







ES概念:
cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway:代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
倒排索引的介绍:
倒排索引实际上由于应用中需要根据属性值来查找记录,这种索引表中的每一项都包含一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称之为倒排索引(inverted index),带有倒排索引的文件称之为倒排
索引文件,简称倒排文件。
比如说我们接下来要搜索下面的这句话:
“python写各大聊天系统的屏蔽脏话功能原理”
于是根据搜索引擎给关键词进行分词的操作,于是便可以得到下面的查询统计记录结果:

关键词代表的是 搜索引擎 给句子分出来的词,下面的文章代表搜索引擎具体在哪篇文章中搜索出来的数据
我们还可以把这个搜索出的结果更加的细化,变成更加具体的定位
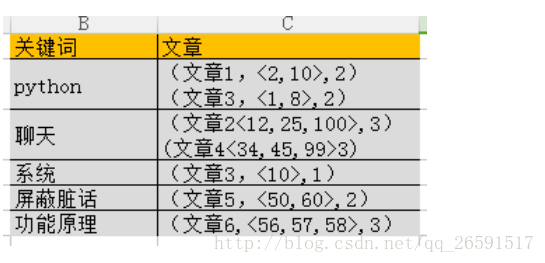
第二列文章中代表的含义分别是( 该关键词所在的文章 ,<该关键词在文章出出现的索引位置> ,该关键词出现的次数 )
这样以来搜索引擎就可以根据把句子进行分词,然后根据对分词的查询在文章中的位置将其按照某种方法进行排序操作,完成搜索引擎的排序功能。
倒排索引还需要亟待解决的问题:
1、大小写转化的问题,如python和PYTHON应该为一个词
2、词干抽取的问题,比如 look 和 looking 这两个词结果都处理成了look
3、分词,“屏蔽系统”这个词 应该是 分词为 “屏蔽“ , “系统” 两个词还是 “屏蔽系统” 这样一个词
4、倒排索引文件过大 — 需要压缩进行编码















 1277
1277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









