







1 前言
在讲述Hadoop集群搭建之前,首先要了解Hadoop和集群两个名词,Hadoop是由Apache基金会开发的分布式系统基础架构,简单理解就是大数据技术应用的基础。集群可以理解为多台装有hadoop的服务器。搭建Hadoop集群的目的就是为了管理多台服务器,使多台服务器之间能够协调工作。本文选择了3台阿里云服务器。从下图中可以对整个大数据架构有了大体的了解。
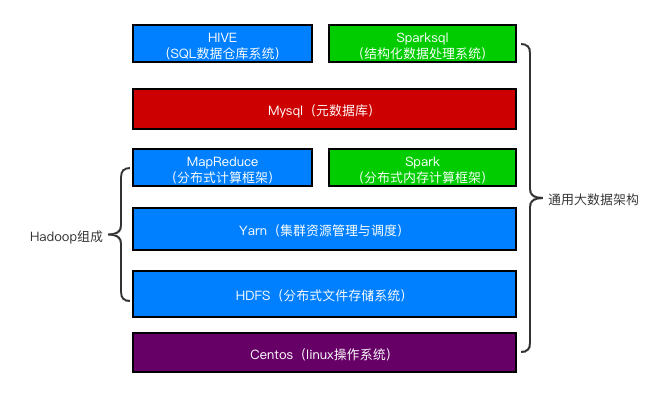
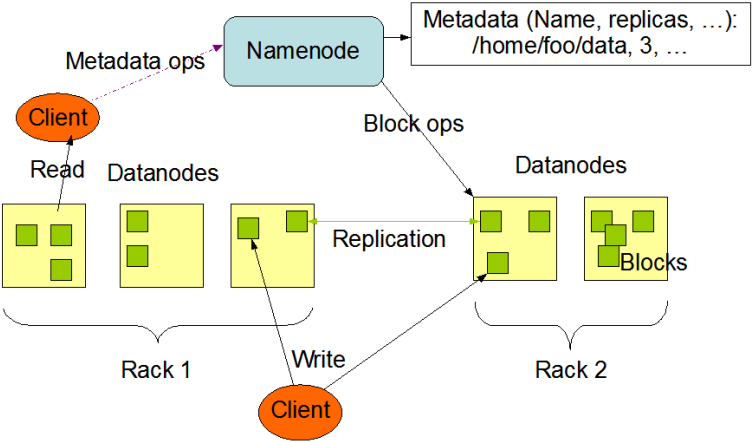
Hadoop主要有HDFS(分布式文件存储系统)、Yarn(集群资源管理与调度)和MapReduce(分布式计算框架)组成。Hadoop集群中分为主机(master)和从机(slave),本文配置一台阿里云服务器为主机和从机。其余两台为从机。HDFS(分布式文件存储系统)在主机上称为Namenode节点,在从机上称为Datanode节点。Namenode维护HDFS的文件系统树以及文件树中所有的文件和文件夹的元数据。可以理解为win系统中文件夹属性中的那些信息,Datanode是存储和检索数据的地方。可以理解为win系统中文件夹中实际数据。
Yarn(集群资源管理与调度)在主机上称为ResourceManager节点,在从机上称为NodeManager。ResourceManager是全局的资源管理器,负责整个系统的资源管理和分配,NodeManager是节点上的资源和任务管理器。定时地向ResourceManager汇报本节点的资源使用情况。
MapReduce(分布式计算框架)顾名思义就是计算框架,有啥特点呢,就是分布式,可以把大型数据处理任务分解成很多单个简单的任务,然后再把各个处理结果合在一起。计算过程可以百度了解。
2 Hadoop集群搭建
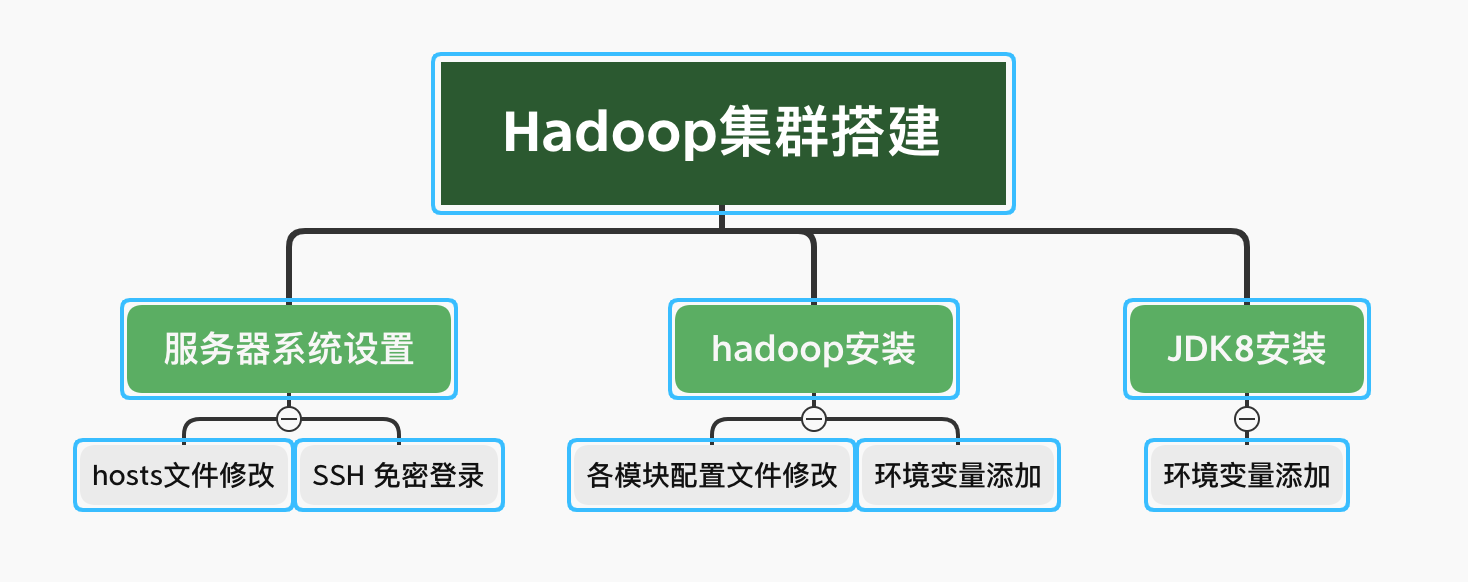
2.1 服务器系统设置
网上教程多采用虚拟机创建多个linux系统来搭建Hadoop集群,我觉得虚拟机有弊端就采用了阿里云服务器。阿里云服务器购买选配过程后续再介绍。
- hosts文件修改
hosts是一个没有扩展名的系统文件,其基本作用就是将一些常用的网址域名与其对应的 IP 地址建立一个关联“ 数据库 ”。当用户在浏览器中输入一个需要登录的网址时,系统会首先自动从hosts文件中寻找对应的 IP 地址,一旦找到,系统就会立即打开对应网页,如果没有找到,则系统会将网址提交 DNS 域名解析服务器进行 IP 地址的解析。就如你访问本地的时候,你输入127.0.0.1和localhost是一致的。hosts文件修改就是在添加三台服务器IP和域名的映射。vi /etc/hosts添加一下映射
172.27.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1646
1646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









