







☠博主专栏 : <mysql高手> <elasticsearch高手> <源码解读> <java核心> <面试攻关>
♝博主的话 : 搬的每块砖,皆为峰峦之基;公众号搜索「码到三十五」关注这个爱发技术干货的coder,一起筑基
在现代企业应用中,批处理是一个不可或缺的部分,它负责处理大量数据的定期、重复或一次性任务。为了满足这种需求,Spring家族提供了一个强大的批处理框架——Spring Batch。本文将带您深入了解Spring Batch的核心概念、架构以及如何使用它来构建高效的批处理应用程序。
一、Spring Batch简介
Spring Batch是一个开源的、轻量级的批处理框架,它基于Spring框架构建,继承了Spring的诸多优点,如依赖注入、面向切面编程等。Spring Batch旨在简化批处理应用程序的开发,提供了一套丰富的功能来支持事务管理、作业调度、异常处理、日志记录等。
Spring Batch是一个完善的批处理框架,旨在帮助企业建立健壮、高效的批处理应用。它是Spring的一个子项目,使用Java语言并基于Spring框架为基础开发,使得已经使用Spring框架的开发者或者企业更容易访问和利用企业服务。Spring Batch提供了大量可重用的组件,包括日志、追踪、事务、任务作业统计、任务重启、跳过、重复、资源管理,能够支持简单的、复杂的和大数据量的批处理作业,同时也提供了优化和分片技术用于实现高性能的批处理任务。
二、Spring Batch的核心概念
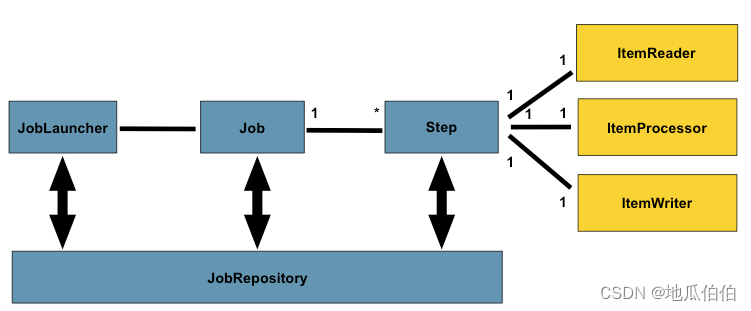
-
Job:作业是批处理的核心概念,它代表了一个完整的批处理任务。一个作业由一个或多个步骤(Step)组成,这些步骤按照特定的顺序执行。
-
Step:步骤是作业的基本构建块,它定义了一个独立的、原子性的操作。每个步骤都包含一个ItemReader、一个ItemProcessor(可选)和一个ItemWriter。
-
ItemReader:负责从数据源读取数据,每次读取一条记录。读取的数据被封装在一个对象中,该对象将传递给ItemProcessor和ItemWriter。
-
ItemProcessor(可选):对从ItemReader读取的数据进行处理或转换。处理后的数据将被传递给ItemWriter。
-
ItemWriter:负责将数据写入目标系统。它接收从ItemProcessor传递过来的数据,并将其写入指定的数据存储或系统中。
三、Spring Batch的架构
Spring Batch的架构分为三层:应用层、核心层和基础层。

-
应用层:包含了所有自定义的批处理作业和业务流程代码。开发者根据具体需求编写作业配置、定义步骤、读写器等。
-
核心层:提供了启动和管理批处理作业的运行环境。核心层包含了JobLauncher、JobRepository等重要组件,负责作业的调度、执行和状态管理。
-
基础层:提供了基础的读写器、处理器和写入器实现,以及重试、跳过等异常处理机制。基础层还提供了对数据库、文件系统等数据源的支持。
四、使用Spring Batch构建批处理应用程序
使用Spring Batch构建批处理应用程序通常涉及以下步骤:
-
配置数据源:Spring Batch需要数据库来存储作业执行过程中的元数据和状态信息。因此,首先需要配置数据源连接信息。
-
定义作业和步骤:根据业务需求编写作业配置,定义作业包含的步骤以及每个步骤的读写器和处理器。
-
编写自定义的读写器和处理器:根据数据源和目标系统的特性,编写自定义的ItemReader、ItemProcessor和ItemWriter实现。
-
配置作业启动器:配置JobLauncher来启动和管理作业的执行。可以通过命令行、REST API或定时任务等方式触发作业启动。
-
运行和监控作业:启动应用程序后,可以运行和监控批处理作业的执行情况。Spring Batch提供了丰富的日志和统计信息来帮助开发者诊断问题和优化性能。
以下是一个Spring Batch的复杂案例,该案例模拟了一个数据处理流程,包括从数据库读取数据、对数据进行处理、然后将处理后的数据写入到另一个数据库表中。这个案例涵盖了Spring Batch的大部分核心概念,包括Job、Step、ItemReader、ItemProcessor和ItemWriter。
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.EnableBatchProcessing;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepScope;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.core.step.builder.StepBuilder;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JdbcBatchItemWriter;
import org.springframework.batch.item.database.JdbcCursorItemReader;
import org.springframework.batch.item.database.builder.JdbcBatchItemWriterBuilder;
import org.springframework.batch.item.database.builder.JdbcCursorItemReaderBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
import javax.sql.DataSource;
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
// 定义数据源,这里使用内存数据库H2作为示例
@Bean
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1");
dataSource.setUsername("sa");
dataSource.setPassword("");
return dataSource;
}
// 定义JdbcTemplate,用于执行SQL语句
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
// 定义ItemReader,从source_table表中读取数据
@Bean
public ItemReader<MyData> itemReader(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<MyData>()
.dataSource(dataSource)
.sql("SELECT id, data FROM source_table")
.rowMapper(new MyDataRowMapper())
.build();
}
// 定义ItemProcessor,对读取的数据进行处理
@Bean
@StepScope
public ItemProcessor<MyData, MyData> itemProcessor() {
return new MyDataItemProcessor();
}
// 定义ItemWriter,将处理后的数据写入到target_table表中
@Bean
public ItemWriter<MyData> itemWriter(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<MyData>()
.dataSource(dataSource)
.sql("INSERT INTO target_table (id, processed_data) VALUES (:id, :processedData)")
.beanMapped()
.build();
}
// 定义Step,将reader、processor和writer组合起来
@Bean
public Step step1(ItemReader<MyData> reader, ItemProcessor<MyData, MyData> processor, ItemWriter<MyData> writer) {
return StepBuilder.create("step1")
.<MyData, MyData>chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
// 定义Job,包含上面定义的Step
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, @Qualifier("step1") Step step1) {
return jobBuilderFactory.get("myJob")
.incrementer(new RunIdIncrementer())
.flow(step1)
.end()
.build();
}
// MyData类表示读取和处理的数据对象
public static class MyData {
private Long id;
private String data;
// getters and setters
}
// MyDataRowMapper类用于将数据库行映射为MyData对象
public static class MyDataRowMapper implements org.springframework.jdbc.core.RowMapper<MyData> {
@Override
public MyData mapRow(org.springframework.jdbc.core.ResultSet rs, int rowNum) throws java.sql.SQLException {
MyData myData = new MyData();
myData.setId(rs.getLong("id"));
myData.setData(rs.getString("data"));
return myData;
}
}
// MyDataItemProcessor类实现了ItemProcessor接口,对MyData对象进行处理
public static class MyDataItemProcessor implements ItemProcessor<MyData, MyData> {
@Override
public MyData process(MyData item) throws Exception {
// 对item进行处理,例如修改data字段的值
item.setData(item.getData().toUpperCase());
return item;
}
}
}
首先定义了一个数据源,然后定义了一个JdbcTemplate用于执行SQL语句。接着,我们定义了ItemReader、ItemProcessor和ItemWriter,分别用于读取数据、处理数据和写入数据。然后,我们定义了一个Step,将reader、processor和writer组合起来。最后,我们定义了一个Job,包含了上面定义的Step。
另外,上面的代码中使用了@StepScope注解来定义ItemProcessor的作用域为Step作用域。这是因为ItemProcessor通常是无状态的,可以在多个Step之间共享。但是,在某些情况下,我们可能需要在每个Step中使用不同的ItemProcessor实例。这时,就可以使用@StepScope注解来定义ItemProcessor的作用域为Step作用域。这样,每个Step都会创建一个新的ItemProcessor实例。但是在这个例子中,其实并没有必要使用@StepScope,因为我们的ItemProcessor是无状态的,可以在多个Step之间共享。这里只是为了演示如何使用@StepScope注解而加上去的。在实际应用中,应该根据具体的需求来决定是否使用@StepScope注解。
五、应用场景
1. 定期提交批处理任务:Spring Batch允许你定期(例如每天、每周等)提交批处理任务,这些任务可以按照预定的时间自动执行。
2. 并行批处理:Spring Batch支持并行处理,这意味着你可以同时处理多个任务,从而提高处理效率。
3. 企业消息驱动处理:Spring Batch可以与企业消息系统(如JMS)集成,以便在接收到特定消息时触发批处理任务。
4. 大规模并行批处理:对于需要处理大量数据的情况,Spring Batch提供了优化和分片技术,以实现高性能的批处理任务。
5. 失败后手动或定时重启:如果批处理任务失败,Spring Batch允许你手动或定时重启任务,以确保数据处理的完整性和一致性。
6. 按顺序处理依赖的任务:Spring Batch支持按顺序处理依赖的任务,这意味着你可以确保在处理后续任务之前,前置任务已经成功完成。
7. 部分处理:跳过记录:在批处理过程中,如果遇到错误或异常,Spring Batch允许你跳过当前记录并继续处理后续记录,而不是中断整个批处理任务。
8. 批处理事务:Spring Batch提供了强大的事务管理能力,可以确保在批处理过程中数据的一致性和完整性。
总的来说,Spring Batch适用于需要处理大量数据、执行周期性任务、与企业消息系统集成、要求数据一致性和完整性等场景。它可以帮助企业建立健壮、高效的批处理应用,提高数据处理效率和质量。
六、总结
Spring Batch是一个功能强大、易于使用的批处理框架,它简化了批处理应用程序的开发过程,提供了丰富的功能和特性来支持各种复杂的业务场景。通过深入了解Spring Batch的核心概念和架构,开发者可以更加高效地构建健壮、可扩展的批处理应用程序。


















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











