









讲述完了比较排序以后,我们来看一下非比较排序。
1.计数排序实现
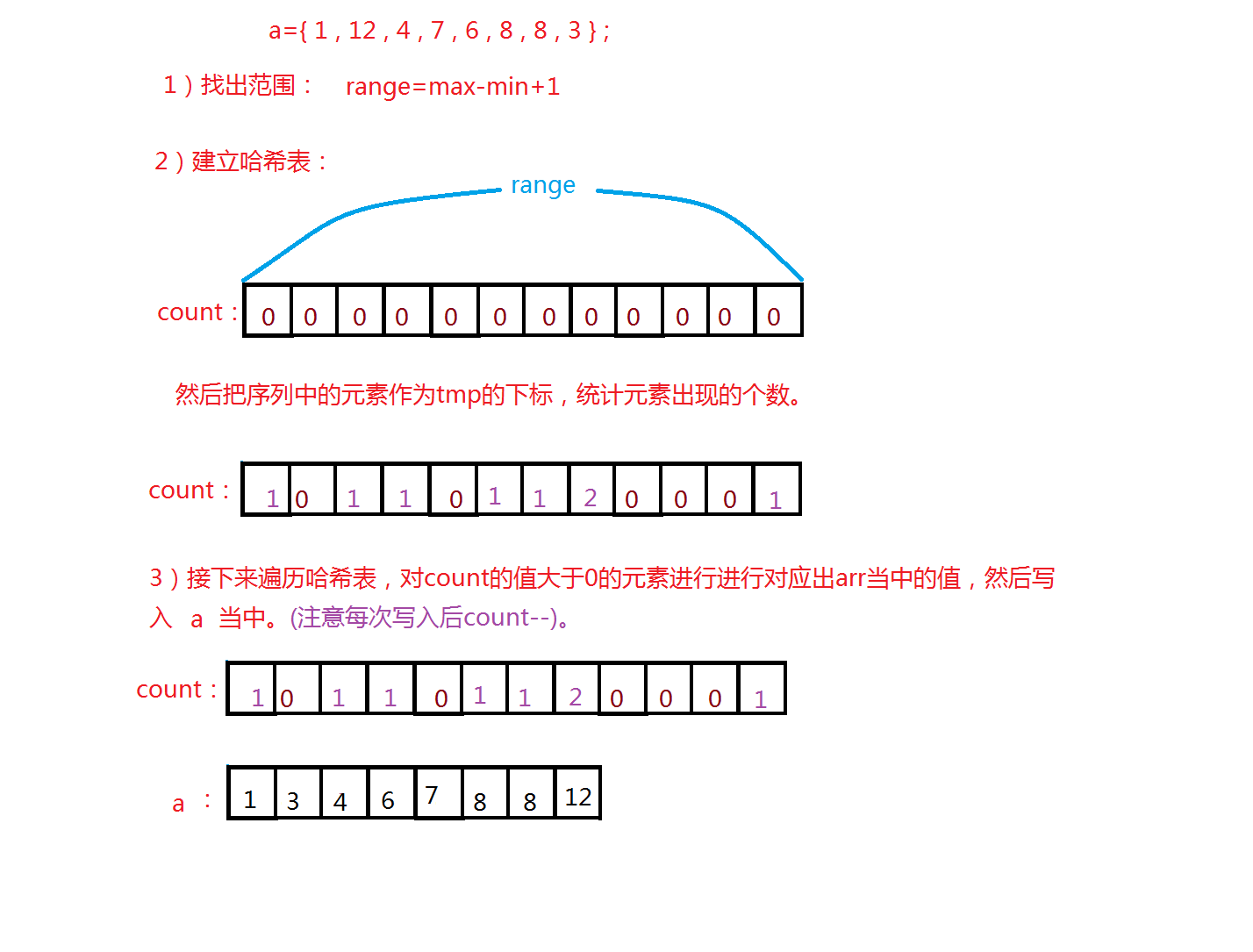
计数排序是一种稳定的排序算法,计数排序实现简单。它算法的步骤是:
1)首先找出序列当中的最大和最小的数,然后通过这两个数确定一个范围,这样就可以直接建立一个范围这么大的哈希表。
2)把数对应哈希表的下标,统计次数。
3)通过哈希表,从小到大进行遍历,然后按哈希表顺序写入序列当中。
示例代码:
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<cstdlib>
#include<cassert>
using namespace std;
//计数排序
//原理:采用哈希表的方式,对应元素,然后将对应元素对应到个数上面,然后按照个数还原出来整个序列,所得到的就是有序的序列。
template<typename T>
void CountSort(T* arr, int n)
{
assert(arr);
//寻找最大和最小的元素,得到范围,方便后续的哈希表的创建。
T min = arr[0];
T max = arr[0];
for (int i = 0; i < n; i++)
{
if (arr[i]>max)
{
max = arr[i];
}
if (arr[i] < min)
{
min = arr[i];
}
}
//范围要+1
int range = max - min + 1;
//创建一个哈希表
T *tmp = new T[range];
memset(tmp, 0, sizeof(T)*range);
//2)把数对应哈希表的下标,统计次数。
for (int i = 0; i < n; i++)
tmp[arr[i] - min]++;
//通过哈希表,从小到大进行遍历,然后按哈希表顺序写入arr当中。
int index = 0;
for (int i = 0; i < range; i++)
{
while (tmp[i]--)
{
arr[index++] = i + min;
}
}
delete[] tmp;
}2.基数排序实现
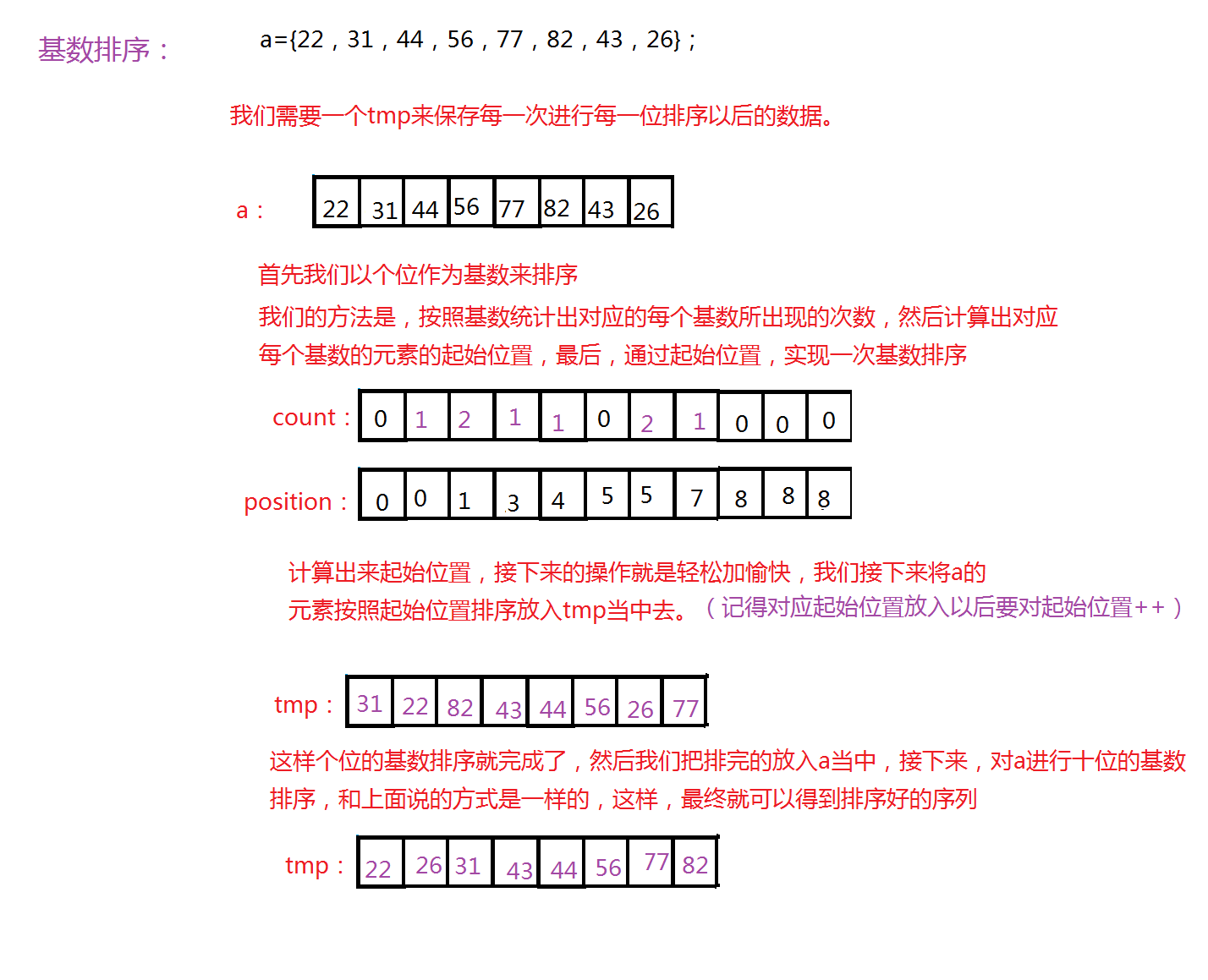
基数排序是一种类似于计数排序的排序方式,它的基本思想是首先选取关键字。
基数的选择和关键字的分解因关键宇的类型而异:
(1) 若关键字是十进制整数,则按个、十等位进行分解。
(2) 若关键字是小写的英文字符串,则rd=26,Co=’a’,C25=’z’,d为字符串的最大长度。
在这里我们来说十进制的基数排序。
我们的思路就是,首先进行低位的基数排序,然后进行高位的基数排序,这样的顺序就是,个位->十位->百位,就这样依次进行下去。
所以我们就这样做。
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<cstdlib>
using namespace std;
//得到最大的位数。
template<typename T>
size_t GetMaxDigit(T *arr, int n)
{
int base = 10;
int digit = 1;
int i = 0;
for (int i = 0; i< n; ++i)
{
while (arr[i] >= base)
{
digit++;
base *= 10;
}
}
return digit;
}
//基数排序:从个位先进行排序,然后依次进行十位,然后依次向前。
template<typename T>
void RadixSort(T* arr, int n)
{
assert(arr);
//得到最大位数
int base = 1;
int digit = GetMaxDigit(arr, n);
int count[10] = { 0 };
int position[10] = { 0 };
T* tmp = new T[n];
while (digit--)
{
memset(count, 0, sizeof(T)* 10);
//统计最低位从0-9的个数
for (int i = 0; i < n; i++)
{
//对应的tmp最低位
count[(arr[i] / base) % 10]++;
}
//计算对应低位的所在起始位置
position[0] = 0;
for (int i = 1; i < 10; i++)
{
position[i] = position[i - 1] + count[i - 1];
}
//进行设置tmp中的数。
for (int i = 0; i < n; i++)
{
int num = (arr[i] / base) % 10;
tmp[position[num]++] = arr[i];
count[num]--;
}
for (int i = 0; i < n; i++)
{
arr[i] = tmp[i];
}
base *= 10;
}
delete[] tmp;
}2.总结
对于计数排序的时间复杂度:O(N+range)空间复杂度O (range)。所以对于技术排序,它的优点是排序会很快,但是缺点就是当range特别大的时候,技术排序效率较低。另外,就是技术排序所排序的需要是整数,这个也就限制了它的场景,所以对于非整数排序,也是需要转换为整数再来进行排序。
对于基数排序的时间复杂度:O(N*最大位数),这个很好理解,就是根据它最大的位数,需要遍历位数次,所以最后就是这样。另外,基数排序的空间复杂度是O(N)。这里是因为借用了中间的tmp。所以在这里也可以看出来这两种排序的时间复杂度都比较高,另外飞比较排序就是范围的限制。有点就是他们时间复杂度都接近O(N),是很快的排序。















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









