






前言
近期对于小说网站需要学习爬虫知识,除了基本的requests和bs4这些 使用一些好用的框架简单语法使用
Scrapy和PySpider
Scrapy
是用纯 Python 实现一个为了爬取网站数据、提取结构性数据而编写的应用框架, 用途非常广泛。
安装教程
1.下载python
2.配置环境变量

3.升级pip安装包
python -m pip install --upgrade pip
pip安装命令后面加上-i https://pypi.tuna.tsinghua.edu.cn/simple ,链接还可以换成其他国内镜像链接:
- 清华大学:
https://pypi.tuna.tsinghua.edu.cn/simple - 豆瓣
http://pypi.douban.com/simple --trusted-host pypi.douban.com
4.下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
(1)点击下载地址,进入后按 ctrl+f ,搜索twisted,然后下载对应版本
cp27:表示python2.7版本 cp36:表示python3.6版本
win32:表示Windows32位操作系统

(2)下载完成后进入终端,输入pip install 文件名(你下载哪个文件就输入哪个文件的文件名,要输入全部路径) Twisted-18.7.0-cp36-cp36m-win32.whl
安装完成后再输入pip install scrapy,回车
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
检测scrapy安装是否成功:在终端输入scrapy,出现以下内容就代表安装成功
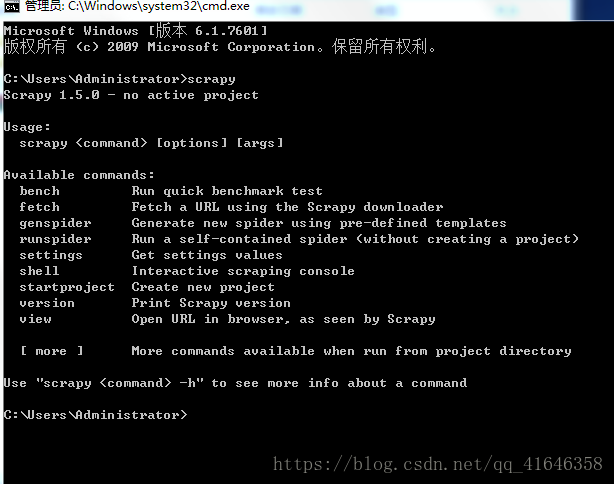
使用语法

创建爬虫
scrapy genspider fictionspider www.beqege.cc/1522/
官方文档
Scrapy 教程 — Scrapy 文档 (scrapy-16.readthedocs.io)
pycarm使用
②新建第一个scrapy项目,先cd到想要的目录,然后输入:scrapy startproject PythonScrapy ,就建好了一个项目
打开新建的项目,然后如图:

在项目目录下新建一个start.py用来实现项目的启动

然后在spider下新建一个Test_spider.py 其中name = "Test_spider"就是爬虫名字,所以在start.py下也启动这个名字
设置scrapy日志只提醒错误
要将Scrapy日志级别设置为只提醒错误,您可以在Scrapy的settings.py文件中添加以下代码:
pythonCopy code
LOG_LEVEL = 'ERROR'
这将将日志级别设置为错误级别,只输出错误级别的日志信息。这样,您将只看到错误消息而不会看到其他日志消息。
















 2026
2026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











