







我们先说一下File类,毕竟io都是针对File来着。
构造函数
File(String pathname)
File f1 =new File("c:\\abc\\1.txt");
//File(String parent,String child)
File f2 =new File("c:\\abc","2.txt");
//File(File parent,String child)
File f3 =new File("c:"+File.separator+"abc");//separator 跨平台分隔符
File f4 =new File(f3,"3.txt");
System.out.println(f1);//c:\abc\1.txt创建方法
1.boolean createNewFile() 不存在返回true 存在返回false
2.boolean mkdir() 创建目录
3.boolean mkdirs() 创建多级目录删除方法
1.boolean delete()
2.boolean deleteOnExit() 文件使用完成后删除判断方法
1.boolean canExecute()判断文件是否可执行
2.boolean canRead()判断文件是否可读
3.boolean canWrite() 判断文件是否可写
4.boolean exists() 判断文件是否存在
5.boolean isDirectory()
6.boolean isFile()
7.boolean isHidden()
8.boolean isAbsolute()判断是否是绝对路径 文件不存在也能判断获取方法
1.String getName()
2.String getPath()
3.String getAbsolutePath()
4.String getParent()//如果没有父目录返回null
5.long lastModified()//获取最后一次修改的时间
6.long length()
7.boolean renameTo(File f)
8.File[] liseRoots()//获取机器盘符
9.String[] list()
10.String[] list(FilenameFilter filter)列出磁盘下的文件和文件夹
public class FileDemo3 {
public static void main(String[] args){
File[] files =File.listRoots();
for(File file:files){
System.out.println(file);
if(file.length()>0){
String[] filenames =file.list();
for(String filename:filenames){
System.out.println(filename);
}
}
}
}
}文件过滤
import java.io.File;
import java.io.FilenameFilter;
public class FileDemo4 {
public static void main(String[] args){
File[] files =File.listRoots();
for(File file:files){
System.out.println(file);
if(file.length()>0){
String[] filenames =file.list(new FilenameFilter(){
//file 过滤目录 name 文件名
public boolean accept(File file,String filename){
return filename.endsWith(".mp3");
}
});
for(String filename:filenames){
System.out.println(filename);
}
}
}
}
}File[] listFiles()
File[] listFiles(FilenameFilter filter)
利用递归列出全部文件
public class FileDemo5 {
public static void main(String[] args){
File f =new File("e:\\音樂");
showDir(f);
}
public static void showDir(File dir){
System.out.println(dir);
File[] files =dir.listFiles();
for(File file:files){
if(file.isDirectory())
showDir(file);
else
System.out.println(file);
}
}
}欧卡了,下面进入我们今天的主题。不废话先上图
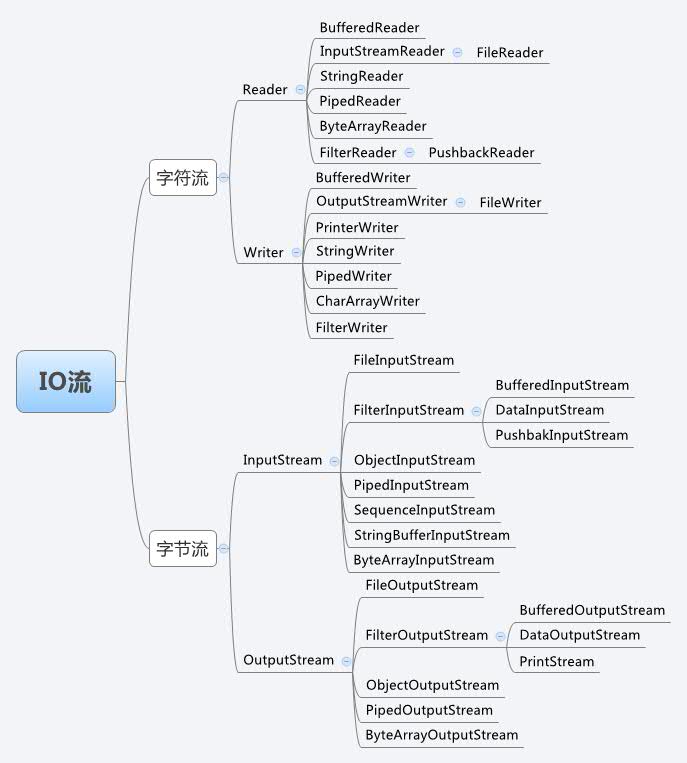
IO流的分类
根据处理数据类型的不同分为:字符流和字节流
根据数据流向不同分为:输入流和输出流
字符流和字节流
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。 字节流和字符流的区别:
读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。
输入流和输出流
对输入流只能进行读操作,对输出流只能进行写操作,程序中需要根据待传输数据的不同特性而使用不同的流。
Java IO流对象
1.输入字节流InputStream IO 中输入字节流的继承图可见上图,可以看出:
InputStream 是所有的输入字节流的父类,它是一个抽象类。
ByteArrayInputStream、StringBufferInputStream、FileInputStream 是三种基本的介质流,它们分别从Byte 数组、StringBuffer、和本地文件中读取数据。PipedInputStream 是从与其它线程共用的管道中读取数据,与Piped 相关的知识后续单独介绍。
ObjectInputStream 和所有FilterInputStream 的子类都是装饰流(装饰器模式的主角)。
2.输出字节流OutputStream
IO 中输出字节流的继承图可见上图,可以看出:
OutputStream 是所有的输出字节流的父类,它是一个抽象类。
ByteArrayOutputStream、FileOutputStream 是两种基本的介质流,它们分别向Byte 数组、和本地文件中写入数据。PipedOutputStream 是向与其它线程共用的管道中写入数据,
ObjectOutputStream 和所有FilterOutputStream 的子类都是装饰流。
3.字符输入流Reader
在上面的继承关系图中可以看出:
Reader 是所有的输入字符流的父类,它是一个抽象类。
CharReader、StringReader 是两种基本的介质流,它们分别将Char 数组、String中读取数据。PipedReader 是从与其它线程共用的管道中读取数据。
BufferedReader 很明显就是一个装饰器,它和其子类负责装饰其它Reader 对象。
FilterReader 是所有自定义具体装饰流的父类,其子类PushbackReader 对Reader 对象进行装饰,会增加一个行号。
InputStreamReader 是一个连接字节流和字符流的桥梁,它将字节流转变为字符流。FileReader 可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream 转变为Reader 的方法。我们可以从这个类中得到一定的技巧。Reader 中各个类的用途和使用方法基本和InputStream 中的类使用一致。后面会有Reader 与InputStream 的对应关系。
4.字符输出流Writer
在上面的关系图中可以看出:
Writer 是所有的输出字符流的父类,它是一个抽象类。
CharArrayWriter、StringWriter 是两种基本的介质流,它们分别向Char 数组、String 中写入数据。PipedWriter 是向与其它线程共用的管道中写入数据,
BufferedWriter 是一个装饰器为Writer 提供缓冲功能。
PrintWriter 和PrintStream 极其类似,功能和使用也非常相似。
OutputStreamWriter 是OutputStream 到Writer 转换的桥梁,它的子类FileWriter 其实就是一个实现此功能的具体类(具体可以研究一SourceCode)。功能和使用和OutputStream 极其类似,后面会有它们的对应图。
5、字符流与字节流转换
转换流的特点:
其是字符流和字节流之间的桥梁
可对读取到的字节数据经过指定编码转换成字符
可对读取到的字符数据经过指定编码转换成字节
何时使用转换流?
当字节和字符之间有转换动作时;
流操作的数据需要编码或解码时。
具体的对象体现:
InputStreamReader:字节到字符的桥梁
OutputStreamWriter:字符到字节的桥梁
这两个流对象是字符体系中的成员,它们有转换作用,本身又是字符流,所以在构造的时候需要传入字节流对象进来。
i**o包与设计模式**
对于io包,下面的用法是经常看到的:
InputStream in = new BufferedInputStream(new ObjectInputStream(new FileInputStream(new File(“xxx”))));
示例
public class FileCount {
/**
* 我们写一个检测文件长度的小程序,别看这个程序挺长的,你忽略try catch块后发现也就那么几行而已。
*/
publicstatic void main(String[] args) {
//TODO 自动生成的方法存根
int count=0; //统计文件字节长度
InputStreamstreamReader = null; //文件输入流
try{
streamReader=newFileInputStream(new File(“D:/David/Java/java 高级进阶/files/tiger.jpg”));
/*1.new File()里面的文件地址也可以写成D:\David\Java\java 高级进阶\files\tiger.jpg,前一个\是用来对后一个
* 进行转换的,FileInputStream是有缓冲区的,所以用完之后必须关闭,否则可能导致内存占满,数据丢失。
*/
while(streamReader.read()!=-1) { //读取文件字节,并递增指针到下一个字节
count++;
}
System.out.println(“—长度是: “+count+” 字节”);
}catch (final IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}finally{
try{
streamReader.close();
}catch (IOException e) {
//TODO 自动生成的 catch 块
e.printStackTrace();
}
}
}
}
我们一步一步来,首先,上面的程序存在问题是,每读取一个自己我都要去用到FileInputStream,我输出的结果是“—长度是: 64982 字节”,那么进行了64982次操作!可能想象如果文件十分庞大,这样的操作肯定会出大问题,所以引出了缓冲区的概念。可以将streamReader.read()改成streamReader.read(byte[]b)此方法读取的字节数目等于字节数组的长度,读取的数据被存储在字节数组中,返回读取的字节数,InputStream还有其他方法mark,reset,markSupported方法,例如:
markSupported 判断该输入流能支持mark 和 reset 方法。
mark用于标记当前位置;在读取一定数量的数据(小于readlimit的数据)后使用reset可以回到mark标记的位置。
FileInputStream不支持mark/reset操作;BufferedInputStream支持此操作;
mark(readlimit)的含义是在当前位置作一个标记,制定可以重新读取的最大字节数,也就是说你如果标记后读取的字节数大于readlimit,你就再也回不到回来的位置了。
通常InputStream的read()返回-1后,说明到达文件尾,不能再读取。除非使用了mark/reset。
6、RandomAccessFile类
该对象并不是流体系中的一员,其封装了字节流,同时还封装了一个缓冲区(字符数组),通过内部的指针来操作字符数组中的数据。 该对象特点:
该对象只能操作文件,所以构造函数接收两种类型的参数:a.字符串文件路径;b.File对象。
该对象既可以对文件进行读操作,也能进行写操作,在进行对象实例化时可指定操作模式(r,rw)
注意:该对象在实例化时,如果要操作的文件不存在,会自动创建;如果文件存在,写数据未指定位置,会从头开始写,即覆盖原有的内容。 可以用于多线程下载或多个线程同时写数据到文件。
什么是阻塞IO?什么是非阻塞IO?
在了解阻塞IO和非阻塞IO之前,先看下一个具体的IO操作过程是怎么进行的。
通常来说,IO操作包括:对硬盘的读写、对socket的读写以及外设的读写。
当用户线程发起一个IO请求操作(本文以读请求操作为例),内核会去查看要读取的数据是 否就绪,对于阻塞IO来说,如果数据没有就绪,则会一直在那等待,直到数据就绪;对于非阻塞IO来说,如果数据没有就绪,则会返回一个标志信息告知用户线 程当前要读的数据没有就绪。当数据就绪之后,便将数据拷贝到用户线程,这样才完成了一个完整的IO读请求操作,也就是说一个完整的IO读请求操作包括两个 阶段:
1)查看数据是否就绪;
2)进行数据拷贝(内核将数据拷贝到用户线程)。
那么阻塞(blocking IO)和非阻塞(non-blocking IO)的区别就在于第一个阶段,如果数据没有就绪,在查看数据是否就绪的过程中是一直等待,还是直接返回一个标志信息。
Java中传统的IO都是阻塞IO,比如通过socket来读数据,调用read()方 法之后,如果数据没有就绪,当前线程就会一直阻塞在read方法调用那里,直到有数据才返回;而如果是非阻塞IO的话,当数据没有就绪,read()方法 应该返回一个标志信息,告知当前线程数据没有就绪,而不是一直在那里等待。
什么是同步IO?什么是异步IO?
从字面的意思可以看出:同步IO即 如果一个线程请求进行IO操作,在IO操作完成之前,该线程会被阻塞;
而异步IO为 如果一个线程请求进行IO操作,IO操作不会导致请求线程被阻塞。
事实上,同步IO和异步IO模型是针对用户线程和内核的交互来说的:
对于同步IO:当用户发出IO请求操作之后,如果数据没有就绪,需要通过用户线程或者内核不断地去轮询数据是否就绪,当数据就绪时,再将数据从内核拷贝到用户线程;
而异步IO:只有IO请求操作的发出是由用户线程来进行的,IO操作的两个阶段都是由内核自动完成,然后发送通知告知用户线程IO操作已经完成。也就是说在异步IO中,不会对用户线程产生任何阻塞。
这是同步IO和异步IO关键区别所在,同步IO和异步IO的关键区别反映在数据拷贝阶段是由用户线程完成还是内核完成。所以说异步IO必须要有操作系统的底层支持。
注意同步IO和异步IO与阻塞IO和非阻塞IO是不同的两组概念。
阻塞IO和非阻塞IO是反映在当用户请求IO操作时,如果数据没有就绪,是用户线程一直等待数据就绪,还是会收到一个标志信息这一点上面的。也就是说,阻塞IO和非阻塞IO是反映在IO操作的第一个阶段,在查看数据是否就绪时是如何处理的。















 4555
4555











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









