







前段时间猫哥给大家讲解了12306换乘抢票。今天猫哥带着大家一起对豆瓣电影(音乐、图书也一样)的详细信息进行一次抓取,我们先打开豆瓣电影的链接https://movie.douban.com/,然后点击选电影,如下图
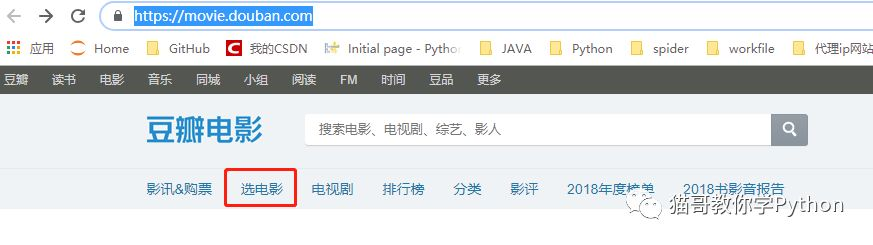
我们对华语电影进行抓取,其他类别的电影以此类推。
分析数据来源,判断是否是动态加载。猫哥的判断方法就是看源码,源码中没有数据,就说明是动态加载。方法:右键--->查看网页源代码
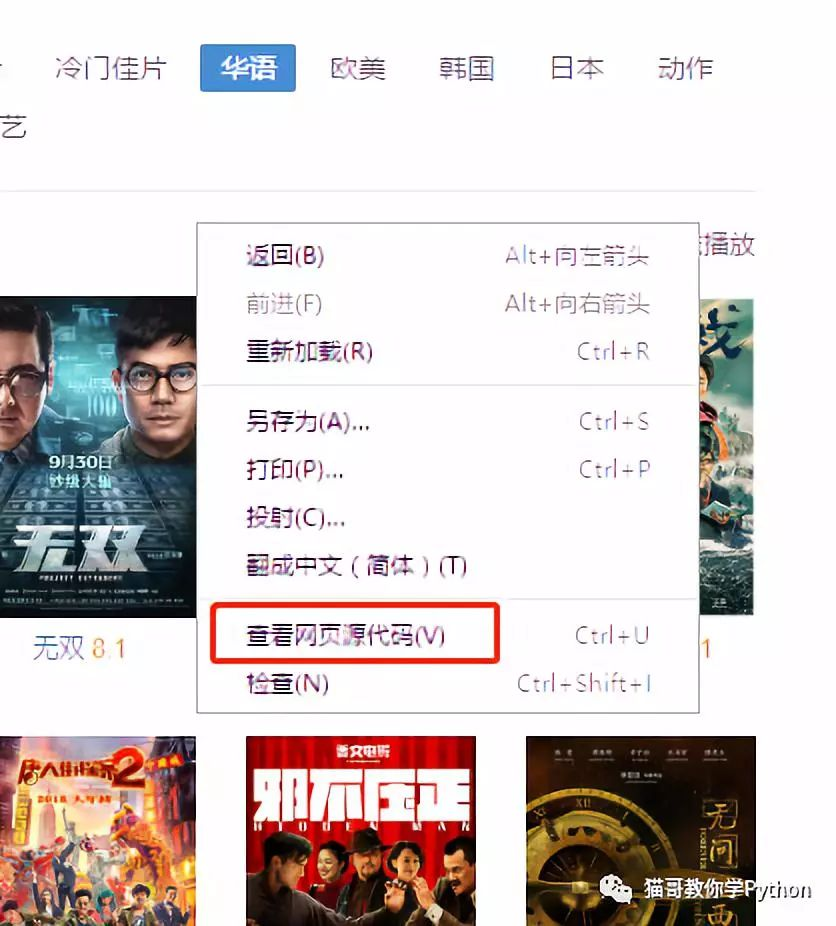
进入源代码界面,ctrl + f 搜索一个电影名,例如猫哥搜索《无双》得到的结果却是0,说明数据是动态加载的(前提是输入的数据是前端页面中已经展示出来的电影名或其它信息)。
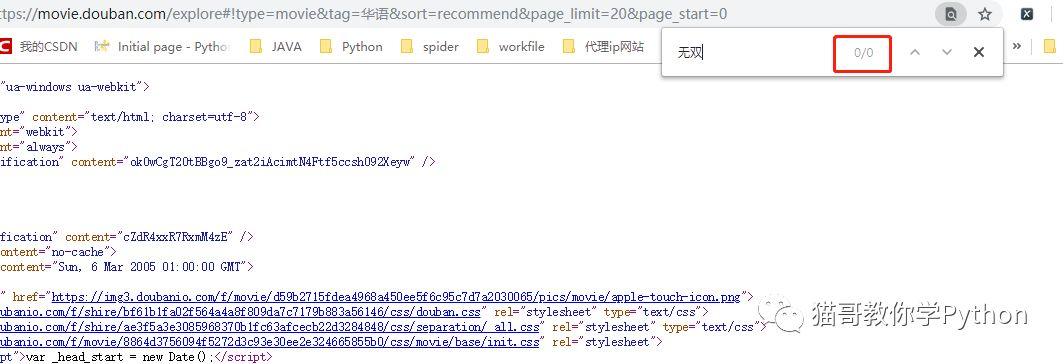
我们在网页端按下F12,调出google浏览器的控制台。选择network,按F5刷新。
然后我们依次选择XHR,加载json的链接(找不到的话就一个一个的点,不会太多的),response。
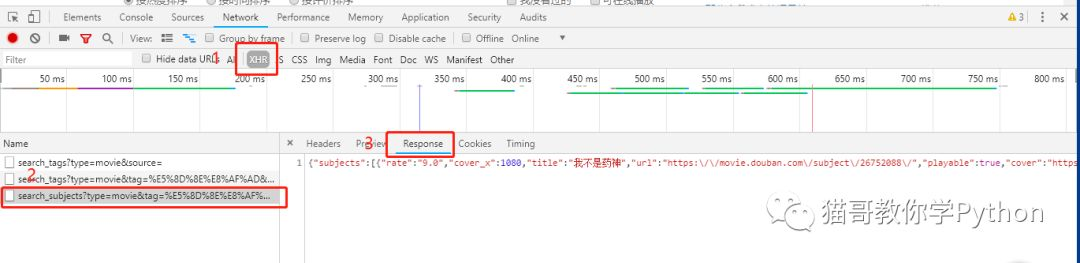
我们可以清除的看到我们所需要的信息。然后点击headers,查看其发送的链接地址和方法。
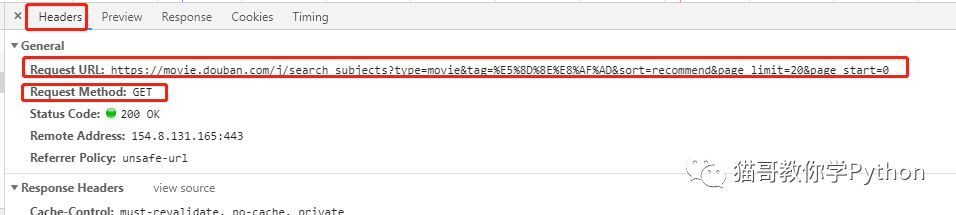
我们将链接地址复制到浏览器中展示,看到下面的内容就说明我们找对了。
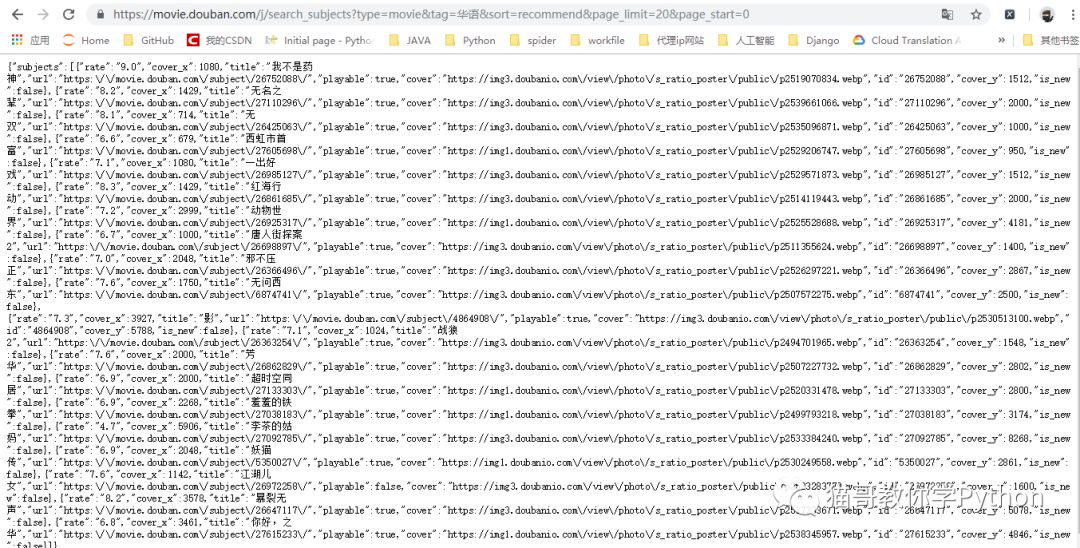
(获取更多电影信息)我们返回到电影页面,点击加载更多,发现只有page_start在改变。
点击前:
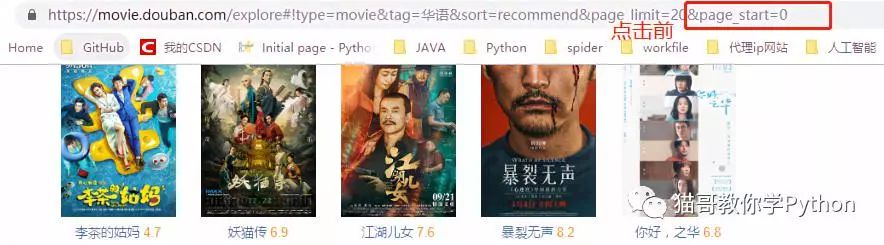
点击后:

由此我们可以得出一个结论,想要加载出更多的信息,我们只需改变page_start即可。得到以上信息后我们就可以写代码了。
先引入我们所需要的包
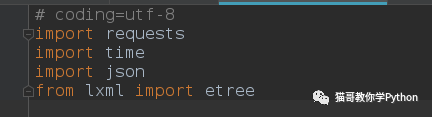
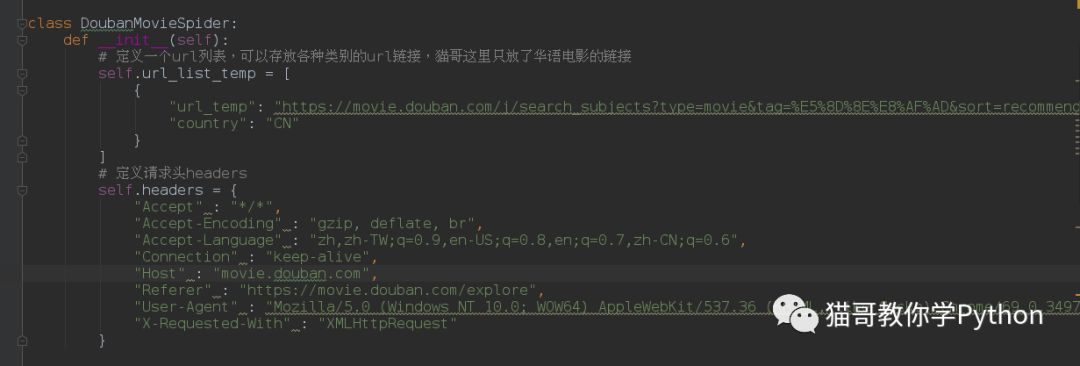
创建一个类,并定义__init__方法。包含url列表和请求头
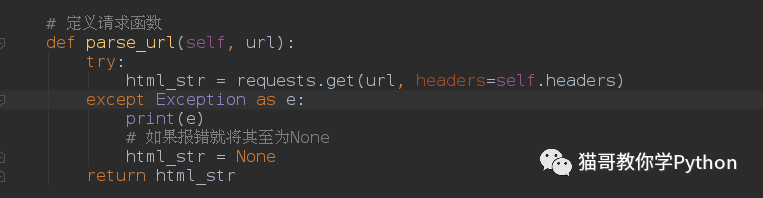
定义请求函数
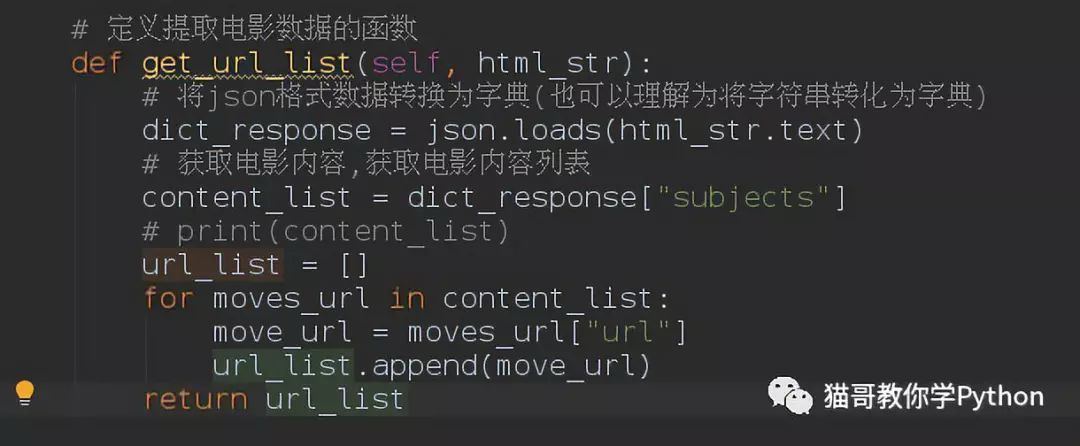
定义提取电影url的函数
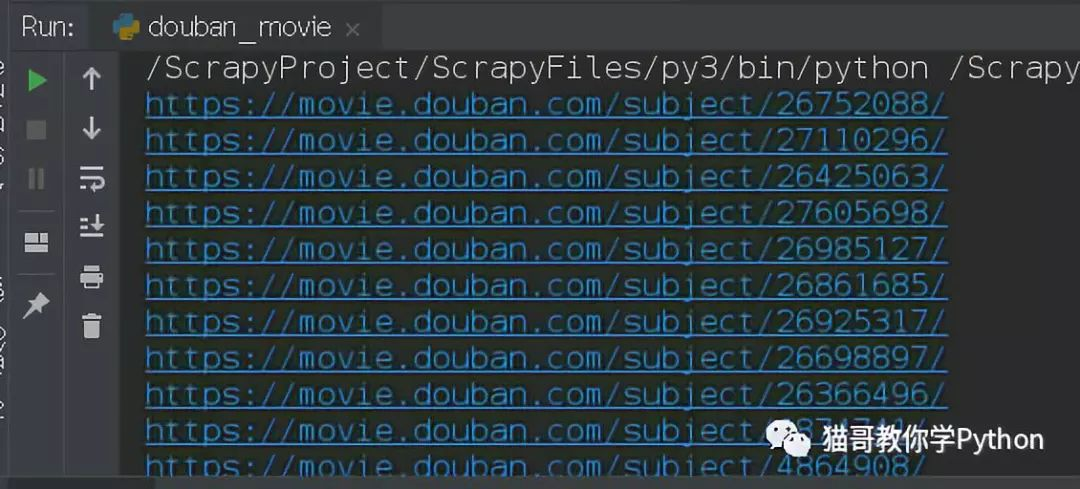
(对于仅仅是获取电影名、评分和封面的朋友来说,我们可以执行下面的函数)

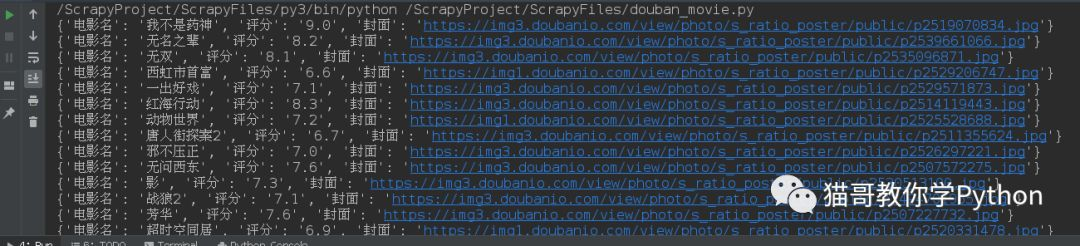
定义run函数和main函数
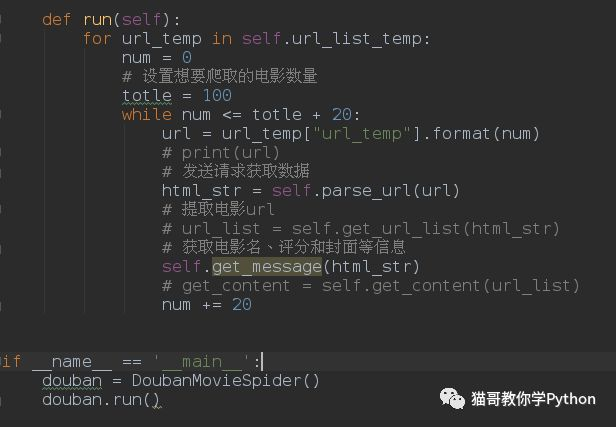
想要获取到更多更详细的内容,我们就要从刚才获取的url列表入手,进一步向下访问。
本次课程就先到这里,在下次课中我将告诉大家如何获取更多的内容,以及如何设置延时、代理IP、入库等方法。
在这里猫哥要提醒一下哈,猫哥不讲python基础,只讲实用的python案例,建议没有python基础的朋友,可以先学一下python基础,要不然你就真搞不懂猫哥在干啥了。
关注微信公众号,回复电影01,免费获取本次课程源码。

加猫哥微信,拉你进入Python大家庭,加好友时请备注名字+学习方向;例如:张小强+爬虫



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









