







人工智能之深度学习框架:深度学习Tensorflow
笔记介绍
通过参考书:“TensorFlow实战Google深度学习框架”、“莫烦TensorFlow视频、TensorFlow中文社区(http://www.tensorfly.cn/ )”进行学习、总结。 本内容是一些学习过程中,本人认为有意义的笔记,而不是完整教程,可能只适合本人之后学习、回顾。
一、深度学习
对于传统的机器学习问题来说,特征提取不是一件简单的事情。在一些复杂问题上,要通过人工的方式设计有效的特征集合,需要很多的时间和精力,有时甚至需要整个领域数十年的研究投入。也就是说,特征工程需要耗费好多资源。既然人工的方式无法很好地抽取实体中的特征,那么是否有自动的方式呢?答案是肯定的。深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征,并使用这些组合特征解决问题。深度学习是机器学习的分支,它除了可以学习特征和任务之间的关联,还能自动从简单特征中提取更加复杂的特征。
早起的深度学习收到了神经科学的启发,它们之间有着非常密切的联系。科学家们在神经科学上的发现使得我们相信深度学习可以胜任很多人工智能的任务。神经科学家发现,如果将小白鼠的视觉神经连接到听觉中枢,一段时间之后小白鼠可以习得使用听觉中枢“看”世界。这说明虽然哺乳动物大脑分为了很多区域,但这些区域的学习机制却是相似的。
二、TensorFlow环境搭建
TensorFlow的主要依赖包:Protocol Buffer 和 Bazel 。
Protocol Buffer 是谷歌开发的处理结构化数据的工具。将结构化的数据持久化或进行网络传输时,就需要先将它们序列化,是将结构化的数据编程数据流的格式,简单的说就是变成一个字符串。将结构化的数据序列化,并从序列化之后的数据流中还原来的结构化数据,统称为处理结构化数据。这就是Protocol Buffer 解决的主要问题。除Protocol Buffer 之外,XML和JSON是两种比较常用的结构化数据处理工具。Protocol Buffer 序列化出来的数据要比XML格式的数据小3到10倍,解析时间要快20到100倍。
Bazel是从谷歌开源的自动化构建工具,谷歌内部绝大部分的应用都是通过它来编译的。
三、TensorFlow入门
关于TensorFlow的计算模型、数据模型、运行模型。
-
TensorFlow的计算模型-------计算图
TensorFlow中的所有计算都会被转化为计算图上的节点。TensorFlow是一个通过计算图的形式来表述计算的编程系统,TensorFlow中的每个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
TensorFlow程序一般可以分为两个阶段。第一个阶段是:定义计算图中所有的计算;第二个阶段:执行计算。
在TensorFlow程序中,系统会自动维护一个默认的计算图,通过tf.get_default_graph函数可以获取当前默认的计算图。除了使用默认的计算图,TensorFlow支持通过tf.Graph函数来生成新的计算图。不同计算图上的张量和运算都不会共享。
TensorFlow中的计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算的机制。计算图可以通过tf.Graph.device函数来指定运行计算的设备。这为TensorFLow使用GPU提供了机制。
有效地管理TensorFlow程序中的资源也是计算图的一个重要功能。在一个计算图中,可以通过集合(collection)来管理不停类别的资源。 -
TensorFlow数据模型-------张量
张量是TensorFlow管理数据的形式。在TensorFlow程序中,所有的数据都通过张量的形式表示。从功能的角度上看,张量可以被简单理解为多维数组。但张量在TensorFlow中的实现并不是直接采取数组的形式,它只是对TensorFlow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。
一个张量主要保存了三个属性:名字(name)、维度(shape)、类型(type)。
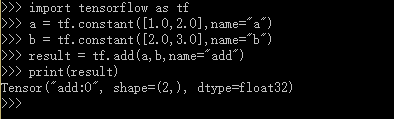
从以上代码可以看出TensorFlow中的张量和Numpy中的数组不同,TensorFlow计算的结果不是一个具体的数字,而是一个张量的结构。
张量的第一个属性名字不仅是一个张量的唯一标识符,它同样也给出了这个张量是如何计算出来的。之前介绍了TensorFlow的计算都可以通过计算图的模型来建立,而计算图上的每一个节点代表一个计算,计算的结果就保存在张量之中。所以张量和计算图上节点所代表的计算结果是对应的。这样张量的命名就可以通过“node:src_output”的形式来给出。其中node为节点的名称,src_output表示当前张量来自节点的第几个输出。比如上面代码打出来的“add:0”就说明了result这个张量是计算节点“add”输出的第一个结果(编号从0开始)。
张量的第二个属性是张量的维度(shape)。这个属性描述了一个张量的维度信息。维度是张量一个很重要的属性。
张量的第三个属性是类型(type),每一个张量会有一个唯一的类型。TensorFlow会对参与运算的所有张量进行类型的检查,当发现类型不匹配时会报错。

所以一般建议通过指定dtype来明确指出变量或者常量的类型。
张量的使用:第一类用途是对中间计算结果的引用。当一个计算包含很多中间结果时,使用张量可以大大提高代码的可读性。同时,通过张量来存储中间结果可以方便获取中间结果。比如在卷积神经网络中,卷积层或者池化层有可能改变张量的维度,通过result.get_shape函数后去结果张量的维度信息可以免去人工计算的麻烦。第二类情况是当计算图构造完成之后,张量可以用来后去计算结果,也就是得到真实的数字。虽然张量本身没有存储具体的数字,但是可以通过下面的会话得到这些具体的数字。比如:tf.Session().run(result)语句得到计算结果。 -
TensorFlow运行模型------会话
使用TensorFlow中的会话(session)来执行定义好的计算,会话拥有并管理TensorFlow程序运行时的所有资源,所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄露的问题。TensorFlow中使用会话的模式一般有两种,第一种模式需要明确调用会话生成函数和关闭会话函数;第二种模式可以通过Python的上下文管理器来使用会话。
模式一:

使用这种模式时,在所有计算完成之后,需要明确调用Session.close函数来关闭会话来释放资源。然而,当程序因为异常而退出是,关闭会话的函数可能就不会被执行从而导致资源泄露。
模式二:

通过Python上下文管理器的机制,只要将所有的计算放在“with”的内部就可以。当上下文管理器退出时候会自动释放所有资源。这样既解决了因为异常退出时资源释放的问题,同时也解决了忘记调用Session.close函数而产生的资源泄露。
TensorFlow实现神经网络
TensorFlow游乐场(http://playground.tensorflow.org)是一个通过网页浏览器就可以训练的简单神经网络并实现了可视化训练过程的工具。
通过上述例子得出,使用神经网络解决分类问题主要可以分为以下4个步骤:
①提取问题中实体的特征向量作为神经网络的输入。不同的实体可以提取不同的特征向量。
②定义神经网络的结构,并定义如何作为神经网络的输入得到输出。这个过程就是神经网络的前向传播算法。。
③通过训练数据来调整神经网络中参数的取值,这就是训练神经网络的过程。
④使用训练好的神经网络来预测位置的数据。
笔记:
①在TensorFlow中,一个变量的值在被使用之前,这个变量初始化过程需要被明确的调用。

当变量数目增多,或者变量之间存在依赖关系时,单个调用的方案就比较麻烦了。为了解决这个问题,TensorFlow提供了一个更加便捷的方式来完成变量初始化过程。即通过tf.global_variables_initializer函数实现初始化所有变量的过程。

训练神经网络的过程可以分为以下三个步骤:
1、定义神经网络的结构和前向传播的输出结果。
2、定义损失函数以及选择反向传播优化的算法。
2、生成会话(tf.Session)并且在训练数据上反复运行反向传播优化算法。
四、深层神经网络
维基百科中对深度学习的精确定义为“一类通过多层非线性变换对高复杂性数据建模算法的合集”。深度学习有两个非常重要的特性--------多层和非线性。
①线性模型具有局新型,能够解决的问题是有限的。
②多层网络解决异或运算。
深层神经网络实际上有组合特征提取的功能。
损失函数
梯度下降算法主要用于优化单个参数的取值。
反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法,从而使神经网络模型在训练数据上的损失函数尽可能小。
神经网络进一步优化:学习率的设置、过拟合问题、滑动平均模型。
一、学习率的设置
学习率既不能过大,也不能过小为了解决设定学习率的问题,TensorFlow提供了一种更加灵活的学习率的设置方法-----指数衰减法。tf.train.exponential_decay函数实现了指数衰减学习率。通过这个函数,可以先使用较大大学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减少学习率,使得模型在训练后期更加稳定。exponential_decay函数会指数级地减小学习率。
二、过拟合问题
正则化。正则化的思想就是在损失函数中加入刻画模型复杂程度的指标。
三、滑动平均模型 (???)
可以使模型在测试数据上更健壮(rebust)的方法------滑动平均模型。在采用随机梯度下降算法训练神经网络时,使用滑动平均模型在很多应用中都可以在一定程度提高最终模型在测试数据上的表现。















 1625
1625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









