







 本文详细介绍了OCR(光学字符识别)领域的多个数据集,包括Synthetic Chinese String Dataset、ICPR MWI 2018挑战赛、Pascal VOC2007、MSRA-TD500、COCO-TEXT、Google FSNS、RCTW-17、CTW、Total-Text等,涵盖了文本识别和文本检测的数据集,适合用于训练和测试OCR系统。
本文详细介绍了OCR(光学字符识别)领域的多个数据集,包括Synthetic Chinese String Dataset、ICPR MWI 2018挑战赛、Pascal VOC2007、MSRA-TD500、COCO-TEXT、Google FSNS、RCTW-17、CTW、Total-Text等,涵盖了文本识别和文本检测的数据集,适合用于训练和测试OCR系统。
1.文本识别数据集
1.1.Synthetic Chinese String Dataset
该数据集是中文识别数据集,包含360多万张训练图片,5824个字符,不过场景比较简单,图片是白底黑字。
下载地址:https://pan.baidu.com/s/1dFda6R3
图片,文字标签

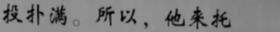
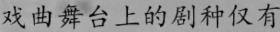
2.文本检测数据
ICPR MWI 2018 挑战赛
大赛提供20000张图像作为数据集,其中50%作为训练集,50%作为测试集。主要由合成图像,产品描述,网络广告构成。该数据集数据量充分,中英文混合,涵盖数十种字体,字体大小不一,多种版式,背景复杂。文件大小为2GB。
https://tianchi.aliyun.com/competition/information.htm?raceId=231651&_is_login_redirect=true&accounttraceid=595a06c3-7530-4b8a-ad3d-40165e22dbfe
链接:https://pan.baidu.com/s/1zxXokAYsyVbfWP2dUPGrPw
提取码:z1bj
2.1.Pascal VOC2007
$ cd $FRCN/data
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
$ wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
$ tar xvf VOCdevkit_08-Jun-2007.tar
$ tar xvf VOCtrainval_06-Nov-2007.tar
$ tar xvf VOCtest_06-Nov-2007.tar
$ ln -s VOCdevkit VOCdevkit2007 #create a softlink
链接:https://pan.baidu.com/s/1n3HSbDVZ-75SXC1PNC7bHA
提取码:8k9a
复制这段内容后打开百度网盘手机App,操作更方便哦


2.2.MSRA Text Detection 500 Database (MSRA-TD500)
MSRA文本检测500数据库(MSRA-TD500)包含500个自然图像,使用数据包相机从室内(办公室和商场)和室外(街道)场景拍摄,室内图像主要是标志,门板和警示牌,而室外图像主要是复杂背景下的导板和广告牌。图像的分辨率从1296x864到1920x1280不等。由于文本的多样性和图像背景的复杂性,数据集非常具有挑战性。文本可以是不同的语言(中文,英文或两者的混合),字体,大小,颜色和方向。
http://www.iapr-tc11.org/mediawiki/index.php/MSRA_Text_Detection_500_Database_%28MSRA-TD500%29
http://www.iapr-tc11.org/dataset/MSRA-TD500/MSRA-TD500.zip
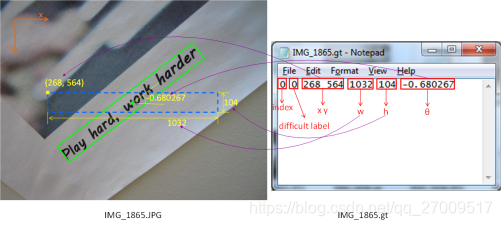

0 0 749 860 47 105 -0.048040
1 1 728 919 16 44 -0.023252
2.3.COCO-TEXT
英文数据集,包括63686幅图像,173589个文本实例,包括手写版和打印版,清晰版和非清晰版。文件大小12.58GB,训练集:43686张,测试集:10000张,验证集:10000张。
下载地址:https://vision.cornell.edu/se3/coco-text-2/

COCO-Text API
The COCO-Text API assists in loading and parsing the annotations in COCO-Text. For details, see coco.py and also the coco_text_Demo ipython notebook.
getAnnIds Get ann ids that satisfy given filter conditions
getImgIds Get img ids that satisfy given filter conditions
loadAnns Load anns with the specified ids.
loadImgs Load imgs with the specified ids.
loadRes Load algorithm results and create API for accessing them.
The annotations are stored using the JSON file format. The annotations format has the following data structure:
{
“info” : info,
“imgs” : [image],
“anns” : [annotation]
}
info{
“version” : str,
“description” : str,
“author” : str,
“url” : str,
“date_created” : datetime
}
image{
“id” : int,
“file_name” : str,
“width” : int,
“height” : int,
“set” : str # ‘train’ or ‘val’
}
Each text instance annotation contains a series of fields, including an enclosing bounding box, category annotations, and transcription.
annotation{
“id” : int,
“image_id” : int,
“class” : str # ‘machine printed’ or ‘handwritten’ or ‘others’
“legibility” : str # ‘legible’ or ‘illegible’
“language” : str # ‘english’ or ‘not english’ or ‘na’
“area” : float,
“bbox” : [x,y,width,height],
“utf8_string” : str,
“polygon” : []
}
2.4.Google FSNS(谷歌街景文本数据集)
该数据集是从谷歌法国街景图片上获得的一百多万张街道名字标志,每一张包含同一街道标志牌的不同视角,图像大小为600*150,训练集1044868张,验证集16150张,测试集20404张。
下载地址:http://rrc.cvc.uab.es/?ch=6&com=downloads
2.5.Reading Chinese Text in the Wild(RCTW-17)
该数据集包含12263张图像,训练集8034张,测试集4229张,共11.4GB。大部分图像由手机相机拍摄,含有少量的屏幕截图,图像中包含中文文本与少量英文文本。图像分辨率大小不等。icdar2017rctw_train_v1.2
下载地址:http://rctw.vlrlab.net/dataset/
icdar2017rctw_train_v1.2
图片,坐标位置和文本
一串字一个方框
,,,,,,,,,""; ,,,,,,,,,""; …
例子:

390,902,1856,902,1856,1225,390,1225,0,“金氏眼镜”
1875,1170,2149,1170,2149,1245,1875,1245,0,“创于1989”
2054,1277,2190,1277,2190,1323,2054,1323,0,“城建店”
768,1648,987,1648,987,1714,768,1714,0,“金氏眼”
897,2152,988,2152,988,2182,897,2182,0,“金氏眼镜”
1457,2228,1575,2228,1575,2259,1457,2259,0,“金氏眼镜”
1858,2218,1966,2218,1966,2250,1858,2250,0,“金氏眼镜”
231,1853,308,1843,309,1885,230,1899,1,“谢#惠顾”
125,2270,180,2270,180,2288,125,2288,1,"###"
106,2297,160,2297,160,2316,106,2316,1,"###"
22,2363,82,2363,82,2383,22,2383,1,"###"
524,2511,837,2511,837,2554,524,2554,1,"###"
455,2456,921,2437,920,2478,4
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2283
2283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









