







 本文介绍了Java中的IO/NIO模型,包括阻塞IO、非阻塞IO和多路复用IO。重点讲解了Java NIO的三大核心组件:Channel、Buffer和Selector,阐述了NIO如何通过Selector实现单线程管理多个通道,提高系统效率。同时,文章提到了NIO在处理大量连接时的优势,以及与传统IO的区别。
本文介绍了Java中的IO/NIO模型,包括阻塞IO、非阻塞IO和多路复用IO。重点讲解了Java NIO的三大核心组件:Channel、Buffer和Selector,阐述了NIO如何通过Selector实现单线程管理多个通道,提高系统效率。同时,文章提到了NIO在处理大量连接时的优势,以及与传统IO的区别。
阻塞IO模型
- 最传统的一种IO模型,即在读写数据过程中会发生阻塞现象。当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待数据就绪,而用户线程就会处于阻塞状态,用户线程交出CPU。当数据就绪之后,内核会将数据拷贝到用户线程,并返回结果给用户线程,用户线程才解除block状态。典型的阻塞IO模型的例子为:data = socket.read();如果数据没有就绪,就会一直阻塞在read方法。
非阻塞IO模型
- 当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。典型的非阻塞IO模型一般如下:
while(true){
data = socket.read();
if(data!= error){
处理数据
break;
}
}
- 但是对于非阻塞IO就有一个非常严重的问题,在while循环中需要不断地去询问内核数据是否就绪,这样会导致CPU占用率非常高,因此一般情况下很少使用while循环这种方式来读取数据。
多路复用IO模型
- 多路复用IO模型是目前使用得比较多的模型。Java NIO实际上就是多路复用IO。在多路复用IO模型中,会有一个线程不断去轮询多个socket的状态,只有当socket真正有读写事件时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有在真正有socket读写事件进行时,才会使用IO资源,所以它大大减少了资源占用。在Java NIO中,是通过selector.select()去查询每个通道是否有到达事件,如果没有事件,则一直阻塞在那里,因此这种方式会导致用户线程的阻塞。多路复用IO模式,通过一个线程就可以管理多个socket,只有当socket真正有读写事件发生才会占用资源来进行实际的读写操作。因此,多路复用IO比较适合连接数比较多的情况。 另外多路复用IO为何比非阻塞IO模型的效率高是因为在非阻塞IO中,不断地询问socket状态时通过用户线程去进行的,而在多路复用IO中,轮询每个socket状态是内核在进行的,这个效率要比用户线程要高的多。 不过要注意的是,多路复用IO模型是通过轮询的方式来检测是否有事件到达,并且对到达的事件逐一进行响应。因此对于多路复用IO模型来说,一旦事件响应体很大,那么就会导致后续的事件迟迟得不到处理,并且会影响新的事件轮询。
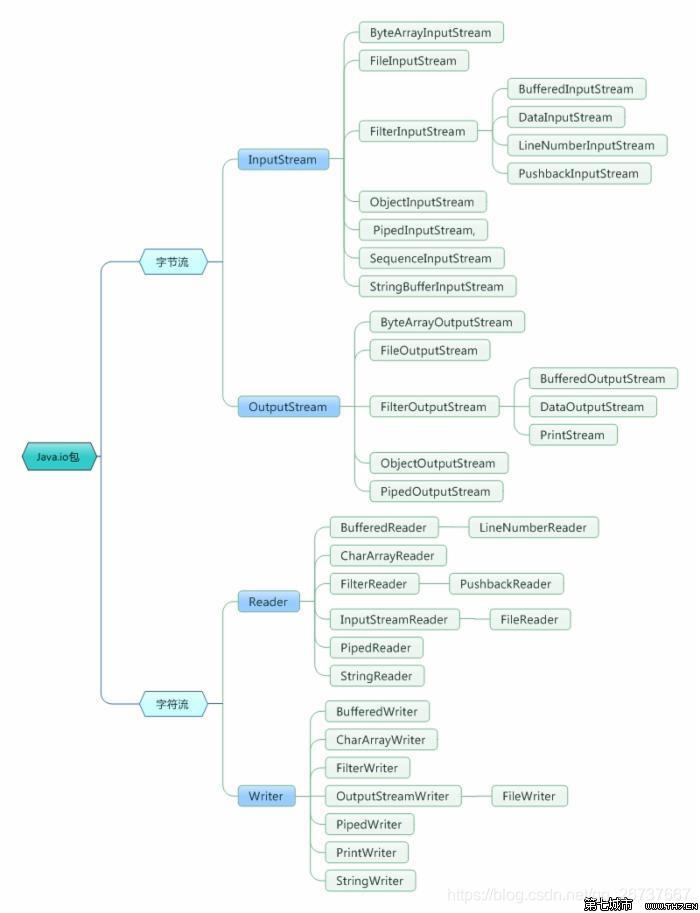
java IO包
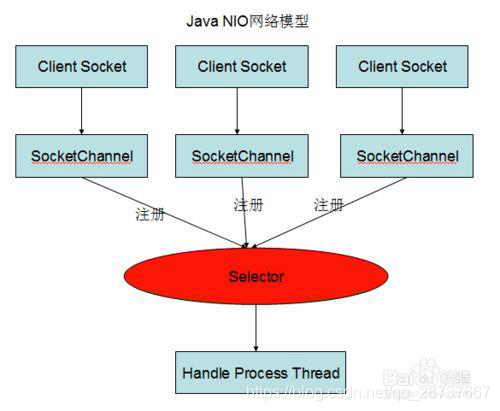
JAVA NIO
- NIO主要有三大核心部分:Channel(通道),Buffer(缓冲区), Selector。传统IO基于字节流和字符流进行操作,而NIO基于Channel和Buffer(缓冲区)进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector(选择区)用于监听多个通道的事件(比如:连接打开,数据到达)。因此,单个线程可以监听多个数据通道。NIO和传统IO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
NIO的缓冲区
- Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。NIO的缓冲导向方法不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
NIO包
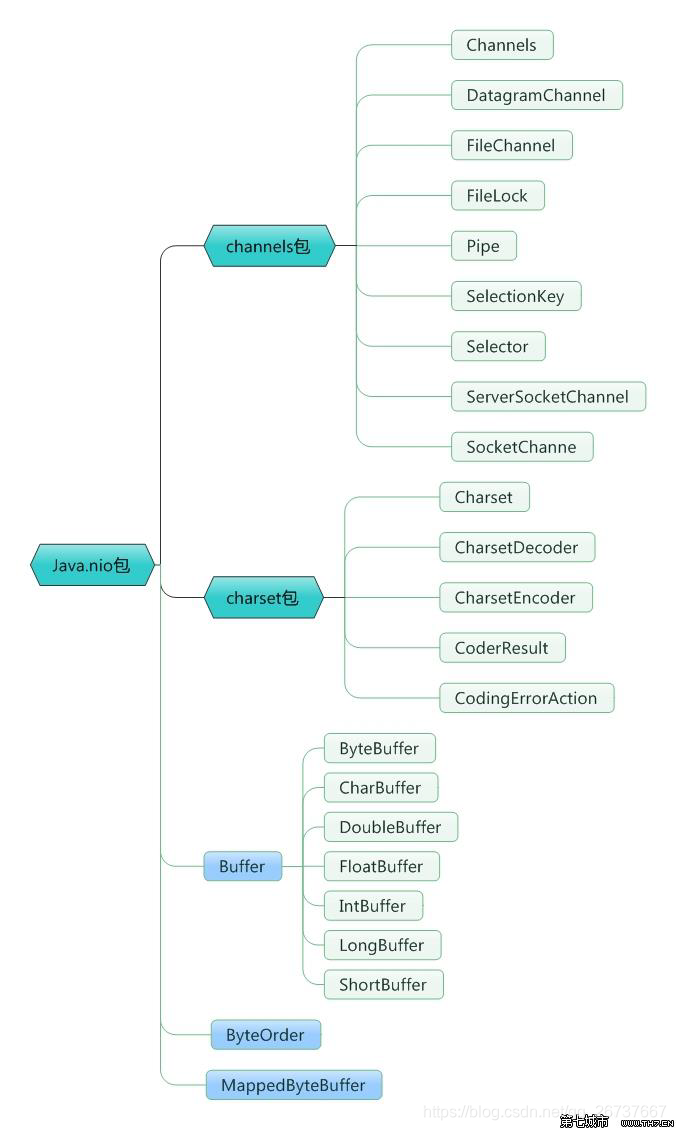
Channel
首先说一下Channel,国内大多翻译成“通道”。Channel和IO中的Stream(流)是差不多一个等级的。只不过Stream是单向的,譬如:InputStream, OutputStream,而Channel是双向的,既可以用来进行读操作,又可以用来进行写操作。 NIO中的Channel的主要实现有:
- FileChannel
- DatagramChannel
- SocketChannel
- ServerSocketChannel
这里看名字就可以猜出个所以然来:分别可以对应文件IO、UDP和TCP(Server和Client
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2138
2138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









