人的todo_list。
每次插值插在最前面
data_list = [
"1 今天睡个懒觉",
"2 去吃一碗香菇面",
"3 看个书吧",
"4 看个 不看了",
"5 擦擦鼠标",
"6 擦擦键盘",
"7 打开电脑",
"8 算了睡觉吧",
]
# 每次插值插在最前面
for data in data_list:
conn.lpush("todo_list", data)
对应在数据库中的数据:

每次插值插在最后面:
data_list = [
"1 今天睡个懒觉",
"2 去吃一碗香菇面",
"3 看个书吧",
"4 看个 不看了",
"5 擦擦鼠标",
"6 擦擦键盘",
"7 打开电脑",
"8 算了睡觉吧",
]
# 每次插值插在最前面
for data in data_list:
conn.rpush("todo_list", data)

使用lpush还是rpush看情况决定吧。
取出一个:
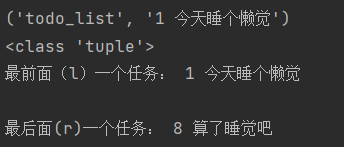
task1 = conn.blpop("todo_list")
print(task1)
print(type(task1))
print("最前面(l)一个任务:", task1[1])
print()
task2 = conn.brpop("todo_list")
print("最后面(r)一个任务:", task2[1])
1.2.3 集合 set
这种存储的value是一个集合,比如存储我的日常事件(不重复):
data_list = [
"吃",
"睡",
"蹲坑",
]
# 无序加入
for data in data_list:
conn.sadd("我的日常事件", data)
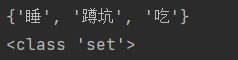
data = conn.smembers("我的日常事件")
print(data)
print(type(data))
写在最后
上述类型还有很多更详细的操作模式,以及还有其他类型,这边只写了一下常用的操作。
实力有限,才疏学浅,如有错误,欢迎指正。
- 我的个人博客 菜猫子小六 - 博客 (codesix.site)
- 我的简书 菜猫子小六 - 简书 (jianshu.com)
- 我的CSDN 菜猫子小六 - CSDN















 2368
2368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









