







目录[-]
- 一。配置虚拟机软件
- 1.虚拟机软件设定
- 1)进入全集设定
- 2)常规设定
- 2.Linux安装配置
- 1)名称类型
- 2)内存
- 3)磁盘选择
- 4)磁盘文件
- 5)磁盘空间
- 6)磁盘位置
- 7)数据传输
- 8)软驱
- 9)Linux镜像
- 10)网络
- 二。安装模板Linux
- 1.一般安装过程
- 2.初始化用户
- 三。配置Linux
- 1.在桌面显示终端
- 2.在桌面显示“我的电脑”
- 3.安装增强功能
- 4.初始化root用户
- 5.关闭防火墙
- 四。准备资源
- 0.下载
- 1.安装SSH
- 1)openssh-client
- 2)openssh-server
- 3)ssh-all
- 4)ssh-keygen
- 5)authorized_keys
- 6)ssh localhost
- 2.安装JDK
- 1)环境变量
- 2)重载环境变量,测试
- 3.安装Hadoop
- 五。分布式集群搭建
- 1.增加虚拟系统
- 1)复制出一定数量的虚拟系统文件
- 2)修改UUID
- 3)导入系统
- 2.集群预设
- 1)修改用户名
- 2)配置 hostname
- 3)配置hosts
- 4)配置网卡静态IP
- 5)赋予用户对hadoop安装目录可写的权限
- 3.集群的SSH配置
- 1)生成新的id_rsa和id_rsa.pub文件
- 2)将hapmaster的authorized_keys文件发给hapslave1主机
- 3)为hapslave1新建id_rsa.pub并追加到authorized_keys文件
- 4)依次将全部主机的空密码加入到同一个authorized_keys文件
- 4.Hadoop集群配置
- 1)core-site.xml
- 2)hdfs-site.xml
- 3)mapred-site.xml
- 4)yarn-site.xml
- 5)yarn-env.sh
- 6)hadoop-env.sh
- 7)slaves
- 8)拷贝
- 六。启动集群
- 1.格式化HDFS系统
- 2.启动集群
- 3.监控集群资源
- 1)命令行
- 2)网页
一。配置虚拟机软件
下载地址:https://www.virtualbox.org/wiki/downloads

1.虚拟机软件设定
1)进入全集设定
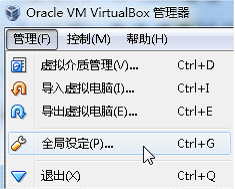
2)常规设定

2.Linux安装配置
1)名称类型
名称最后具有说明意义。版本根据个人情况。

2)内存
在下物理机系统Win7x64,处理器i53210,内存8G。

3)磁盘选择
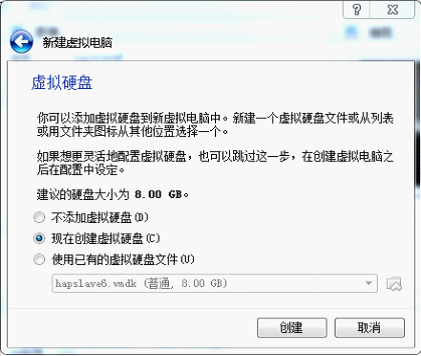
4)磁盘文件
virtualbox格式vdi,VMWare格式vmdk,微软格式vhd(virtualbox不支持),Parallels格式hdd(virtualbox不支持)。
vdi转vmdk:VBoxManage.exe clonehd 原镜像.vmdk 目标镜像.vdi --format VDI
vdi转vhd :VBoxManage.exe clonehd 原镜像.vdi 目标镜像.vmdk --format VMDK
vmdk转vhd:VBoxManage.exe clonehd 原镜像.vdi 目标镜像.vhd --format VHD

5)磁盘空间
根据个人物理机配置,固定大小运行更快。

6)磁盘位置

7)数据传输
共享粘贴板和鼠标拖放的实现还需要系统安装结束后安装增强功能。

8)软驱
去除勾选。
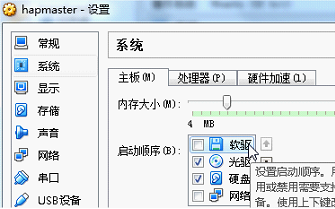
9)Linux镜像
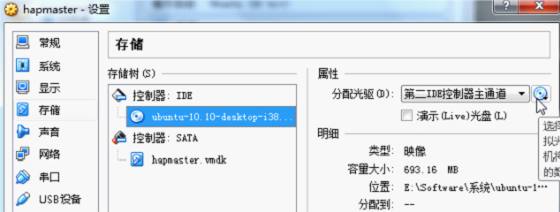
10)网络
去除勾选,安装过程中禁用网络。

二。安装模板Linux
1.一般安装过程

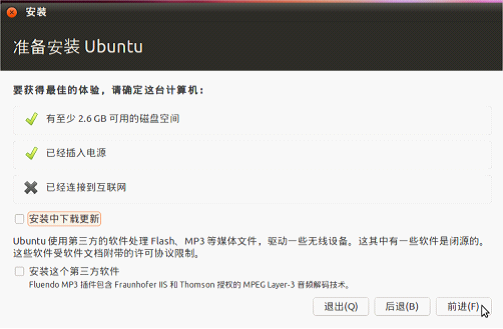
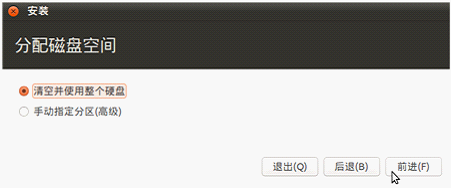


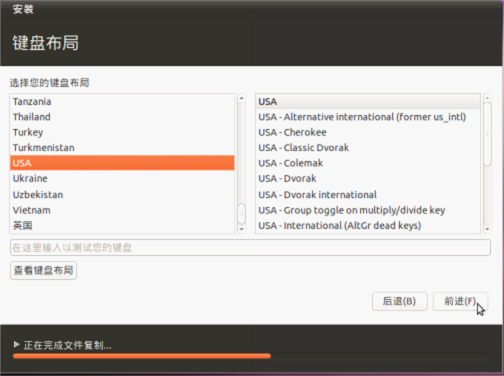
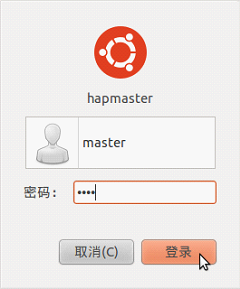
2.初始化用户
注意:不要使用“自动登录”。在下使用的是Ubuntu10.10,曾经这一步选择自动登录,给后续工作造成了很大麻烦。此时的用户名最好是一个通用的名称,因为后续会涉及SSH登录。


三。配置Linux
1.在桌面显示终端
便于使用命令行。
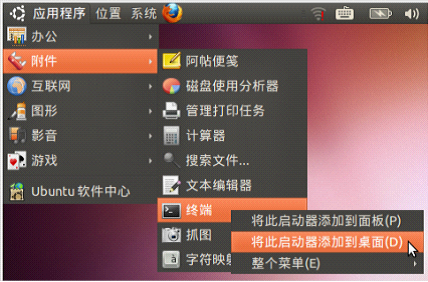
2.在桌面显示“我的电脑”

注意类型为“位置”。

3.安装增强功能
实现和物理机的粘贴板共享、鼠标拖放。






现在有很多视图模式可以使用:

4.初始化root用户

当前用户涉及集群配置的几个重要信息:

5.关闭防火墙
为了避免不必要的麻烦,在学习中建议关闭防火墙,这一步如果有修改,需重启系统:

四。准备资源
0.下载
OpenSSH:http://archive.ubuntu.com/ubuntu/pool/main/o/openssh/
http://mirrors.oschina.net/ubuntu/pool/main/o/openssh/
这里不要下载太新的版本,以为你的Linux可能缺少其依赖。
JDK:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
Hadoop:http://www.apache.org/dyn/closer.cgi/hadoop/common/


1.安装SSH
1)openssh-client
SHELL$ sudo dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb

2)openssh-server
SHELL$ sudo dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb

3)ssh-all
SHELL$ sudo dpkg -i sudo dpkg -i ssh_5.3p1-3ubuntu3_all.deb

4)ssh-keygen
在我们的学习环境中没有必要使用密码,所以创建密钥时留空,直接回车。
当然从这一步到6)可以先放弃,因为后续我们还需要单独在每台主机上操作。
SHELL$ ssh-keygen

5)authorized_keys
创建自动密码验证文件。如果使用cat命令,一个>为覆盖写入,另个为追加写入。还可以使用cp命令。
SHELL$ sudo cat id_rsa.pub > authorized_keys
SHELL$ sudo cat id_rsa.pub >> authorized_keys
SHELL$ sudo cp id_rsa.pub authorized_keys

6)ssh localhost
登录测试,初次登录会让用户确认:

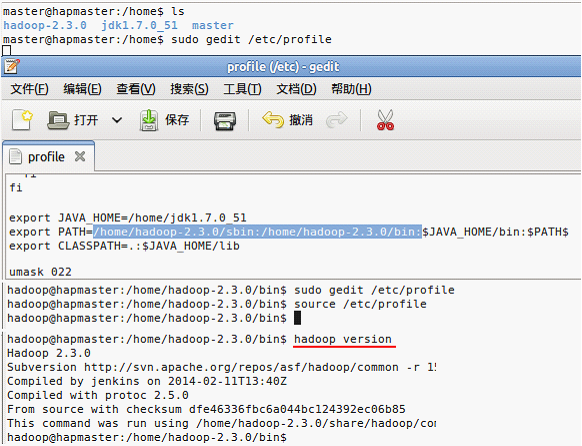
2.安装JDK
因为在下的jdk是gz格式,所以首先需要解压。解压后移动到合适的目录,注意不要用当前用户的工作目录,这是为了简化后续工作。
解压:SHELL$ sudo tar -zxvf jdk-7u51-linux-i586.gz
移动:SHELL$ sudo mv jdk1.7.0_51 /home
1)环境变量
SHELL$ sudo gedit /etc/profile

2)重载环境变量,测试
SHELL$ sudo source /etc/profile

3.安装Hadoop
同样,为了简化后续工作解压后移动到合适的目录。
解压:SHELL$ sudo tar -zxvf hadoop-2.3.0.tar.gz
移动:SHELL$ sudo mv hadoop-2.3.0 /home
配置环境变量:在环境变量加入hadoop的sbin目录并重载。
五。分布式集群搭建
1.增加虚拟系统
1)复制出一定数量的虚拟系统文件

2)修改UUID
%virtualbox% CMD> VBoxManage internalcommands sethduuid 虚拟系统文件.vmdk
3)导入系统
依照上文创建虚拟系统,到配置硬盘文件这一步:

先打开工作目录,发现虚拟系统文件夹已经创建,将复制出的系统文件放入:

然后使用已有的虚拟硬盘文件:

这样,每个虚拟系统的全部信息都保存在同一个文件夹了。
也可以使用VirtualBox的系统复制功能:



2.集群预设
7 个系统要按照下表一一配置:| 主机名 | 角色 | 登录用户 | hostname | hosts | IP | 网关 |
| hapmaster | 主控 master | hadoop (全部7个主机的用户都是同样的) | hapmaster | 127.0.0.1 localhost 192.168.1.240 hapmaster 192.168.1.241 hapslave1 192.168.1.242 hapslave2 192.168.1.243 hapslave3 192.168.1.244 hapslave4 192.168.1.245 hapslave5 192.168.1.246 hapslave6 | 192.168.1.240 | 192.168.1.1 |
| hapslave1 | 附属 slave | hadoop | hapslave1 | 127.0.0.1 localhost ... | 192.168.1.241 | 192.168.1.1 |
| hapslave2 | 附属 slave | hadoop | hapslave2 | 127.0.0.1 localhost ... | 192.168.1.242 | 192.168.1.1 |
| hapslave3 | 附属 slave | hadoop | hapslave3 | 127.0.0.1 localhost ... | 192.168.1.243 | 192.168.1.1 |
| hapslave4 | 附属 slave | hadoop | hapslave4 | 127.0.0.1 localhost ... | 192.168.1.244 | 192.168.1.1 |
| hapslave5 | 附属 slave | hadoop | hapslave5 | 127.0.0.1 localhost ... | 192.168.1.245 | 192.168.1.1 |
| hapslave6 | 附属 slave | hadoop | hapslave6 | 127.0.0.1 localhost ... | 192.168.1.246 | 192.168.1.1 |
下面就开始对7个系统分别进行配置,本文档记录以从属机hapslave1为例:
首先我们启动虚拟系统,直接使用root用户登录:

1)修改用户名
创建模板系统时我们已经初始化了root用户,所以,以后在学习环境中完全可以一直使用root用户。另外,如果你在安装ubuntu时初始化用户为“hadoop”,这一步和2)就可以跳过了。
(1)在root下修改登录用户名
SHELL$ chfn -f 新登录名 原登录名

(2)使用root修改用户
SHELL$ usermod -l 新登录名 -d /home/新登录名 -m 原登录名

2)配置 hostname
如果这一步使用的用户是非root,在命令前要加sudo 。建议继续在root下修改。主控机hapmaster也不需要此步骤。
SHELL$ sudo gedit /etc/hostname

3)配置hosts
无论主控机还是从属机,现在开始都需要单独配置。注意每次重启系统后一定要确认一下。
SHELL$ sudo gedit /etc/hosts

|
1
2
3
4
5
6
7
8
|
127.0.0.1 localhost
192.168.1.240 hapmaster
192.168.1.241 hapslave1
192.168.1.242 hapslave2
192.168.1.243 hapslave3
192.168.1.244 hapslave4
192.168.1.245 hapslave5
192.168.1.246 hapslave6
|
注意:配置hostname和hosts后需重启系统。可以在4)、5)步骤都结束后最终重启系统。或者执行:
SHELL$ sudo /etc/init.d/networking restart
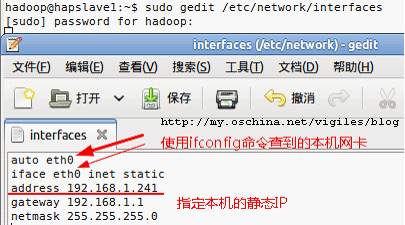
4)配置网卡静态IP
首先查看网卡名称
SHELL$ ifconfig

然后配置这个网卡:
SHELL$ sudo gedit /etc/network/interfaces
|
1
2
3
4
5
|
auto eth0
iface eth0 inet static
address 192.168.1.24*
gateway 192.168.1.1
netmask 255.255.255.0
|
这一步,如果只看到一个“lo”,一定要检查虚拟系统的网络配置是否开启。

配置interfaces后重启网卡:
SHELL$ sudo /etc/init.d/networking restart

5)赋予用户对hadoop安装目录可写的权限
SHELL$ sudo chown -hR 用户 hadoop根目录

3.集群的SSH配置
首先,把全部虚拟主机的网络都配置为桥接,以组成一个局域网。

然后逐个启动系统。都启动后最好使用ping命令测试是否能够互相通讯。
在创建模板系统时,已经在hapmaster主机创建了authorized_keys密钥文件,并且拷贝出的6个从属系统上也都有这个文件。
现在把7台主机上面的authorized_keys、id_rsa、id_rsa.pub三个文件都删掉。这三个文件在/home/用户名/.ssh/目录里。
下面使用hapmaster主机开始操作:
1)生成新的id_rsa和id_rsa.pub文件

2)将hapmaster的authorized_keys文件发给hapslave1主机
注意:远程用户要对远程主机上指定的目录有足够权限。
SHELL$ scp 文件 远程用户@远程主机:目录

3)为hapslave1新建id_rsa.pub并追加到authorized_keys文件
SHELL$ cat 源文件 目标文件

如果在执行追加时提示“bash: authorized_keys: 权限不够”,可以使用chown命令给当前用户添加操作.ssh目录的权限。
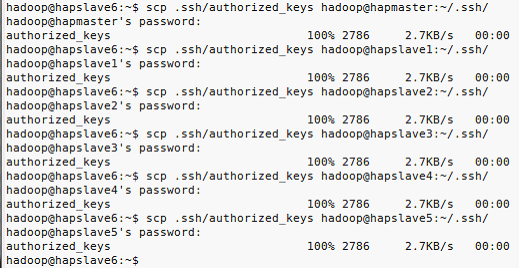
4)依次将全部主机的空密码加入到同一个authorized_keys文件
每个主机都获取了保存有7个主机公钥的authorized_keys文件后,开始测试SSH登录。
4.Hadoop集群配置
这一步的配置在7台系统上是相同的。在hadoop2.3.0中,以下配置文件都在%hadoop%/etc/hadoop目录里。现在以hapslave1系统为例进行配置。
1)core-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?
xml
version
=
"1.0"
encoding
=
"UTF-8"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<
configuration
>
<
property
>
<!-- 当前集群NameNode的IP地址和端口号。2.0前使用fs.default.name,但后续兼容-->
<
name
>fs.defaultFS</
name
>
<
value
>hdfs://192.168.1.240:9000</
value
>
</
property
>
<
property
>
<!-- 设置临时文件目录 -->
<
name
>hadoop.tmp.dir</
name
>
<!-- 当前用户须要对此目录有读写权限。可使用命令sudo chown -hR hadoop /home/hadoop-2.3.0/ -->
<
value
>/home/hadoop-2.3.0/hadoop-temp</
value
>
</
property
>
</
configuration
>
|
2)hdfs-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
<?
xml
version
=
"1.0"
encoding
=
"UTF-8"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<
configuration
>
<
property
>
<!-- SecondaryNamenode网络地址 -->
<
name
>dfs.namenode.secondary.http-address</
name
>
<
value
>192.168.1.240:9001</
value
>
</
property
>
<
property
>
<!-- NameNode工作目录,须预先存在 -->
<
name
>dfs.namenode.name.dir</
name
>
<
value
>file:/home/hadoop-2.3.0/dfs-name</
value
>
</
property
>
<
property
>
<!-- DataNode工作目录 -->
<
name
>dfs.datanode.data.dir</
name
>
<
value
>file:/home/hadoop-2.3.0/dfs-data</
value
>
</
property
>
<
property
>
<!-- 文件(副本)的存储数量 -->
<
name
>dfs.replication</
name
>
<!-- 小于或等于附属机数量。默认3 -->
<
value
>4</
value
>
</
property
>
<
property
>
<!-- 可以从网页端监控hdfs -->
<
name
>dfs.webhdfs.enabled</
name
>
<
value
>true</
value
>
</
property
>
</
configuration
>
|
3)mapred-site.xml
|
1
2
3
4
5
6
7
8
9
10
11
|
<?
xml
version
=
"1.0"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<
configuration
>
<
property
>
<!-- map-reduce运行框架 -->
<
name
>mapreduce.framework.name</
name
>
<!-- yarn:分布式模式 -->
<
value
>yarn</
value
>
</
property
>
</
configuration
>
|
4)yarn-site.xml
|
1
2
3
4
5
6
7
|
<?
xml
version
=
"1.0"
?>
<
configuration
>
<
property
>
<
name
>Yarn.nodemanager.aux-services</
name
>
<
value
>mapreduce.shuffle</
value
>
</
property
>
</
configuration
>
|
5)yarn-env.sh
|
1
|
export
JAVA_HOME=
/home/jdk1
.7.0_51
|
6)hadoop-env.sh
|
1
|
export
JAVA_HOME=
/home/jdk1
.7.0_51
|
7)slaves
这里保存的是全部从属机的主机名。
|
1
2
3
4
5
6
|
hapslave1
hapslave2
hapslave3
hapslave4
hapslave5
hapslave6
|
8)拷贝
SHELL$ sudo scp -rpv /home/hadoop-2.3.0/etc/hadoop/* 其它主机:/home/hadoop-2.3.0/etc/hadoop/
六。启动集群
1.格式化HDFS系统
注意:需无任何warning或error。
SHELL../bin$ hdfs namenode -format 或 hadoop namenode -format


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
hadoop@hapmaster:
/home/hadoop-2
.3.0
/bin
$ hdfs namenode -
format
14
/03/14
13:27:47 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = hapmaster
/127
.0.0.1
STARTUP_MSG: args = [-
format
]
STARTUP_MSG: version = 2.3.0
STARTUP_MSG: classpath =
/home/hadoop-2
.3.0
/etc/hadoop
:
/home/hadoop-2
.3.0
/share/hadoop/common/lib/jsr305-1
.3.9.jar:
/home/hadoop-2
.3.0
/share/hadoop/common/lib/junit-4
.8.2.jar:
STARTUP_MSG: build = http:
//svn
.apache.org
/repos/asf/hadoop/common
-r 1567123; compiled by
'jenkins'
on 2014-02-11T13:40Z
STARTUP_MSG: java = 1.7.0_51
************************************************************/
14
/03/14
13:27:47 INFO namenode.NameNode: registered UNIX signal handlers
for
[TERM, HUP, INT]
Formatting using clusterid: CID-82cb09b4-74eb-4053-9b46-8de025de7f74
14
/03/14
13:27:50 INFO namenode.FSNamesystem: fsLock is fair:
true
14
/03/14
13:27:51 INFO namenode.HostFileManager:
read
includes:
HostSet(
)
14
/03/14
13:27:51 INFO namenode.HostFileManager:
read
excludes:
HostSet(
)
14
/03/14
13:27:51 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
14
/03/14
13:27:51 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-
hostname
-check=
true
14
/03/14
13:27:51 INFO util.GSet: Computing capacity
for
map BlocksMap
14
/03/14
13:27:51 INFO util.GSet: VM
type
= 32-bit
14
/03/14
13:27:51 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
14
/03/14
13:27:51 INFO util.GSet: capacity = 2^22 = 4194304 entries
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: dfs.block.access.token.
enable
=
false
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: defaultReplication = 4
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: maxReplication = 512
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: minReplication = 1
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks =
false
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: encryptDataTransfer =
false
14
/03/14
13:27:51 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
14
/03/14
13:27:51 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
14
/03/14
13:27:51 INFO namenode.FSNamesystem: supergroup = supergroup
14
/03/14
13:27:51 INFO namenode.FSNamesystem: isPermissionEnabled =
true
14
/03/14
13:27:51 INFO namenode.FSNamesystem: HA Enabled:
false
14
/03/14
13:27:51 INFO namenode.FSNamesystem: Append Enabled:
true
14
/03/14
13:27:52 INFO util.GSet: Computing capacity
for
map INodeMap
14
/03/14
13:27:52 INFO util.GSet: VM
type
= 32-bit
14
/03/14
13:27:52 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
14
/03/14
13:27:52 INFO util.GSet: capacity = 2^21 = 2097152 entries
14
/03/14
13:27:52 INFO namenode.NameNode: Caching
file
names occuring
more
than 10
times
14
/03/14
13:27:52 INFO util.GSet: Computing capacity
for
map cachedBlocks
14
/03/14
13:27:52 INFO util.GSet: VM
type
= 32-bit
14
/03/14
13:27:52 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
14
/03/14
13:27:52 INFO util.GSet: capacity = 2^19 = 524288 entries
14
/03/14
13:27:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
14
/03/14
13:27:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
14
/03/14
13:27:52 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
14
/03/14
13:27:52 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
14
/03/14
13:27:52 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry
time
is 600000 millis
14
/03/14
13:27:52 INFO util.GSet: Computing capacity
for
map Namenode Retry Cache
14
/03/14
13:27:52 INFO util.GSet: VM
type
= 32-bit
14
/03/14
13:27:52 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
14
/03/14
13:27:52 INFO util.GSet: capacity = 2^16 = 65536 entries
14
/03/14
13:27:52 INFO common.Storage: Storage directory
/home/hadoop-2
.3.0
/dfs-name
has been successfully formatted.
14
/03/14
13:27:52 INFO namenode.FSImage: Saving image
file
/home/hadoop-2
.3.0
/dfs-name/current/fsimage
.ckpt_0000000000000000000 using no compression
14
/03/14
13:27:52 INFO namenode.FSImage: Image
file
/home/hadoop-2
.3.0
/dfs-name/current/fsimage
.ckpt_0000000000000000000 of size 218 bytes saved
in
0 seconds.
14
/03/14
13:27:52 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
14
/03/14
13:27:52 INFO util.ExitUtil: Exiting with status 0
14
/03/14
13:27:52 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hapmaster
/127
.0.0.1
************************************************************/
hadoop@hapmaster:
/home/hadoop-2
.3.0
/bin
$
|
2.启动集群
SHELL.../sbin$ start-all.sh


3.监控集群资源
1)命令行
SHELL$ hdfs dfsadmin -report

2)网页

- end















 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









