







《王道》第16章 查找
目录
1 查找基本概念
查找定义
根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。
查找算法分类
1)静态查找和动态查找;
注:静态或者动态都是针对查找表而言的。动态表指查找表中有删除和插入操作的表。
2)无序查找和有序查找。
无序查找:被查找数列有序无序均可;
有序查找:被查找数列必须为有序数列。
平均查找长度(Average Search Length,ASL)
ASL是衡量查找算法效率的最主要指标。
需和指定key进行比较的关键字的个数的期望值,称为查找算法在查找成功时的平均查找长度。
对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL = Pi*Ci的和。
Pi:查找表中第i个数据元素的概率。
Ci:找到第i个数据元素时已经比较过的次数。
适合静态查找表的查找方法有:顺序查找、折半查找、散列查找等;
适合动态查找表的查找方法有:二叉排序树的查找、散列查找等。
2 二分查找/折半查找
基本思想
属于有序查找算法。仅适用于事先已经排好序的顺序表。首先将给定的值K与表中中间位置元素的关键字比较,若相等,则查找成功,返回该元素的存储位置;若不等,则所需查找的元素只能在中间数据以外的前半部分或后半部分中。然后在缩小的范围内继续进行同样的查找,如此重复直到找到为止。
算法实现
#include <iostream>
using namespace std;
/*
二分查找思想:
1、数组从小到大排序;
2、查找的key每次和中间数比较,如果key小于mid,查找mid左侧的数组部分;
如果key大于mid,则查找mid右侧的数组部分;如果相等,则直接返回mid。
输入:排序数组-array,数组大小-aSize,查找值-key
返回:返回数组中的相应位置,否则返回-1
*/
//非递归查找
int Binary_Search(int *array, int aSize, int key)
{
if (array == NULL || aSize <= 0) //数组为空,返回 -1
return -1;
int low = 0;
int high = aSize - 1;
int mid = 0;
while (low <= high)
{
mid = (low + high) / 2;
if (array[mid] < key)
low = mid + 1;
else if (array[mid] > key)
high = mid - 1;
else
return mid;
}
return -1;
}
//递归
int Binary_Search_Recursive(int *array, int low, int high, int key)
{
whlie(low<=high)
{
int mid = (low + high) / 2;
if (array[mid] == key)
return mid;
else if (array[mid] < key)
return Binary_Search_Recursive(array, mid + 1, high, key);
else
return Binary_Search_Recursive(array, low, mid - 1, key);
}
return -1;
}
int main()
{
int array[10];
for (int i = 0; i<10; i++)
array[i] = i;
cout << "No recursive:" << endl;
cout << "position:" << Binary_Search(array, 10, 6) << endl;
cout << "recursive:" << endl;
cout << "position:" << Binary_Search_Recursive(array, 0, 9, 6) << endl;
return 0;
}算法分析
最坏的情况下查找次数为向下取整[log2n]+1,或向上取整[log2(n+1)]。
该查找法仅适合于线性表的顺序存储结构,不适合链式存储结构,且要求元素按关键字有序排列。
二分查找与判定树(可用于计算ASL)
二分查找是一种效率比较高的查找算法,但是它依赖于数组有序的存储,二分查找的过程可以用二叉树来形容描述:把当前查找区间的中间位置上的结点作为根,左子表和右子表中的结点分别作为根节点的左子树和右子树。由此得到的二叉树,称为描述二分查找树的判定树(Decision Tree)或比较树(Comprision Tree)。时间复杂度为O(logN)。
判定树的形态只与表结点个数N有关,与具体的数值无关。
10个结点的判定树如下:
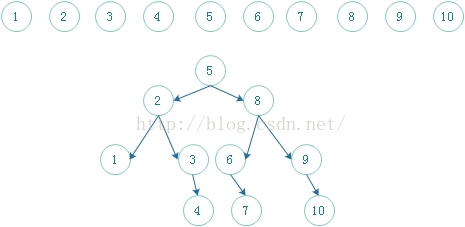
对于此图,我么可以得出:
查找成功的最少次数:1
查找成功最多的次数:4
查找成功的平均次数:(1 * 1 + 2 * 2 + 3 * 4 + 4 * 3) / (1 + 2 + 4 + 3) = 2.9 = 3次;
查找不成功的最少次数:3
查找不成功的最多次数:4
查找不成功的平均次数:(3 * 5 + 4 * 6) / (5 + 6) = 39 / 11 = 4次;
二分查找就是将给定值K与二分查找判定树的根节点的关键字进行比较。若相等,成功;小于根节点则在根节点的左边查找;大于根节点,则在根节点的右边查找。它是一颗序列号N的有序二叉树。
3 哈希表
3.1 哈希表的基本概念

3.2 哈希函数
1.哈希函数的特性
所有散列函数都有如下一个基本特性:如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。这个特性使散列函数具有确定性的结果,具有这种性质的散列函数称为单向散列函数。
典型的散列函数都有无限定义域,比如任意长度的字节字符串,和有限的值域,比如固定长度的比特串。
2. 常用哈希函数介绍
几种简单常用的散列函数:直接定址法、数字分析法、平方取中法、除留取余法、折叠法等,这些算法通常用于散列表中。
工业界比较著名的哈希函数:MD4,MD5,SHA-1。
问:哈希算法是否可以用来加密?
哈希就是把任意长度的输入通过哈希算法,变换成固定长度的输出,该输出就是哈希值。这种转换是一种压缩映射,使得散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一确定输入值。哈希算法是一种消息摘要算法,虽然哈希算法不是一种加密算法,但由于其单向运算,具有一定的不可逆性使其成为加密算法中的一个重要构成部分。
3.处理冲突的方法
链地址法、开放定址法、再散列法和建立一个公共溢出区。

说明:
在开放定址的情形下,不能随便删除表中已有元素,因为若删除元素将会截断其他具有相同散列地址的元素的查找地址。所以若想删除一个元素时,给它做一个删除标记,进行逻辑删除。但副作用是,在执行多次删除后,表面上看起来散列表很满,实际上有很多位置没有利用,因此需要定期维护散列表,要把做删除标记的元素物理删除。
采用链地址法处理长度时,哈希表查找成功的平均长度与哈希表的装填因子有关,装填因子=表中填入的记录数/哈希表长度。
4 一致性哈希
5 海量数据处理
所谓海量数据处理,就是基于海量数据的查找、统计、运算等操作。所谓海量数据,就是数据量太大,所以导致要么是无法在较短时间内迅速解决,要么是数据太大,导致无法一次性装入内存。从而导致传统的操作无法实现。
5.1 分治——Hash映射
堆也是海量数据处理经常采用的工具。















 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









