







前言
分析股票、期货数据时,通常将csv文件以DataFrame格式读入内存,通过调用Pandas的API进行数据处理,下文列举部分常用方法,方便查询。
基础知识
首先了解Dataframe的数据结构和操作方法,参考
官网的10分钟入门
日常记录
此处不定时整理更新日常工作中碰到数据处理问题
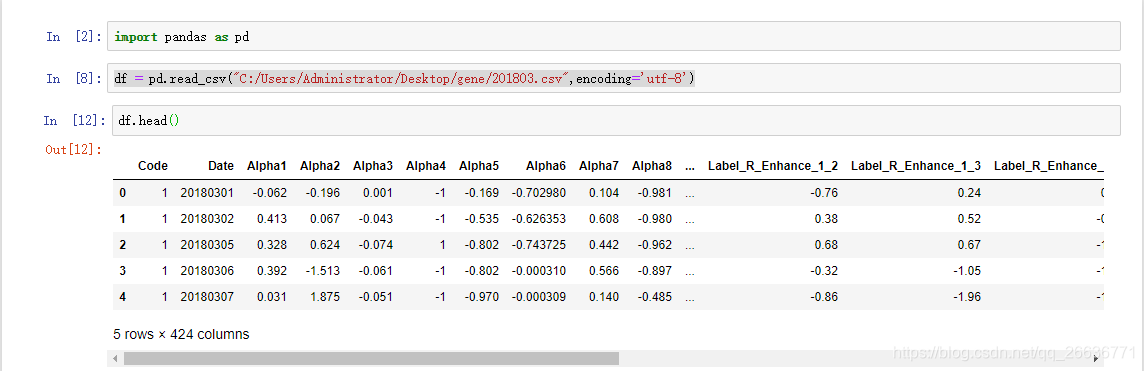
1.读取股票因子文件
2.将int格式的Date字段转化为Datetime
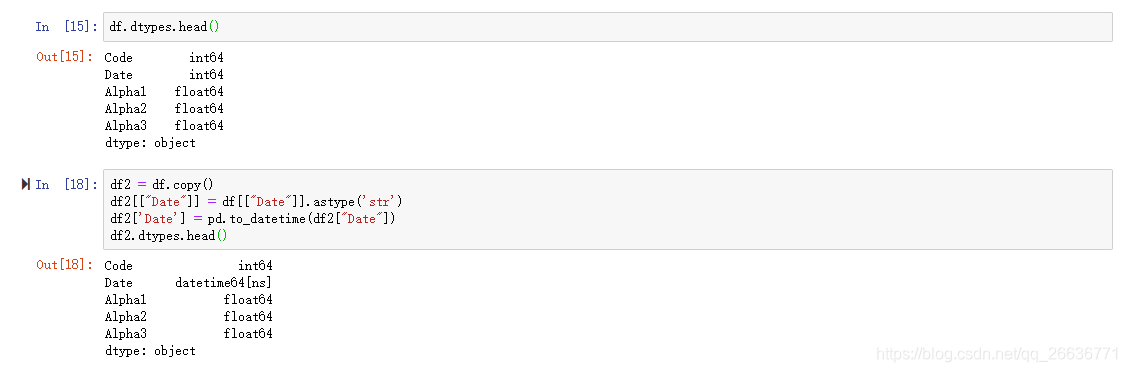
pd.to_datetime方法有format参数指定格式(如:format="%y/%m/%d)
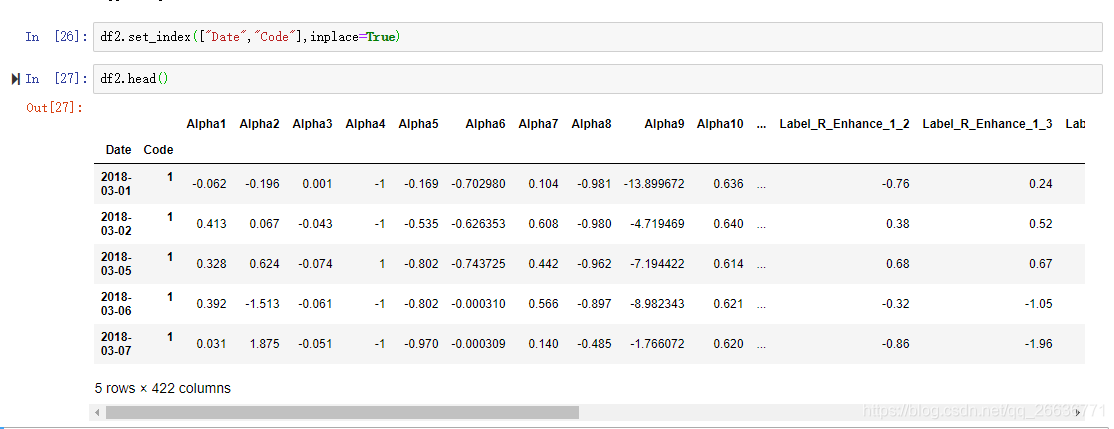
4.设置index
5.排序

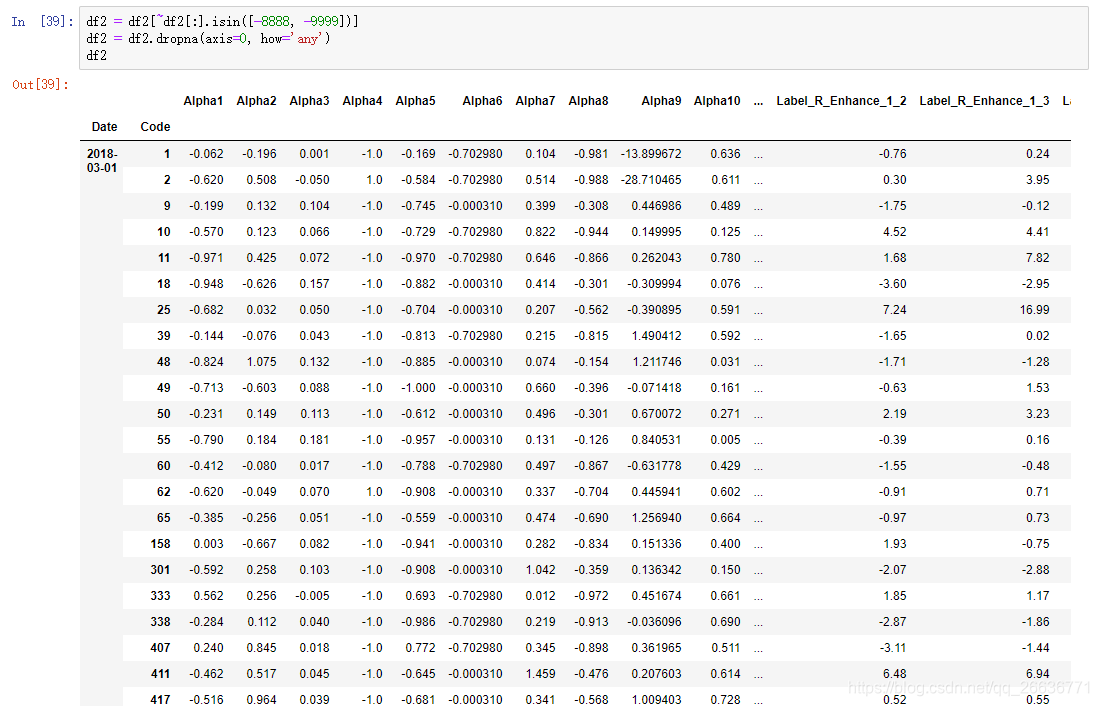
6.按条件删除行
机器学习因子预处理时,判断每一行数据是否出现一个异常值,有异常值则去除整行,例程文件中指为-8888,-9999为异常值。
7.数据筛选
数据筛选在官网已有比较具体的事例说明,不再赘述,这里简单整理下筛选逻辑:
obj[val]-----------选取DataFrame的单个列或一组列,在一些情况下会比较便利:布尔型数组(过滤行)、切片(行切片)、布尔型DataFrame
obj.ix[val]---------------选取DataFrame的单个行或一组行
obj.ix[:,val]----------------选取单个列或列的子集
obj.ix[val1,val2]------------同时选择行和列
reindex方法-----------------将一个或多个轴匹配到新索引
xs---------------------根据标签选取单行或单列,并返回一个Series
icol、irow方法---------------根据整数位置选取单列或单行,并返回一个Series
get_value、set_value------------根据行标签和列标签选取、重置单个值
8.数据修改
对列数据修改
new_data[“Code”] = ["%06d.SK" % i for i in new_data[“Code”]]
简单补充
df.info()->查看数据描述
df.loc[index_value]->查找某个index值的所有行
set(df.index.tolist())->获取无重复值的index列表
pd.read_csv(“20180101.csv”,names = [‘a’,‘b’,‘c’], dtype=str)//添加列名 以字符串形式读取内容
os.path.join(filefold, file)->合并路径
df.hist() -> 画出每个数值列的分布图














 5158
5158











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









