







什么是正则表达式
描述字符模式的对象 ECMA提供RegExp来表示正则表达式。string和RegExp都定义使用正则表达式的进行强大的模式匹配
创建正则表达式
创建正则表达式的方式:
1、new运算符
第一个参数为字符串
第二个参数为可选模式的修饰符 i忽略大小写 g全局匹配 m多行匹配
var box=new RegExp('box');
var box1=new RegExp('box','ig'); 2、字面量的方式
var box=/box/;
var box1=/box/ig;测试正则表达式 –RegExp对象的函数
1、test()方法返回的是true或者false
var box=/box/;
var box1=/box/ig;
console.log(box.test("sasbx2121")); //true
console.log(box.test("sasbox2121")); //false2、exec()方法以数组的方式返回匹配字符串以后的相关信息
var box=/box/;
var box1=/box/ig;
console.log(box.exec("sasbx2121")); //null
console.log(box.exec("sasbox2121"));
//["box", index: 3, input: "sasbox2121"]使用字符串的正则表达式的方法
1、match(正则表达式)方法
返回的是一个匹配过后的匹配的相关的信息 数组
var box=/box/;
var box1=/box/ig;
var str="hello box,Box"
console.log(str.match(box).length); //1
console.log(str.match(box1).length); //22、search(正则表达式)方法
返回的是第一次在字符串中找到的子串的位置 数字
var box=/box/;
var box1=/box/ig;
var str="hello box,Box"
console.log(str.search(box)); //6
console.log(str.search(box1)); //63、replace(正则表达式,被替换的数据)方法
var box=/box/;
var box1=/box/ig;
var str="hello box,Box"
console.log(str.replace(box,'tom')); //hello tom,Box
console.log(str.replace(box1,'tom')); //hello tom,tom4、split(正则表达式) 按他定的规则拆分字符串
var box=/box/;
var str="hello box,Box"
console.log(str.split(box)); //["hello ", ",Box"]RegExp对象的静态属性
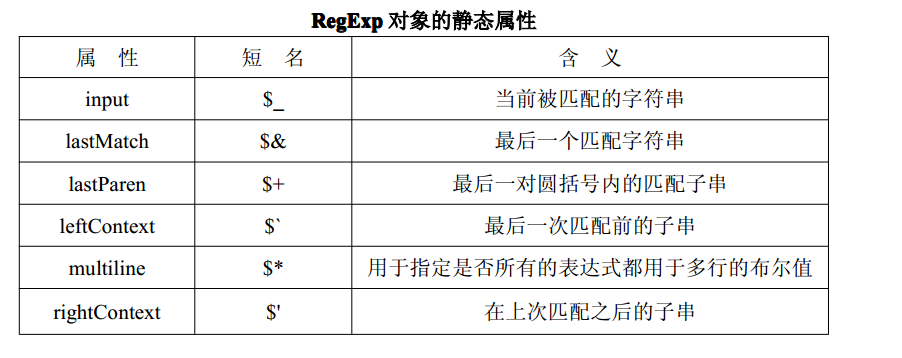
必须执行一下,静态属性才有效
var box=/(b)ox/;
var str="hello box,box";
box.test(str); //执行一下正则表达式
console.log(RegExp.$_); //hello box,box
console.log(RegExp.input); //hello box,box
console.log(RegExp.lastMatch); //box
console.log(RegExp.lastParen);//b
console.log(RegExp.leftContext);//hello注意:
1、使用这些静态的属性的时候必须先执行一下(test或者exec)
2、但是这些静态属性有浏览器兼容问题,
RegExp的实例属性
注意的是lastIndex这个属性为什么和有没有使用正则的test方法有关系?
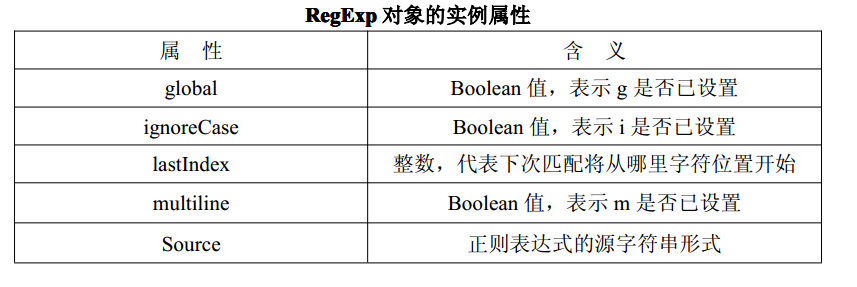
var box=/box/ig;
console.log(box.global); //true
console.log(box.ignoreCase); //true
console.log(box.multiline); //false
console.log(box.lastIndex); //0
console.log(box.source); //box
var patten=/google/g;
var str='google google google';//没有任何的修饰符
console.log(patten.lastIndex) //0
patten.test(str);
console.log(patten.lastIndex) //6
patten.test(str);
console.log(patten.lastIndex) //13获取控制
元字符的使用
元字符:包含特殊含义的字符。
正则表达式元字符是包含特殊含义的字符。可以控制匹配模式。
字符类 单个字符和数字
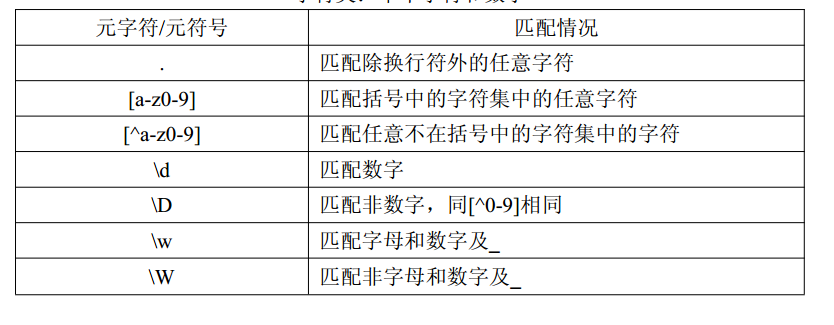
元字符.号的使用
var box=/g...gle/;
var str="go34gle";
console.log(box.test(str)); //true var box=/g[a-zA-Z]gle/; //复合式的
var str1="g3gle";
var str2="gogle";
console.log(box.test(str1)); //false
console.log(box.test(str2)); //true字符类:记录字符
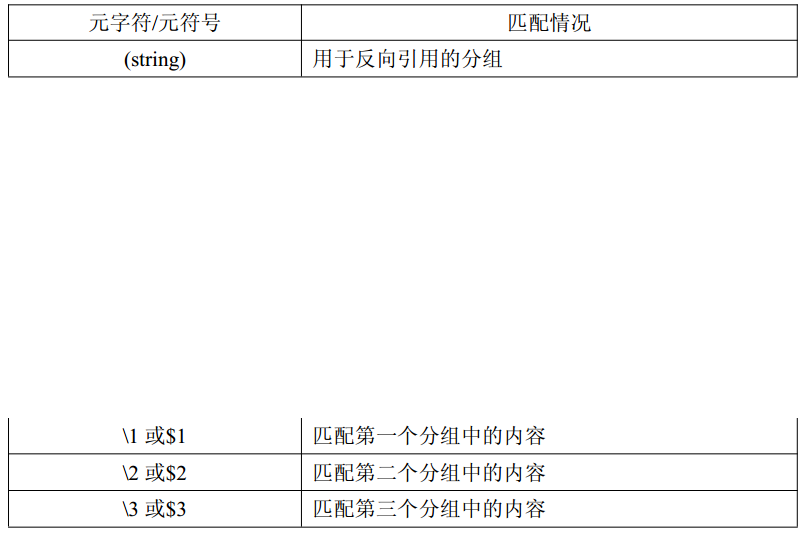
使用记录字符$1,匹配第一个分组中的内容
var pattenr=/8(.*)8/;
var str="8google8djas8sgau";
// pattenr.test(str);
str.match(pattenr);
console.log(RegExp.$1); //google8djas默认的是贪婪匹配使用$2匹配第二个分组中的内容
var ss=/(.*)\s(.*)/;
var str="beijing tianjian"
console.log(str.replace(ss,'$2 $1')); //tianjian beijing注意这必须是RegExp的属性,而不是pattern的属性
空白字符类
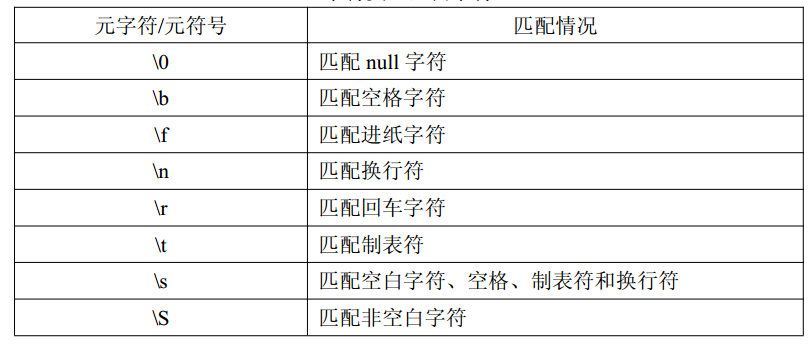
匹配空白字符
var pattenr=/s\b/;
console.log(pattenr.test("s"))或模式的匹配
var pattenr=/google|baidu|soso/;
console.log(pattenr.test("sss")) //false
console.log(pattenr.test("google")) //true字符类 重复字符

var box=/g*gle/;
var str="go34gle";
console.log(box.test(str)); //true
//匹配到o为2-4个多或者少都会返回false
var pattern=/go{2,4}gle/;
var pattern1=/go{2}gle/;
console.log(pattern.test("google")); //匹配到o为2个
var pattern2=/go{2,}gle/;
console.log(pattern2.test("goooogle")); //匹配到o的个数至少为2个分组模式匹配
var pattenr=/(google){4,8}/;
console.log(pattenr.test("googlegooglegooglegoogle")) //true贪婪和惰性

js中正则表达式 的贪婪模式和非他博览模式的区别
1.什么是正则表达式的贪婪与非贪婪匹配
如:String str=”abcaxc”;
Patter p=”ab*c”;
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab*c)。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab*c)。
?会关闭贪婪()
var box1=/[a-z]+?/;
var box2=/[a-z]+/;
var str="sasas12";
console.log(str.replace(box1,"xxx")); //xxxasas12
console.log(str.replace(box2,"xxx")); //xxx12组合使用
var box=/^[a-z]+\s[0-9]{4}$/i ;
var str="google 1234";
console.log(box.exec(str)) ; //["google 1234", index: 0, input: "google 1234"]只匹配字母 这三个表达式都可以做到只匹配字母
var box=/^[a-z]+/i ;
var box=/[A-Z]+/i ;
var box=/^[A-Z]+/i ;使用exec返回数组
var cc=/[a-z]+\s\d{4}/g;
var dd="google 2012";
var aa=cc.exec(dd);
console.log(aa.length);对分组后的模式使用exec
var cc=/([a-z]+)\s(\d{4})/g;
var dd="google 20123";
var aa=cc.exec(dd);
console.log(aa.length);
console.log(aa[0]); //匹配到的字符串
console.log(aa[1]); //第一个分组匹配到的字符串
console.log(aa[2]); //第二个分组匹配到的字符串捕获性分组和非捕获性 分组
捕获型分组
var cc=/(\d+)([a-z])/;
var str="123abc";
var aa=cc.exec(str);
console.log(cc.length);
console.log(aa[0]); //123a
console.log(aa[1]); //123
console.log(aa[2]); //a非捕获型分组
var cc=/(\d+)(?:[a-z])/;
var str="123abc";
var aa=cc.exec(str);
console.log(aa.length);
console.log(aa[0]); //123a
console.log(aa[1]); //123
console.log(aa[2]); //undefined a就不捕获了嵌套分组的exec执行的数组
var cc=/(a?(b?(c?)))/;
var str="abc";
var aa=cc.exec(str);
console.log(aa.length);
console.log(aa[0]); //abc
console.log(aa[1]); //abc
console.log(aa[2]); //bc
console.log(aa[3]); //c常见的正则表达式
邮政编码的模式
要求:必须是6位,必须是数字,第一位不为0
正则表达式: var pattern=/[1-9][0-9]{5}/
压缩文件的文件名
要求:文件名:字母或者数字或者_ .zip .gz .rar
正则表达式:/^[\w-]+.zip|gz|rar/
删除字符串首末的空格
第一种方法:使用两次正则,一个匹配头部,一个匹配尾部。
var pattern=/^\s+/; //匹配头部
var str=" goo gle ";
var result=str.replace(pattern,"");
pattern=/\s+$/;
result=result.replace(pattern,"");
console.log("|"+result+"|");第二种方法:使用非贪婪捕获
var pattern=/^\s+(.+?)\s+$/;
var str=" goo gle ";
var result=pattern.exec(str)[1];
console.log("|"+result+"|");(.+)是贪婪模式 (.+?)是惰性模式
第三种方法:使用惰性+分组的模式
var pattern=/^\s+(.+?)\s+$/;
var str=" goo gle ";
var result=str.replace(pattern,"$1"); //取到的是第一个分组
console.log("|"+result+"|");匹配电子邮件
标准邮箱:yc60.com@mail.com
/^([\w\.\-]+)@(\w\-)+\.([a-zA-Z]{2,4})/














 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









