







目录[-]
- 1.查询:
- 1)方式一-指定HDFS的URI:
- 2)方式二-指定HDFS的配置文件:
- 3)判断HDFS中指定名称的目录或文件:
- 4)查看HDFS文件的最后修改时间:
- 5)查看HDFS中指定文件的状态:
- 6)读取HDFS中txt文件的内容:
- 2.上传:
- 1)从Win7上传文件到Ubuntu的HDFS:
- 2)从Win7在Ubuntu的HDFS远程创建目录和文件:
- 3.修改:
- 1)重命名文件:
- 2)删除文件:
- 4.WordCount示例:
- 1)代码:
- 2)Run on Hadoop:
- 错误1:Unable to load native-hadoop library
- 错误2:Name node is in safe mode
- 3)Run on Hadoop:



和在Ubuntu中的操作雷同。
1.查询:
1)方式一-指定HDFS的URI:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package
com.cuiweiyou.hdfs;
import
java.net.URI;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs1 {
private
static
FileSystem hdfs;
public
static
void
main(String[] args)
throws
Exception {
// 1.创建配置器
Configuration conf =
new
Configuration();
// 2.创建文件系统(手动指定HDFS的URI)
hdfs = FileSystem.get(URI.create(
"hdfs://192.168.1.251:9000/"
), conf);
// 3.遍历HDFS上的文件和目录
FileStatus[] fs = hdfs.listStatus(
new
Path(
"/"
));
if
(fs.length >
0
) {
for
(FileStatus f : fs) {
showDir(f);
}
}
}
private
static
void
showDir(FileStatus fs)
throws
Exception {
Path path = fs.getPath();
System.out.println(path);
// 如果是目录
if
(fs.isDir()) {
FileStatus[] f = hdfs.listStatus(path);
if
(f.length >
0
) {
for
(FileStatus file : f) {
showDir(file);
}
}
}
}
}
|
2)方式二-指定HDFS的配置文件:
(1)在Win7系统中创建一个core-site.xml文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<?
xml
version
=
"1.0"
?>
<?
xml-stylesheet
type
=
"text/xsl"
href
=
"configuration.xsl"
?>
<!-- Put site-specific property overrides in this file. -->
<
configuration
>
<
property
>
<
name
>fs.default.name</
name
>
<!-- 指定Ubuntu的IP -->
<
value
>hdfs://192.168.1.251:9000</
value
>
</
property
>
<
property
>
<
name
>hadoop.tmp.dir</
name
>
<
value
>/home/hm/hadoop-${user.name}</
value
>
</
property
>
</
configuration
>
|
(2)使用Java遍历Ubuntu中HDFS上的目录和文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs2 {
private
static
FileSystem hdfs;
public
static
void
main(String[] args)
throws
Exception {
// 1.创建配置器
Configuration conf =
new
Configuration();
// 2.加载指定的配置文件
conf.addResource(
new
Path(
"c:/core-site.xml"
));
// 3.创建文件系统
hdfs = FileSystem.get(conf);
// 4.遍历HDFS上的文件和目录
FileStatus[] fs = hdfs.listStatus(
new
Path(
"/"
));
if
(fs.length >
0
) {
for
(FileStatus f : fs) {
showDir(f);
}
}
}
private
static
void
showDir(FileStatus fs)
throws
Exception {
Path path = fs.getPath();
System.out.println(path);
// 如果是目录
if
(fs.isDir()) {
FileStatus[] f = hdfs.listStatus(path);
if
(f.length >
0
) {
for
(FileStatus file : f) {
showDir(file);
}
}
}
}
}
|

3)判断HDFS中指定名称的目录或文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs3 {
private
static
FileSystem hdfs;
public
static
void
main(String[] args)
throws
Exception {
// 1.配置器
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
// 2.文件系统
hdfs = FileSystem.get(conf);
// 3.遍历HDFS目录和文件
FileStatus[] fs = hdfs.listStatus(
new
Path(
"/"
));
if
(fs.length >
0
) {
for
(FileStatus f : fs) {
showDir(f);
}
}
}
private
static
void
showDir(FileStatus fs)
throws
Exception {
Path path = fs.getPath();
// 如果是目录
if
(fs.isDir()) {
if
(path.getName().equals(
"system"
)) {
System.out.println(path +
"是目录"
);
}
FileStatus[] f = hdfs.listStatus(path);
if
(f.length >
0
) {
for
(FileStatus file : f) {
showDir(file);
}
}
}
else
{
if
(path.getName().equals(
"test.txt"
)) {
System.out.println(path +
"是文件"
);
}
}
}
}
|

4)查看HDFS文件的最后修改时间:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package
com.cuiweiyou.hdfs;
import
java.net.URI;
import
java.util.Date;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs4 {
private
static
FileSystem hdfs;
public
static
void
main(String[] args)
throws
Exception {
// 1.配置器
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
// 2.文件系统
hdfs = FileSystem.get(conf);
// 3.遍历HDFS目录和文件
FileStatus[] fs = hdfs.listStatus(
new
Path(
"/"
));
if
(fs.length>
0
){
for
(FileStatus f : fs) {
showDir(f);
}
}
}
private
static
void
showDir(FileStatus fs)
throws
Exception {
Path path = fs.getPath();
//获取最后修改时间
long
time = fs.getModificationTime();
System.out.println(
"HDFS文件的最后修改时间:"
+
new
Date(time));
System.out.println(path);
if
(fs.isDir()) {
FileStatus[] f = hdfs.listStatus(path);
if
(f.length>
0
){
for
(FileStatus file : f) {
showDir(file);
}
}
}
}
}
|

5)查看HDFS中指定文件的状态:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.BlockLocation;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs5 {
public
static
void
main(String[] args)
throws
Exception {
//1.配置器
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
//2.文件系统
FileSystem fs = FileSystem.get(conf);
//3.已存在的文件
Path path =
new
Path(
"/test.txt"
);
//4.文件状态
FileStatus status = fs.getFileStatus(path);
//5.文件块
BlockLocation[] blockLocations = fs.getFileBlockLocations(status,
0
, status.getLen());
int
blockLen = blockLocations.length;
System.err.println(
"块数量:"
+blockLen);
for
(
int
i =
0
; i < blockLen; i++) {
// 主机名
String[] hosts = blockLocations[i].getHosts();
for
(String host : hosts) {
System.err.println(
"主机:"
+host);
}
}
}
}
|

6)读取HDFS中txt文件的内容:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FSDataInputStream;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs6 {
public
static
void
main(String[] args)
throws
Exception {
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
FileSystem fs = FileSystem.get(conf);
Path path =
new
Path(
"/test.txt"
);
// 使用HDFS数据输入流(读)对象 读取HDSF的文件
FSDataInputStream is = fs.open(path);
FileStatus status = fs.getFileStatus(path);
byte
[] buffer =
new
byte
[Integer.parseInt(String.valueOf(status.getLen()))];
is.readFully(
0
, buffer);
is.close();
fs.close();
System.out.println(
new
String(buffer));
}
}
|

2.上传:
1)从Win7上传文件到Ubuntu的HDFS:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs7 {
private
static
FileSystem hdfs;
public
static
void
main(String[] args)
throws
Exception {
// 1.创建配置器
Configuration conf =
new
Configuration();
// 2.加载指定的配置文件
conf.addResource(
new
Path(
"c:/core-site.xml"
));
// 3.创建文件系统
hdfs = FileSystem.get(conf);
// 4. 本地文件
Path src =
new
Path(
"f:/民间秘方.txt"
);
// 5. 目标路径
Path dst =
new
Path(
"/home"
);
// 6. 上传文件
if
(!hdfs.exists(
new
Path(
"/home/民间秘方.txt"
))) {
hdfs.copyFromLocalFile(src, dst);
System.err.println(
"文件上传成功至: "
+ conf.get(
"fs.default.name"
) + dst);
}
else
{
System.err.println(conf.get(
"fs.default.name"
) + dst +
" 中已经存在 test.txt"
);
}
// 7.遍历HDFS上的文件和目录
FileStatus[] fs = hdfs.listStatus(
new
Path(
"/"
));
if
(fs.length >
0
) {
for
(FileStatus f : fs) {
showDir(f);
}
}
}
private
static
void
showDir(FileStatus fs)
throws
Exception {
Path path = fs.getPath();
System.out.println(path);
// 如果是目录
if
(fs.isDir()) {
FileStatus[] f = hdfs.listStatus(path);
if
(f.length >
0
) {
for
(FileStatus file : f) {
showDir(file);
}
}
}
}
}
|

2)从Win7在Ubuntu的HDFS远程创建目录和文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
package
com.cuiweiyou.hdfs;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FSDataInputStream;
import
org.apache.hadoop.fs.FSDataOutputStream;
import
org.apache.hadoop.fs.FileStatus;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
public
class
TestQueryHdfs8 {
public
static
void
main(String[] args)
throws
Exception {
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
FileSystem hdfs = FileSystem.get(conf);
// 使用HDFS数据输出流(写)对象 在HDSF的根目录创建一个文件夹,其内再创建文件
FSDataOutputStream out = hdfs.create(
new
Path(
"/eminem/hip-hop.txt"
));
// 在文件中写入一行数据,必须使用UTF-8
// out.writeUTF("Hell使用UTF-8"); //不能用?
out.write(
"痞子阿姆 Hello !"
.getBytes(
"UTF-8"
));
out = hdfs.create(
new
Path(
"/alizee.txt"
));
out.write(
"艾莉婕 Hello !"
.getBytes(
"UTF-8"
));
out.close();
hdfs.close();
hdfs = FileSystem.get(conf);
FileStatus[] fileStatus = hdfs.listStatus(
new
Path(
"/"
));
//命名外层循环,遍历前两层目录
outside:
for
(FileStatus file : fileStatus) {
Path filePath = file.getPath();
System.out.println(filePath);
if
(file.isDir()) {
FileStatus[] fs = hdfs.listStatus(filePath);
for
(FileStatus f : fs) {
Path fp= f.getPath();
System.out.println(fp);
//读取hip-hop.txt文件
if
(fp.getName().equals(
"hip-hop.txt"
)){
FSDataInputStream fsis = hdfs.open(fp);
FileStatus status = hdfs.getFileStatus(fp);
byte
[] buffer =
new
byte
[Integer.parseInt(String.valueOf(status.getLen()))];
fsis.readFully(
0
, buffer);
fsis.close();
hdfs.close();
System.out.println(
new
String(buffer));
break
outside;
//跳出外循环
}
}
}
}
}
}
|

3.修改:
1)重命名文件:
|
1
2
3
4
5
6
7
8
|
public
static
void
main(String[] args)
throws
Exception {
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
FileSystem fs = FileSystem.get(conf);
//重命名:fs.rename(源文件,新文件)
boolean
rename = fs.rename(
new
Path(
"/alizee.txt"
),
new
Path(
"/adele.txt"
));
System.out.println(rename);
}
|
2)删除文件:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public
static
void
main(String[] args)
throws
Exception {
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
FileSystem fs = FileSystem.get(conf);
//删除
//fs.delete(new Path("/new_test.txt")); //已过时
//程序结束时执行
boolean
exit = fs.deleteOnExit(
new
Path(
"/eminem/hip-hop.txt"
));
System.out.println(
"删除执行:"
+exit);
//判断删除(路径,true。false=非空时不删除,抛RemoteException、IOException异常)
boolean
delete = fs.delete(
new
Path(
"/eminem"
),
true
);
System.out.println(
"执行删除:"
+delete);
}
|
4.WordCount示例:
1)代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
package
com.cuiweiyou.hdfs;
import
java.io.IOException;
import
java.util.StringTokenizer;
//分词器
import
org.apache.hadoop.conf.Configuration;
//配置器
import
org.apache.hadoop.fs.Path;
//路径
import
org.apache.hadoop.io.IntWritable;
//整型写手
import
org.apache.hadoop.io.Text;
//文本写手
import
org.apache.hadoop.mapreduce.Job;
//工头
import
org.apache.hadoop.mapreduce.Mapper;
//映射器
import
org.apache.hadoop.mapreduce.Reducer;
//拆分器
import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
//文件格式化读取器
import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//文件格式化创建器
public
class
TestQueryHdfs11 {
/**
* 内部类:映射器
* Mapper<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT>
*/
public
static
class
MyMapper
extends
Mapper<Object, Text, Text, IntWritable> {
private
final
static
IntWritable one =
new
IntWritable(
1
);
// 类似于int类型
private
Text word =
new
Text();
// 可以理解成String类型
/**
* 重新map方法
*/
public
void
map(Object key, Text value, Context context)
throws
IOException, InterruptedException {
System.err.println(key +
","
+ value);
// 分词器:默认根据空格拆分字符串
StringTokenizer itr =
new
StringTokenizer(value.toString());
while
(itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
};
}
/**
* 内部类:拆分器
* Reducer<KEY_IN, VALUE_IN, KEY_OUT, VALUE_OUT>
*/
public
static
class
MyReducer
extends
Reducer<Text, IntWritable, Text, IntWritable> {
private
IntWritable result =
new
IntWritable();
/**
* 重新reduce方法
*/
protected
void
reduce(Text key, Iterable<IntWritable> values, Context context)
throws
IOException, InterruptedException {
System.err.println(key +
","
+ values);
int
sum =
0
;
for
(IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
// 这是最后结果
};
}
public
static
void
main(String[] args)
throws
Exception {
// 声明配置信息
Configuration conf =
new
Configuration();
conf.addResource(
new
Path(
"c:/core-site.xml"
));
// 声明Job
Job job =
new
Job(conf,
"Word Count"
);
// 设置工作类
job.setJarByClass(TestQueryHdfs11.
class
);
// 设置mapper类
job.setMapperClass(MyMapper.
class
);
// 可选
job.setCombinerClass(MyReducer.
class
);
// 设置合并计算类
job.setReducerClass(MyReducer.
class
);
// 设置key为String类型
job.setOutputKeyClass(Text.
class
);
// 设置value为int类型
job.setOutputValueClass(IntWritable.
class
);
// 设置接收输入或是输出
FileInputFormat.setInputPaths(job,
new
Path(
"/test.txt"
));
FileOutputFormat.setOutputPath(job,
new
Path(
"/out"
));
// 执行
System.exit(job.waitForCompletion(
true
) ?
0
:
1
);
}
}
|
2)Run on Hadoop:

错误1:Unable to load native-hadoop library
无法为你的平台加载本地hadoop类库... 程序使用了内部类
安全相关的用户组信息:权限执行异常:hm:许可无效:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
13
/05/20
16:48:34 WARN util.NativeCodeLoader:
Unable to load native-hadoop library
for
your platform... using
builtin
-java classes where applicable
13
/05/20
16:48:34 ERROR security.UserGroupInformation:
PriviledgedActionException as:hm cause:java.io.IOException:
Failed to
set
permissions of path:
\home\hm\hadoop-hm\mapred\staging\hm-975542536\.staging to 0700
Exception
in
thread
"main"
java.io.IOException:
Failed to
set
permissions of path:
\home\hm\hadoop-hm\mapred\staging\hm-975542536\.staging to 0700
at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:689)
at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:662)
at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509)
at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344)
at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:918)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:912)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:912)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:500)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:530)
at cn.cvu.hdfs.TestQueryHdfs11.main(TestQueryHdfs11.java:69)
|
解决:
方法一: 修改源码%hadoop%/src/core/org/apache/hadoop/fs/FileUtil.java手动制作hadoop-core-1.1.2.jar
1.注释662、665、670、673、678、681行,并注释checkReturnValue方法


2.编译hadoop源码包
没有成功,待续。
方法二: 直接替换hadoop-core-1.1.2.jar/org/apache/hadoop/fs/FileUtil.class文件
文件下载:http://download.csdn.net/detail/vigiles/5422251
1.使用winrar打开jar包的hadoop-1.1.2\hadoop-core-1.1.2.jar\org\apache\hadoop\fs目录
2.将已修改的FileUtil.class文件拖入
3.替换,保存
4.放入Ubuntu中%hadoop%目录,替换原有的jar包
5.放入Win7中eclipse引用的hadoop解压根目录,替换原有的jar包
6.stop-all.sh,start-all.sh
7.从win7访问:Run on Hadoop :
方法三: 在src下创建目录org.apache.hadoop.fs,在其中放入FileUtil.java文件,注释checkReturnValue方法体:
同上图。
错误2:Name node is in safe mode
安全模式异常。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
13
/05/21
15:27:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library
for
your platform... using
builtin
-java classes where applicable
13
/05/21
15:27:55 WARN mapred.JobClient: Use GenericOptionsParser
for
parsing the arguments. Applications should implement Tool
for
the same.
13
/05/21
15:27:55 WARN mapred.JobClient: No job jar
file
set
. User classes may not be found. See JobConf(Class) or JobConf
#setJar(String).
13
/05/21
15:27:55 INFO input.FileInputFormat: Total input paths to process : 1
13
/05/21
15:27:55 WARN snappy.LoadSnappy: Snappy native library not loaded
13
/05/21
15:27:55 INFO mapred.JobClient: Running job: job_local_0001
13
/05/21
15:27:55 WARN mapred.LocalJobRunner: job_local_0001
org.apache.hadoop.ipc.RemoteException: org.apache.hadoop.hdfs.server.namenode.SafeModeException: Cannot create directory
/out/_temporary
. Name node is
in
safe mode.
Use
"hadoop dfsadmin -safemode leave"
to turn safe mode off.
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:2204)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2178)
at org.apache.hadoop.hdfs.server.namenode.NameNode.mkdirs(NameNode.java:857)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:578)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1393)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1389)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1149)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1387)
at org.apache.hadoop.ipc.Client.call(Client.java:1107)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:229)
at $Proxy1.mkdirs(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:85)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:62)
at $Proxy1.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:1426)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:332)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1126)
at org.apache.hadoop.mapred.FileOutputCommitter.setupJob(FileOutputCommitter.java:52)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:186)
13
/05/21
15:27:56 INFO mapred.JobClient: map 0% reduce 0%
13
/05/21
15:27:56 INFO mapred.JobClient: Job complete: job_local_0001
13
/05/21
15:27:56 INFO mapred.JobClient: Counters: 0
|
解决:
关闭hadoop的安全模式:
|
1
|
hm@hm-ubuntu:~$ hadoop dfsadmin -safemode leave
|

3)Run on Hadoop:

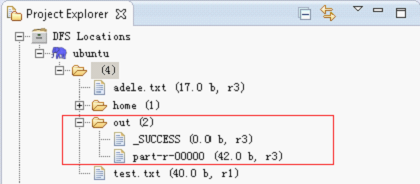
- end















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









