







1.笔记
1.1.论文关键idea
- 提出了基于two-stage的文本检测方法:全卷积网络(FCN)和非极大值抑制(NMS),消除中间过程冗余,减少检测时间.
- 该方法即可以检测单词级别,又可以检测文本行级别.检测的形状可以为任意形状的四边形:即可以是旋转矩形(下图中绿色的框),也可以是普通四边形(下图中蓝色的框)).
- 采用了Locality-Aware NMS来对生成的几何进行过滤
不是,受感受野影响,east 不能检测很长样本。标注样本是画长一点,检测身份证这种事没问题的。和本身感受野相关,之前针对east做了改进,可以检测那种跨整个图像的文本行。
1.2.notes
- ICPR MWI 2018 挑战赛训练的图片可以检测长文本(一行)
- Reading Chinese Text in the Wild(RCTW-17):无法检测长文本
- 修改获得是否为文字区域的置信度
1.3.pipeline
论文的思想非常简单,结合了DenseBox和Unet网络中的特性,具体流程如下:
- 先用一个通用的网络(论文中采用的是Pvanet,实际在使用的时候可以采用VGG16,Resnet等)作为base net ,用于特征提取
- 基于上述主干特征提取网络,抽取不同level的feature map(它们的尺寸分别是input-image的1/32,1/16,1/8,1/4),这样可以得到不同尺度的特征图.目的是解决文本行尺度变换剧烈的问题,ealy stage可用于预测小的文本行,late-stage可用于预测大的文本行。
- 特征合并层,将抽取的特征进行merge.这里合并的规则采用了U-net的方法,合并规则:从特征提取网络的顶部特征按照相应的规则向下进行合并,这里描述可能不太好理解,具体参见下述的网络结构图。
- 网络输出层,包含文本得分和文本形状.根据不同文本形状(可分为RBOX和QUAD),输出也各不相同,具体参看网络结构图。

2.Abstract
Previous approaches for scene text detection have already achieved promising performances across various benchmarks. However, they usually fall short when dealing with challenging scenarios, even when equipped with deep neural network models, because the overall performance is determined by the interplay of multiple stages and components in the pipelines. In this work, we propose a simple yet powerful pipeline that yields fast and accurate text detection in natural scenes.
先前的场景文本检测方法已经在各种基准测试中取得了可喜的性能。但是,即使在配备有深度神经网络模型的情况下,它们在处理具有挑战性的场景时通常也达不到要求,因为总体性能取决于管道中多个阶段和组件的相互作用。在这项工作中,我们提出了一个简单而功能强大的管道,该管道可以在自然场景中快速准确地检测文本。
The pipeline directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images, eliminating unnecessary intermediate steps (e.g., candidate aggregation and word partitioning), with a single neural network. The simplicity of our pipeline allows concentrating efforts on designing loss functions and neural network architecture. Experiments on standard datasets including ICDAR 2015, COCO-Text and MSRA-TD500 demonstrate that the proposed algorithm significantly outperforms state-of-the-art methods in terms of both accuracy and efficiency. On the ICDAR 2015 dataset, the proposed algorithm achieves an F-score of 0.7820 at 13.2fps at 720p resolution.
该流水线可通过单个神经网络直接预测完整图像中任意方向和四边形形状的单词或文本行,从而消除了不必要的中间步骤(例如候选集合和单词划分)。我们管道的简单性使得我们可以集中精力设计损失函数和神经网络架构。在包括ICDAR 2015,COCO-Text和MSRA-TD500在内的标准数据集上进行的实验表明,该算法在准确性和效率上均明显优于最新方法。在ICDAR 2015数据集上,提出的算法在720p分辨率下以13.2fps的速度获得了0.7820的F得分。
fps:f就是英文单词Frame(画面、帧),p就是Per(每),s就是Second(秒)。用中文表达就是多少帧每秒,或每秒多少帧。
3.Introduction

Recently, extracting and understanding textual information embodied in natural scenes have become increasingly important and popular, which is evidenced by the unprecedented large numbers of participants of the ICDAR series contests [30, 16, 15] and the launch of the TRAIT 2016 evaluation by NIST [1].
近年来,提取和理解自然场景中包含的文字信息变得越来越重要和流行,这一点可以通过ICDAR系列竞赛的空前参与者[30、16、15]和NIST[1]开展的TRAIT 2016评估来证明。
Text detection, as a prerequisite of the subsequent processes, plays a critical role in the whole procedure of textual information extraction and understanding. Previous text detection approaches [2, 33, 12, 7, 48] have already obtained promising performances on various benchmarks in this field. The core of text detection is the design of features to distinguish text from backgrounds. Traditionally, features are manually designed [5, 25, 40, 10, 26, 45] to capture the properties of scene text, while in deep learning based methods [3, 13, 11, 12, 7, 48] effective features are directly learned from training data.
作为后续过程的前提,文本检测在整个文本信息提取和理解过程中起着至关重要的作用。先前的文本检测方法[2、33、12、7、48]已经在该领域的各种基准上获得了有希望的性能。 文本检测的核心是设计功能,以区分文本和背景。 传统上,特征是手动设计的[5、25、40、10、26、45]以捕获场景文本的属性,而在基于深度学习的方法中[3、13、11、12、7、48]直接使用有效特征从训练数据中学到。
However, existing methods, either conventional or deep neural network based, mostly consist of several stages and components, which are probably sub-optimal and time-consuming. Therefore, the accuracy and efficiency of such methods are still far from satisfactory.
但是,现有的方法,无论是传统方法还是基于深度神经网络的方法,都主要由几个阶段和组件组成,这可能不是最佳选择,而且很耗时。因此,这种方法的准确性和效率仍然不能令人满意。
In this paper, we propose a fast and accurate scene text detection pipeline that has only two stages. The pipeline utilizes a fully convolutional network (FCN) model that directly produces word or text-line level predictions, excluding redundant and slow intermediate steps. The produced text predictions, which can be either rotated rectangles or quadrangles, are sent to Non-Maximum Suppression to yield final results. Compared with existing methods, the proposed algorithm achieves significantly enhanced performance, while running much faster, according to the qualitative and quantitative experiments on standard benchmarks.
在本文中,我们提出了只有两个阶段的快速,准确的场景文本检测管道。 管道利用了完全卷积网络(FCN)模型,该模型可直接生成单词或文本行级别的预测,而无需进行冗余和缓慢的中间步骤。产生的文本预测(可以是旋转的矩形或四边形)将发送到“非最大抑制”以产生最终结果。 与现有方法相比,根据标准基准的定性和定量实验,所提出的算法可显着提高性能,同时运行速度更快。
Specifically, the proposed algorithm achieves an F-score of 0.7820 on ICDAR 2015 [15] (0.8072 when tested in multi-scale), 0.7608 on MSRA-TD500 [40] and 0.3945 on COCO-Text [36], outperforming previous state-of-the-art algorithms in performance while taking much less time on average (13.2fps at 720p resolution on a Titan-X GPU for our best performing model, 16.8fps for our fastest model).
具体来说,所提出的算法在ICDAR 2015 [15]上达到0.7820的F值(在多尺度下进行测试时为0.8072),在MSRA-TD500 [40]上达到0.7608的F值,在COCO-Text [36]上达到0.3945的F值, 先进的性能算法,平均所需时间更少(对于性能最佳的Titan-X GPU,在720p分辨率下为13.2fps,对于速度最快的模型为16.8fps)。
The contributions of this work are three-fold:
• We propose a scene text detection method that consists of two stages: a Fully Convolutional Network and an NMS merging stage. The FCN directly produces text regions, excluding redundant and time-consuming intermediate steps.
这项工作的贡献是三方面的:
•我们提出一种场景文本检测方法,该方法包括两个阶段:完全卷积网络和NMS合并阶段。 FCN直接生成文本区域,不包括多余且耗时的中间步骤。
• The pipeline is flexible to produce either word level or line level predictions, whose geometric shapes can be rotated boxes or quadrangles, depending on specific applications.
•管道可以灵活地生成单词级别或行级别的预测,根据特定的应用,其几何形状可以旋转为方框或四边形。
• The proposed algorithm significantly outperforms state-of-the-art methods in both accuracy and speed.
•所提出的算法在准确性和速度上均明显优于最新方法。
4.Related Work
Scene text detection and recognition have been active research topics in computer vision for a long period of time. Numerous inspiring ideas and effective approaches [5, 25, 26, 24, 27, 37, 11, 12, 7, 41, 42, 31] have been investigated. Comprehensive reviews and detailed analyses can be found in survey papers [50, 35, 43]. This section will focus on works that are mostly relevant to the proposed algorithm.
长期以来,场景文本检测和识别一直是计算机视觉中的活跃研究主题。 研究了许多启发性的想法和有效的方法[5、25、26、24、27、37、11、12、7、41、42、31]。 全面的评论和详细的分析可以在调查论文中找到[50,35,43]。 本节将重点介绍与提出的算法最相关的工作。

Conventional approaches rely on manually designed features. Stroke Width Transform (SWT) [5] and Maximally Stable Extremal Regions (MSER) [25, 26] based methods generally seek character candidates via edge detection or extremal region extraction. Zhang et al. [47] made use of the local symmetry property of text and designed various features for text region detection.
常规方法依赖于手动设计的功能。 基于笔划宽度变换(SWT)[5]和最大稳定极值区域(MSER)[25、26]的方法通常通过边缘检测或极值区域提取来寻找候选字符。 张等[47]利用文本的局部对称性,设计了用于文本区域检测的各种功能。
FASText [2] is a fast text detection system that adapted and modified the well-known FAST key point detector for stroke extraction. However, these methods fall behind of those based on deep neural networks, in terms of both accuracy and adaptability, especially when dealing with challenging scenarios, such as low resolution and geometric distortion.
FASText [2]是一种快速的文本检测系统,它对著名的FAST关键点检测器进行了修改和改进,以进行笔画提取。但是,这些方法在准确性和适应性方面均落后于基于深度神经网络的方法,尤其是在处理具有挑战性的场景(例如低分辨率和几何失真)时。
Recently, the area of scene text detection has entered a new era that deep neural network based algorithms [11, 13, 48, 7] have gradually become the mainstream. Huang et al. [11] first found candidates using MSER and then employed a deep convolutional network as a strong classifier to prune false positives.
最近,场景文本检测领域进入了一个新时代,基于深度神经网络的算法[11、13、48、7]逐渐成为主流。黄等[11]首先使用MSER找到候选者,然后使用深度卷积网络作为强分类器以修剪假阳性。
The method of Jaderberg et al. [13] scanned the image in a sliding-window fashion and produced a dense heatmap for each scale with a convolutional neural network model. Later, Jaderberg et al. [12] employed both a CNN and an ACF to hunt word candidates and further refined them using regression. Tian et al. [34] developed vertical anchors and constructed a CNN-RNN joint model to detect horizontal text lines. Different from these methods, Zhang et al. [48] proposed to utilize FCN [23] for heatmap generation and to use component projection for orientation estimation.
Jaderberg等人的方法[13]以滑动窗口方式扫描图像,并使用卷积神经网络模型为每个比例生成密集的热图。后来,Jaderberg等[12]使用CNN和ACF来搜寻候选单词,并使用回归进一步完善它们。田等[34]开发了垂直锚并构建了CNN-RNN联合模型来检测水平文本行。与这些方法不同,Zhang等[48]提出利用FCN [23]生成热图,并使用分量投影进行方向估计。
These methods obtained excellent performance on standard benchmarks. However, as illustrated in Fig. 2(a-d), they mostly consist of multiple stages and components, such as false positive removal by post filtering, candidate aggregation, line formation and word partition. The multitude of stages and components may require exhaustive tuning, leading to sub-optimal performance, and add to processing time of the whole pipeline.
这些方法在标准基准上获得了出色的性能。但是,如图2(a-d)所示,它们主要由多个阶段和组件组成,例如通过后置过滤,候选聚集,行形成和字分割产生的误报消除。多个阶段和组件可能需要详尽的调整,导致性能欠佳,并增加了整个管道的处理时间。
In this paper, we devise a deep FCN-based pipeline that directly targets the final goal of text detection: word or textline level detection. As depicted in Fig. 2(e), the model abandons unnecessary intermediate components and steps, and allows for end-to-end training and optimization. The resultant system, equipped with a single, light-weighted neural network, surpasses all previous methods by an obvious margin in both performance and speed.
在本文中,我们设计了一个基于FCN的深层管道,直接针对文本检测的最终目标:单词或文本行级别检测。 如图2(e)所示,该模型放弃了不必要的中间组件和步骤,并允许端到端训练和优化。 最终的系统配备了单个轻量级神经网络,在性能和速度上都明显优于其他所有方法。

5.Methodology
The key component of the proposed algorithm is a neural network model, which is trained to directly predict the existence of text instances and their geometries from full images. The model is a fully-convolutional neural network adapted for text detection that outputs dense per-pixel predictions of words or text lines. This eliminates intermediate steps such as candidate proposal, text region formation and word partition. The post-processing steps only include thresholding and NMS on predicted geometric shapes. The detector is named as EAST, since it is an Efficient and Accuracy Scene Text detection pipeline.
该算法的关键组成部分是神经网络模型,该模型经过训练可以直接从全图像中预测文本实例的存在及其几何形状。 该模型是适用于文本检测的全卷积神经网络,可输出单词或文本行的每像素密集预测。这消除了中间步骤,例如候选提案,文本区域形成和单词划分。后处理步骤仅包括对预测的几何形状进行阈值处理和NMS。 该检测器被称为EAST,因为它是一种高效,准确的场景文本检测管道。
5.1.Pipeline
A high-level overview of our pipeline is illustrated in Fig. 2(e). The algorithm follows the general design of DenseBox [9], in which an image is fed into the FCN and multiple channels of pixel-level text score map and geometry are generated.
图2(e)说明了我们的管道的高级概述。 该算法遵循DenseBox [9]的一般设计,其中将图像馈入FCN,并生成像素级文本得分图和几何图形的多个通道。
One of the predicted channels is a score map whose pixel values are in the range of [0, 1]. The remaining channels represent geometries that encloses the word from the view of each pixel. The score stands for the confidence of the geometry shape predicted at the same location.
预测通道之一是分数图,其像素值在[0,1]的范围内。其余通道表示将单词的像素括起来的几何形状。分数代表在相同位置预测的几何形状的置信度。
We have experimented with two geometry shapes for text regions, rotated box (RBOX) and quadrangle (QUAD), and designed different loss functions for each geometry. Thresholding is then applied to each predicted region, where the geometries whose scores are over the predefined threshold is considered valid and saved for later non-maximum-suppression. Results after NMS are considered the final output of the pipeline.
我们针对文本区域尝试了两种几何形状,即旋转框(RBOX)和四边形(QUAD),并为每种几何设计了不同的损失函数。 然后将阈值应用于每个预测区域,在该区域中,分数超过预定义阈值的几何形状被视为有效并保存以供以后进行非最大抑制。NMS之后的结果被认为是管道的最终输出。
5.2.Network Design
Several factors must be taken into account when designing neural networks for text detection. Since the sizes of word regions, as shown in Fig. 5, vary tremendously, determining the existence of large words would require features from late-stage of a neural network, while predicting accurate geometry enclosing a small word regions need low level information in early stages.
在设计用于文本检测的神经网络时,必须考虑几个因素。如图5所示,由于单词区域的大小变化很大,因此确定大单词的存在将需要神经网络后期的特征,而预测包围小单词区域的准确几何形状则需要早期的低级信息。
Therefore the network must use features from different levels to fulfill these requirements. HyperNet [19] meets these conditions on features maps, but merging a large number of channels on large feature maps would significantly increase the computation overhead for later stages.
因此,网络必须使用不同级别的功能来满足这些要求。HyperNet [19]在特征图上满足了这些条件,但是在大型特征图上合并大量通道会大大增加后期的计算开销。
In remedy of this, we adopt the idea from U-shape [29] to merge feature maps gradually, while keeping the upsampling branches small. Together we end up with a network that can both utilize different levels of features and keep a small computation cost.
为了解决这个问题,我们采用了U型[29]的思想,可以逐渐合并特征图,同时保持较小的上采样分支。我们在一起最终得到了一个既可以利用不同级别的功能又可以保持少量计算成本的网络。
A schematic view of our model is depicted in Fig. 3. The model can be decomposed in to three parts: feature extractor stem, feature-merging branch and output layer.
我们的模型的示意图如图3所示。该模型可以分解为三个部分:特征提取器主干,特征合并分支和输出层。
The stem can be a convolutional network pre-trained on ImageNet [4] dataset, with interleaving convolution and pooling layers. Four levels of feature maps, denoted as f i f_i fi, are extracted from the stem, whose sizes are 1/32 , 1/16 , 1/8 and 1/4 of the input image, respectively. In Fig. 3, PVANet [17] is depicted. In our experiments, we also adopted the well-known VGG16 [32] model, where feature maps after pooling-2 to pooling-5 are extracted. In the feature-merging branch, we gradually merge them:
主干可以是在ImageNet [4]数据集上经过预训练的卷积网络,具有交织的卷积和池化层。 从主干中提取四个级别的特征图,表示为 f i f_i fi,其大小分别为输入图像的1/32,1/16,1/8和1/4。在图3中,描绘了PVANet [17]。 在我们的实验中,我们还采用了众所周知的VGG16 [32]模型,该模型提取了pool-2到pool-5之后的特征图。在功能合并分支中,我们逐渐将它们合并:
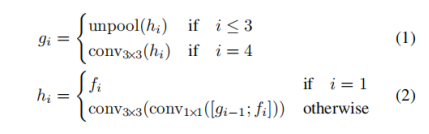
where g i g_i gi is the merge base, h i h_i hi and is the merged feature map, and the operator represents concatenation along the channel axis. In each merging stage, the feature map from the last stage is first fed to an unpooling layer to double its size, and then concatenated with the current feature map. Next, a conv1×1 bottleneck [8] cuts down the number of channels and reduces computation, followed by a conv3×3 that fuses the information to finally produce the output of this merging stage. Following the last merging stage, a conv3×3 layer produces the final feature map of the merging branch and feed it to the output layer.
其中 g i g_i gi是合并基础, h i h_i hi是合并要素图,而运算符 [ ⋅ ; ⋅ ] [·; ·] [⋅;⋅]表示沿着通道轴的串联。 在每个合并阶段,将从最后阶段开始的要素图首先馈送到上采样池化层,以使其尺寸加倍,然后与当前特征图连接。接下来,conv1×1瓶颈[8]减少了通道数量并减少了计算量,紧接着是conv3×3,它融合了信息以最终产生此合并阶段的输出。 在最后的合并阶段之后,conv3×3层将生成合并分支的最终特征图,并将其馈送到输出层。

The number of output channels for each convolution is shown in Fig. 3. We keep the number of channels for convolutions in branch small, which adds only a fraction of computation overhead over the stem, making the network computation-efficient. The final output layer contains several conv1×1 operations to project 32 channels of feature maps into 1 channel of score map F s F_s Fs and a multichannel geometry map F s F_s Fs . The geometry output can be either one of RBOX or QUAD, summarized in Tab. 1
每个卷积的输出通道数如图3所示。我们将分支中卷积的通道数保持较小,这仅增加了主干上计算开销的一小部分,从而使网络计算效率更高。最终输出层包含几个conv1×1操作,以将32个特征图通道投影到得分图和多通道几何图 F g F_g Fg的1个通道中。几何输出可以是RBOX或QUAD之一,汇总在Tab1中。
For RBOX, the geometry is represented by 4 channels of axis-aligned bounding box (AABB) R and 1 channel rotation angle θ. The formulation of R is the same as that in [9], where the 4 channels represents 4 distances from the pixel location to the top, right, bottom, left boundaries of the rectangle respectively.
对于RBOX,其几何形状由4个与轴对齐的边界框(AABB)R和1个通道旋转角度θ表示。 R的公式与[9]中的公式相同,其中4个通道分别代表从像素位置到矩形的顶部,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









