







一、对特定项的搜索
1、准备数据源信息,这里准备了7个txt文档(纯英文)。
2、建立索引信息,通过三个文本域建立索引,并使用了标准的分词器,分别是fileName(存储在索引目录中),fullPath(存储),contents(不存储)。
package com.feiyang.lucene;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
private IndexWriter writer;// 写索引实例
/**
* 构造方法 实例化写索引
* @param indexDir
* @throws Exception
*/
public Indexer(String indexDir) throws Exception {
Directory dir = FSDirectory.open(Paths.get(indexDir));
Analyzer analyzer = new StandardAnalyzer();//标准分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
writer = new IndexWriter(dir, conf);
}
//关闭写索引
public void close() throws Exception{
writer.close();
}
/**
* 索引指定目录的所有文件
* @param dataDir
* @throws Exception
*/
public int index(String dataDir)throws Exception{
File[] files = new File(dataDir).listFiles();
for(File f:files){
indexFile(f);
}
return writer.numDocs();
}
/**
* 索引指定文件
* @param f
* @throws IOException
*/
private void indexFile(File f) throws IOException {
// TODO Auto-generated method stub
System.out.println("索引文件:"+f.getCanonicalPath());
Document document = getDocument(f);
writer.addDocument(document);
}
/**
* 获取文档 ,文档里再设置每个字段
* @param f
*/
private Document getDocument(File f) throws IOException{
// TODO Auto-generated method stub
Document doc = new Document();
doc.add(new TextField("contents",new FileReader(f)));
doc.add(new TextField("fileName", f.getName(),Field.Store.YES));
doc.add(new TextField("fullPath", f.getCanonicalPath(),Field.Store.YES));
return doc;
}
public static void main(String[] args) {
String indexDir="D:\\lucene4";
String dataDir="D:\\lucene4\\data";
Indexer indexer = null;
int numIndexed = 0;
Long startTime = System.currentTimeMillis();
try {
indexer = new Indexer(indexDir);
numIndexed = indexer.index(dataDir);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally {
try {
indexer.close();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
Long endTime = System.currentTimeMillis();
System.out.println("索引:"+numIndexed+"个文件,花费了"+(endTime-startTime)+"毫秒");
//System.out.println("");
}
}
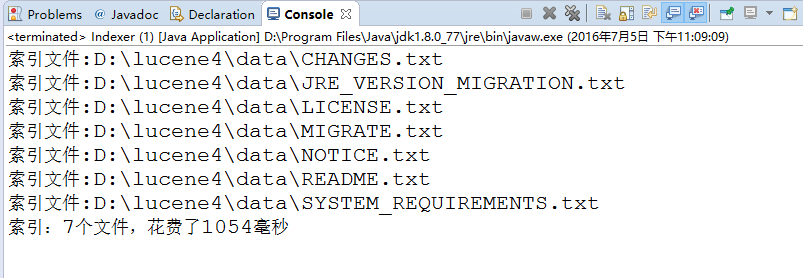
测试结果为:可以看到我们的七个文件都已经成功添加索引。
3、对特定项进行搜索。
package com.feiyang.lucene;
import static org.junit.Assert.*;
import java.nio.file.Paths;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class SearchTest {
private Directory dir;
private IndexReader reader ;
private IndexSearcher search;
@Before
public void setUp() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene4"));
reader = DirectoryReader.open(dir);
search = new IndexSearcher(reader);
}
@Test
public void test() {
fail("Not yet implemented");
}
@After
public void tearDown() throws Exception {
reader.close();
}
/**
* 对特定项搜索
* @throws Exception
*/
@Test
public void testTermQuery() throws Exception{
String searchField = "contents";
String q = "particular";
Term term = new Term(searchField, q);
Query query = new TermQuery(term);
TopDocs hits = search.search(query, 10);
System.out.println("匹配 '"+q+"',总共查询到"+hits.totalHits+"个文档");
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=search.doc(scoreDoc.doc);
System.out.println(doc.get("fullPath"));
}
}
}
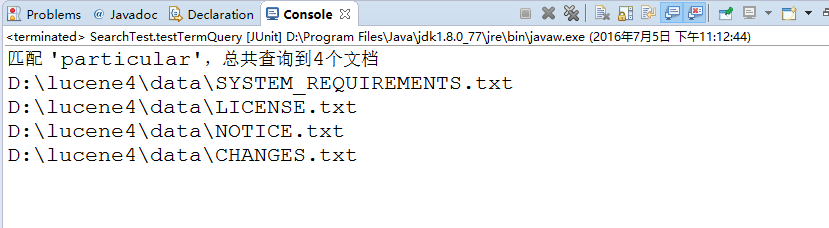
测试结果:成功匹配到4个文本中包含特定项‘particular’。
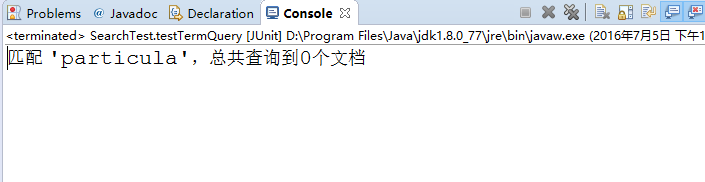
这个时候我们将特定项‘particular’改成‘particula’,去掉了最后一个字母,在进行测试。
测试结果:我们可以看到少了最后一个字母的特定项,没有检索出数据。
解释:我们的分词器会将我们指定的fileName,filePath,contents的内容进行分词,而基于特定项的检索就是根据分词后的结果进行检索。所以这种方法在我们环境中,不经常使用。
二、查询表达式:queryParser
通过Query query = parser.parse(“查询的关键词”),对关键词进行表达式设计,搜索信息。
/**
* 解析查询
* @throws Exception
*/
@Test
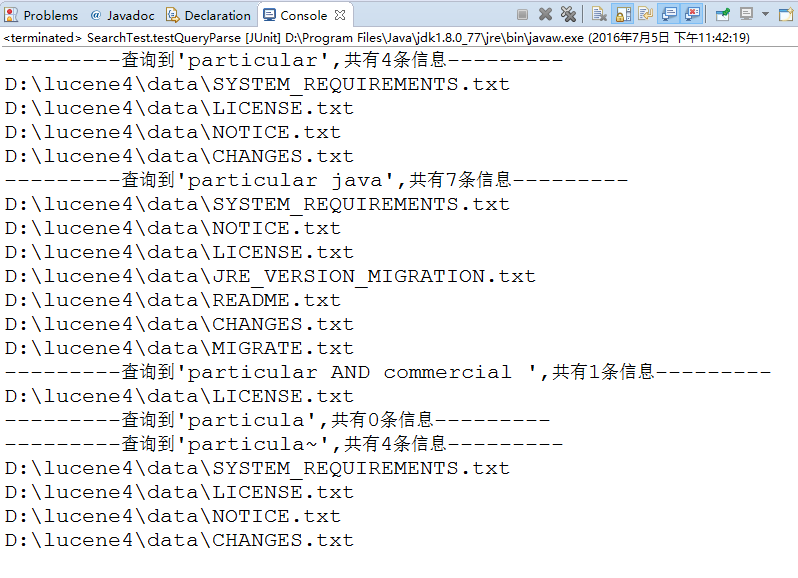
public void testQueryParse()throws Exception{
Analyzer analyzer = new StandardAnalyzer();
String searchField = "contents";
String[] q ={"particular","particular java","particular AND commercial ","particula","particula~"};
//查询特定项particular信息
//String q1 = "particular";
//查询获取particular或者java的信息
//String q2 = "particular java";
//查询获取particular与java的信息
//String q3 = "particular AND java";
//查询特定项particula的信息
//String q4 = "particula";
//查询particula相近的信息
//String q5 = "particula~";
QueryParser parser = new QueryParser(searchField, analyzer);
for(int i=0;i<q.length;i++){
Query query = parser.parse(q[i]);
TopDocs hits = search.search(query, 10);
System.out.println("---------查询到'"+q[i]+"',共有"+hits.totalHits+"条信息---------");
for(ScoreDoc scoreDoc :hits.scoreDocs){
Document document = search.doc(scoreDoc.doc);
System.out.println(document.get("fullPath"));
}
}
}
测试结果:
三、其他查询方式:
1、指定项范围查询TermRangeQuery
2、指定数字范围查询NumbericRangeQuery
3、指定字符串开头搜索PrefixQuery
4、组合查询BooleanQuery
package com.feiyang.lucene;
import static org.junit.Assert.fail;
import java.io.IOException;
import java.nio.file.Paths;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.NumericRangeQuery;
import org.apache.lucene.search.PrefixQuery;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermRangeQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.BytesRef;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class SearchTest2 {
private Directory dir;
private IndexReader reader ;
private IndexSearcher search;
@Before
public void setUp() throws Exception {
dir = FSDirectory.open(Paths.get("D:\\lucene5"));
reader = DirectoryReader.open(dir);
search = new IndexSearcher(reader);
}
@Test
public void test() {
fail("Not yet implemented");
}
@After
public void tearDown() throws Exception {
reader.close();
}
/**
* 对特定项范围搜索:TermRangeQuery
* @throws IOException
* @throws Exception
*/
@Test
public void testTermRangeQuery() throws IOException{
TermRangeQuery query = new TermRangeQuery("desc", new BytesRef("a".getBytes()), new BytesRef("c".getBytes()), true, true);
TopDocs hits = search.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=search.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 指定数字范围查询:NumbericRangeQuery
* @throws Exception
*/
@Test
public void testNumbericRangeQuery()throws Exception{
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 1, 2, true, true);
TopDocs hits = search.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=search.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 指定字符串开头搜索:PrefixQuery
* @throws Exception
*/
@Test
public void testPrefixQuery()throws Exception{
String searchField = "city";
String q = "q";
Term term = new Term(searchField, q);
PrefixQuery query = new PrefixQuery(term);
TopDocs hits = search.search(query, 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=search.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
/**
* 组合查询
* @throws Exception
*/
@Test
public void testBooleanQuery()throws Exception{
NumericRangeQuery<Integer> query = NumericRangeQuery.newIntRange("id", 1, 2, true, true);
BooleanQuery.Builder booleanQuery = new BooleanQuery.Builder();
//BooleanClause.Occur.MUST:包含
//BooleanClause.Occur.MUST_NOT:不包含
//BooleanClause.Occur.SHOULD:或者
booleanQuery.add(query, BooleanClause.Occur.MUST);
TopDocs hits = search.search(booleanQuery.build(), 10);
for(ScoreDoc scoreDoc:hits.scoreDocs){
Document doc=search.doc(scoreDoc.doc);
System.out.println(doc.get("id"));
System.out.println(doc.get("city"));
System.out.println(doc.get("desc"));
}
}
}















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









