







人工智能之Python系列:pandas库
一、引言
由于DataFrame数据结构为二维表格结构,这使得pandas库成为数据分析的“主力军”。本文将讲解pandas库中两种基础数据结构的创建和使用方法及DataFrame的选取和操作。
二、pandas数据结构
pandas有两种基本的数据结构:Series和DataFrame。
2.1 创建Series数据
Series数据结构类似于一维数组,但它是有一维数据(各种Numpy数据类型)和一组对应的索引组成。通过一组列表数据即可产生最简单的Series数据,如图:
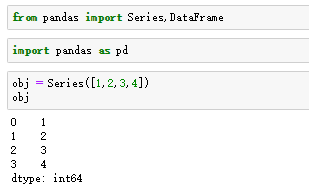
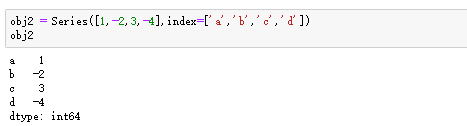
Series数据:索引在左边,值在右边。可以看出:如果没有指定一组数据作为索引的话,Series数据会以0到N-1(N为数据的长度)作为索引,也可以通过指定索引的方式来创建Series数据,如图:
Series有values和index属性,返回值为数组形式和索引对象。

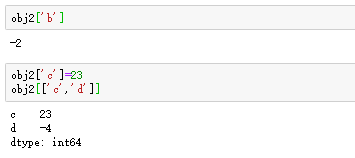
Series与普通的一维数组相比,其具有索引对象,可通过索引来获取Series的单个或一组值,如图:
Series运算都会保留索引和值之间的链接,如图:
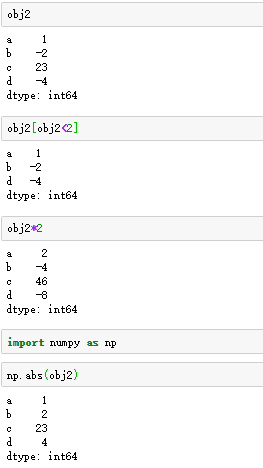
Series数据中的索引和值一一对应,类似于Python字典数据,所以也可以通过字典数据来创建Series。
2.2 创建DataFrame数据
DataFrame数据是Python数据分析最常用的数据,无论是创建的数据或外部的数据,我们首先想到的都是如何将其转换为DataFrame数据,原因是DataFrame为表格型数据。
创建DataFrame数据的办法有很多,最常用的是传入有数组、列表或元组组成的字典,如图:

返回的数据如上图,DataFrame数据有行索引和列索引,行索引类似Excel表格中每行的编号(没有指定行索引的情况下),列索引类似于Excel表格的列名(通常也称为字段)。由于字典是无序的,因此可以通过columns指定列索引的顺序。当没有指定行索引的情况下,会使用0到N-1作为列索引,也可以通过index来指定行索引。
使用嵌套字典的数据也可以创建DataFrame数据,如图:

创建DataFrame数据可传入的数据类型:
| 类型 | 使用说明 |
|---|---|
| 二维ndarray | 数据矩阵,可传入行列索引 |
| 由数组、列表或元组组成的字典 | 前面例子 |
| 由Series组成的字典 | 每个Series为一列,Series索引合并为行索引 |
| 嵌套字典 | 前面例子 |
| 字典或Series的列表 | 各项成为DataFraame一行,字典键或Series索引成为DataFrame列索引 |
| 由列表或元组组成的列表 | 类似于‘二维数组’ |
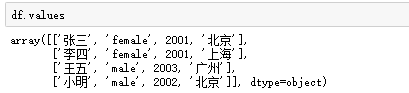
通过values属性可以将DataFrame数据转换为二维数组。如图:
3.3 索引对象
Series的索引和DataFrame的行和列索引都是索引对象,用于负责管理轴标签和元数据。

索引对象是不可以进行修改的,如果修改就会报错,如图:

索引对象类似于数组数据,其功能也类似于一个固定大小的集合,如图:

三、pandas索引操作
3.1 重新索引
索引对象是无法修改的,这里所说的重新索引并不是给索引重新命名,而是对索引重新排序,如果某个索引值不存在的话,就会引入缺失值。如图:

如果需要对插入的缺失值进行填充的话,可通过method参数来实现,参数值为ffill或pad时未向前填充,参数值为bfill或backfill时未向后填充。如图:

对于DataFrame数据来说,行和列索引都是可以重新索引的。重新索引列需要使用columns关键字。
3.2 更换索引
在DataFrame数据中,如果不希望使用默认行索引的话,可在创建的时候通过index参数来设置行索引。有时我们希望将列数据作为行索引,这时可通过set_index方法来实现。如图:

与set_index方法相反的方法是reset_index方法。如上图。
3.3 索引和选取
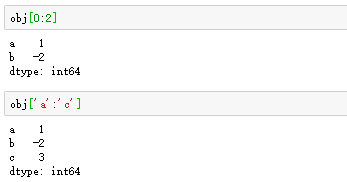
Series数据的选取较为简单,使用方法类似于Python的列表,不仅可以通过0到N-1来进行索引,同时也可以通过设置好的索引标签来进行索引。如图:

切片运算与Python列表略有不同,如果是利用索引标签切片,其尾端是被包含的,如图:
DataFrame数据的选取更复杂些,因为它是二维数组,选取列和行都有具体的方法。
- 选取列
通过列标签或以属性的方式可以单独获取DataFrame的列数据,返回的数据为Series结构。

通过两个中括号,可以获取多个列的数据。如图
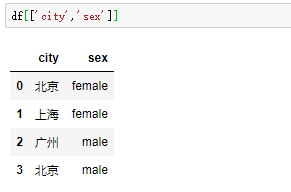
Δ注意:选取列不能使用切片,因为切片用于选取行数据。 - 选取行
通过行索引标签或行索引位置(0到N-1)的切片形式可选取DataFrame的行数据。

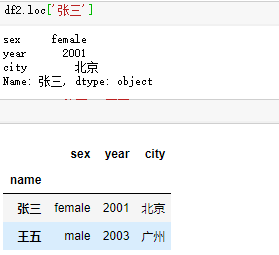
显然,切片方法选取行有很大的局限性。如果想获取单独的几行,通过loc和iloc方法可以实现。loc方法是按行索引标签选取数据;iloc方法是按行索引位置选取标签。如图
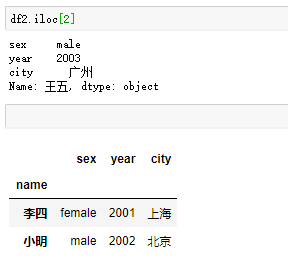
- 选取行和列
在数据分析中,有时可能只是对部分行和列进行操作,这是就需要选取DataFrame数据中行和列的子集,而通过ix方法就可以轻松完成。ix方法同时支持索引标签和索引位置来进行数据的选择。

其实,ix方法除了可以选取行和列外,也可以选择单独的行或者列。如图:

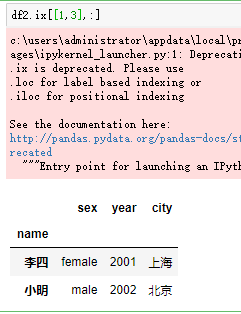
- 布尔选择
与数组布尔型索引类似。

3.4 操作行和列
在数据分析中,常用的基本操作为:“增,删,改,查”,查(选取)在前面内容中已讲过。
5. 增加
增加行,使用append函数传入一个字典结构数据即可。

增加列,如图

6. 删除

3. 修改
这里的“改”指的是行和列索引标签的修改,通过rename函数,可完成由于某些原因导致的标签录入错误的问题。

#inplace可在原数据上修改。
四、pandas数据运算
4.1 算术运算
略
4.2 函数应用和映射
在数据分析时,常常会对数据进行较复杂的数据运算,这时需要定义函数。定义好的函数可以应用到pandas数据中,其中有三种方法:map函数,将函数套用在Series的每个元素中;apply函数,将函数套用到DataFrame的行和列上;applymap函数,将函数套用到DataFrame的每个元素上。
如图:把price列中的“元”字去掉,这时就需要用到map函数。

apply函数的使用方法如图:

applymap函数可作用于每个元素,便于对整个DataFrame数据进行批量处理。

4.3 排序
sort_index函数可对索引进行排序,默认为升序。
sort_values方法可对值进行排序。
4.4 汇总与统计
在DataFrame数据中,通过sum函数可以对每列进行求和汇总。

指定轴方向,通过sum函数可按行汇总。
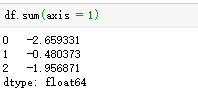
describe方法可对每个数值型列进行统计,经常用于对数据的初步观察时使用,如图;
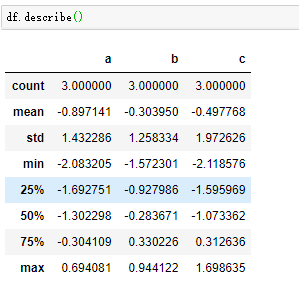
4.5 唯一值和值计算
在Series中,通过unique函数可以获取不重复的数组。
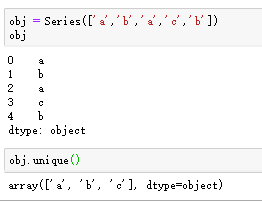
通过values_counts方法可统计每个值出现的次数,如图:
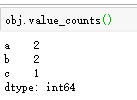
Δ注意:对于DataFrame的列而言,unique函数和values_counts方法同样使用。















 695
695











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









