







一、问题分析
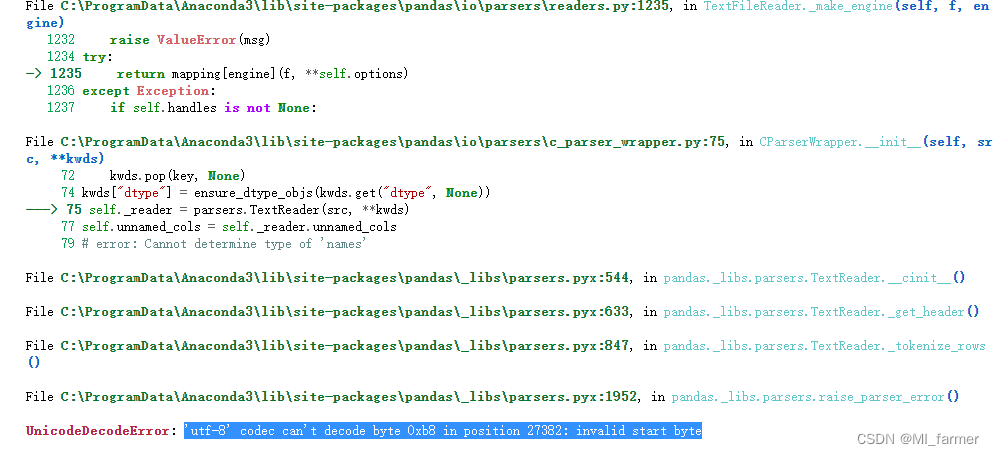
jupyter读取CSV文件报错'utf-8' codec can't decode byte 0xb8 in position 27382: invalid start byte,意思“utf-8”编解码器无法解码位置27382中的字节0xb8:起始字节无效。这是python在读取文件时非常容易遇到的一个编码问题。
二、解决办法
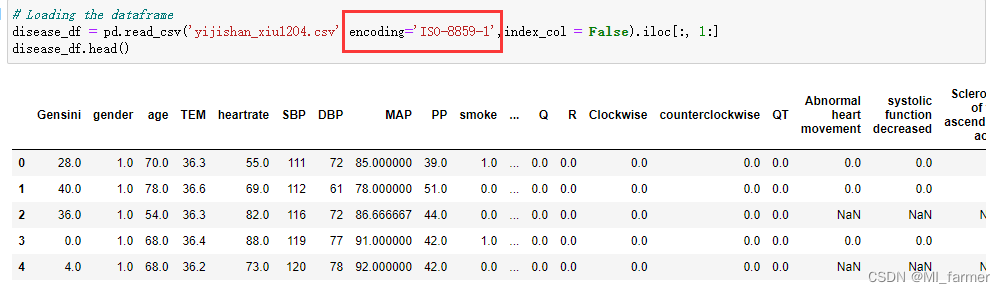
在读取文件时添加 encoding=‘ISO-8859-1’,即可解决上述问题。
有关utf-8编码和ISO-8859-1编码描述可参考iso-8859-1和utf-8有什么不同_scalad的博客-CSDN博客_iso8859-1和utf8


















 3133
3133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











