






发现问题
业务同学反馈配置的xxl任务在18点45分之后就没有自动执行了,导致业务付款结果更新不及时
控制台手动执行任务是可以的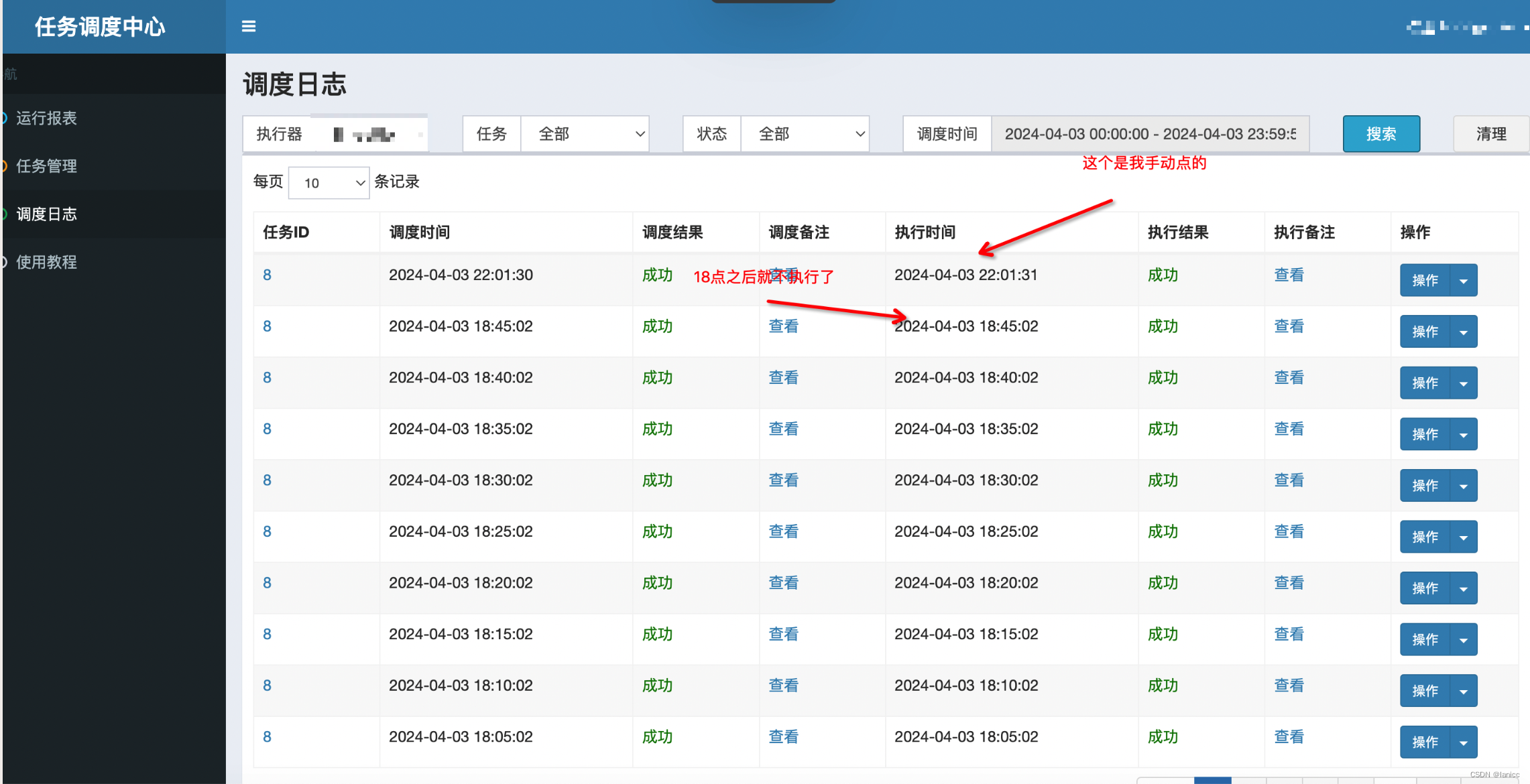
XXL 原理
执行器注册和发现
xxl_job_registry:执行器的实例表,保存实例信息和心跳信息xxl_job_group:每个服务注册的实例列表
执行器启动线程每隔30秒向注册表xxl_job_registry请求一次,更新执行器的心跳信息,调度中心启动线程每隔30秒检测一次xxl_job_registry,将超过90秒还没有收到心跳的实例信息从xxl_job_registry删除,并更新xxl_job_group服务的实例列表信息。
调度原理
调度器循环不停的:
- 关闭事务的自动提交
- 利用
mysql悲观锁作为分布式锁,其他事务无法进入
select * from xxl_job_lock where lock_name = 'schedule_lock' for update
- 读取数据库中的任务信息
- 根据任务的调度时机,
排查思路
根据xxl的原理和业务反馈的问题,很容易想到可能出问题的点
- 执行器注册问题:执行器是否注册
- 任务状态问题:业务反馈的任务状态
- 调度器问题:其他任务是否正常调度
经过对基本的问题快速排查,发现了问题是出现在调度上
排查
查看日志,发现执行 select * from xxl_job_lock where lock_name = 'schedule_lock' for update时报错,事务等待超时
排查数据库事务等待情况
SELECT
r.trx_id waiting_trx_id,
r.trx_mysql_thread_id waiting_thread,
r.trx_query waiting_query,
b.trx_id blocking_trx_id,
b.trx_mysql_thread_id blocking_thread,
b.trx_query blocking_query
FROM
information_schema.innodb_lock_waits w
INNER JOIN information_schema.innodb_trx b ON
b.trx_id = w.blocking_trx_id
INNER JOIN information_schema.innodb_trx r ON
r.trx_id = w.requesting_trx_id;
发现schedule_lock表,正在被另一个线程锁定

再执行show processlist,查到了该连接的客户端地址,并且发现该客户端的连接已经存在了14778秒,约等于4个小时,和事故持续时间一致
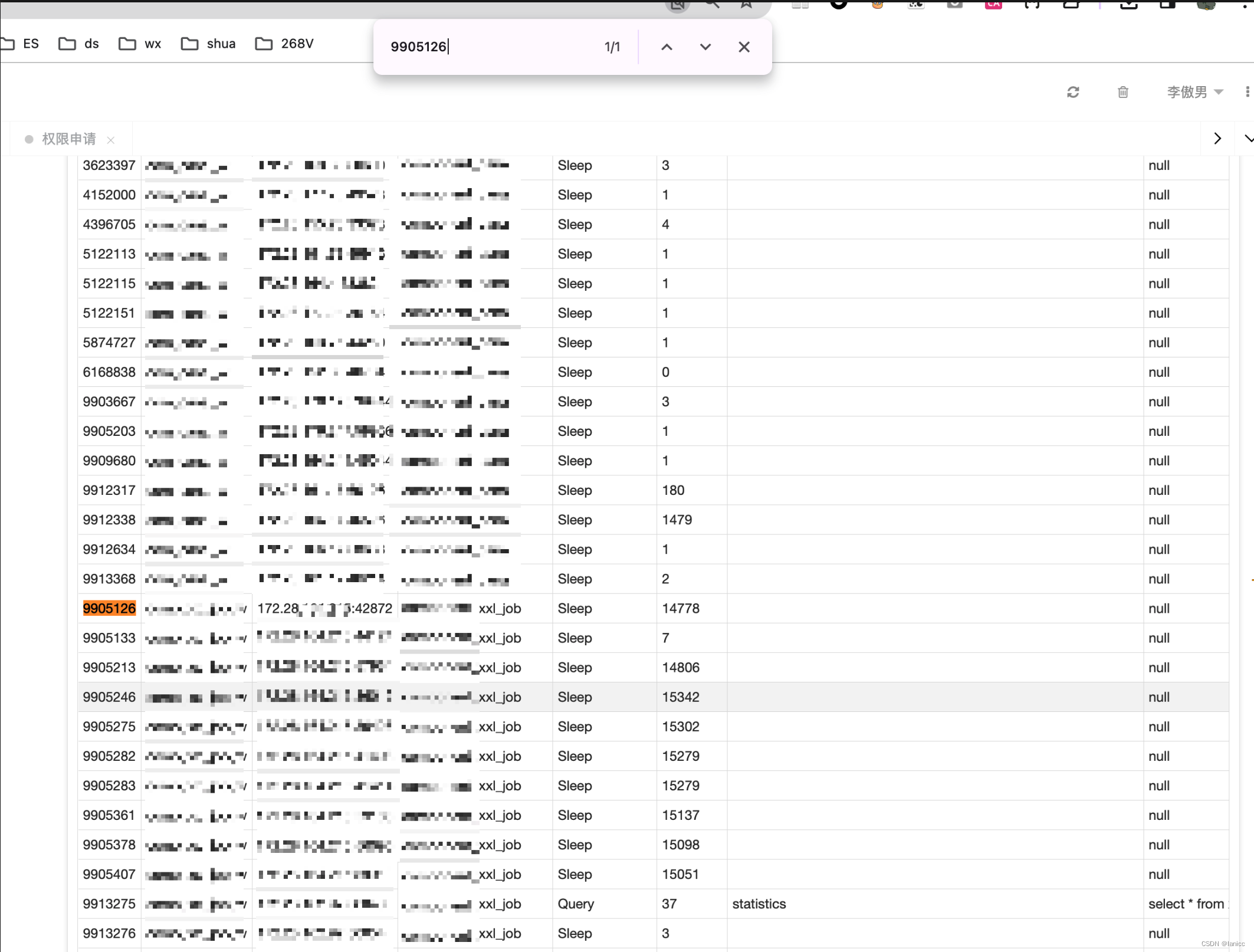
排查异常连接客户端
- 一方面联系dba将该客户端的连接全部kill
- 一方面联系运维排查这个ip的来源
恢复
dba将该客户端的连接全部kill后,xxl调度恢复
排查异常连接来源
经过排查,该异常连接属于18:45分挂掉的pod,有一台k8s的worker有问题,节点被k8s驱逐,但实际物理机还在运行,停不掉应用,当前发现物理机节点磁盘有问题,还在排查中。
思考一下
- xxl利用mysql悲观锁作为分布式锁,优缺点是什么呢
优点:简单
缺点:事务超时 & 续期 需要优化 - 事务超时,告警需要优化
- 任务执行状态异常监控告警
















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











