







目录
近期在工作中,遇到了Python的多线程和守护线程的问题,中间还被一篇文章误导了,所以感觉有必要根据查到的资料和自己的实践梳理一下关于python的多进程和多线程问题。
一:基础知识
线程:线程是CPU一个基本的执行单元。它必须依托于进程存活。一个线程是一个execution context(执行上下文),即一个 CPU 执行时所需要的一串指令。
进程:进程是指一个程序在给定数据集合上的一次执行过程,是系统进行资源分配和运行调用的独立单位。可以简单地理解为操作系统中正在执行的程序。也就说,每个应用程序都有一个自己的进程。
现在无论是PC还是服务器都是多核的,甚至还是多CPU的,使用多线程能充分利用 CPU 来提供程序的执行效率。
二:线程和守护线程,锁
Python用threading模块来创建线程,一般常用的有两种用法
2.1 线程创建
方法一:直接用threading.Thread()来创建一个线程
import time
import threading
def func(threadNum):
while True:
print(f"create thread:{threadNum}")
time.sleep(1)
if __name__ == '__main__':
thread_1 = threading.Thread(target=func, args=("1",))
thread_2 = threading.Thread(target=func, args=("2",))
thread_1.start()
thread_2.start()
程序运行结果:
create thread:1
create thread:2
create thread:1
create thread:2
create thread:2
create thread:1
create thread:2
...方法二:自定义类继承threading.Thread,重写run方法,在实际工程中,该方式用的比较多,可以根据业务需要灵活重写run方法
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
while True:
self.function()
time.sleep(1)
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.start()
pthread2 = thread_rewrite(2)
pthread2.start()
print("main")
程序运行结果:
create thread:1
create thread:2
main
create thread:1
create thread:2
create thread:1
create thread:2
create thread:1
create thread:2
...可以看到两种方法都可以实现多线程,上述可以看到,主函数里的”main”打印出来了,主线程走到了最后一行代码,然后程序并没有退出,而是两个线程依然都在打印。
需要强调的是:运行完毕并非终止运行
1.对主进程来说,运行完毕指的是主进程代码运行完毕
2.对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
2.2 守护线程
上面我们直接创建的线程没有对线程本身都任何设置,就是上面提到的非守护进程。那么什么是守护进程,守护进程有什么作用呢。还是先通过代码来直观感受一下有什么区别
例1:
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
while True:
self.function()
time.sleep(1)
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
#pthread2 = thread_rewrite(2)
#pthread2.start()
print("main")
程序运行结果:
create thread:1
main
我们在run函数中调整一下sleep的顺序,先sleep再执行function函数
例二:
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
while True:
time.sleep(1)
self.function()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
#pthread2 = thread_rewrite(2)
#pthread2.start()
print("main")
程序运行结果:
main在例1中,通过调用setDaemon(True)方法将线程1设置成守护线程,先打印create thread:1然后main,程序就退出了,在例二中,甚至还没打印create thread:1只打印了主线程中的main程序就退出了。
原因是:例1中主进程程序启动执行到pthread1 子线程,打印出create thread:1,遇到sleep,由于需要耗费时间,所以回到主线程中继续往下执行打印出main,由于主线程执行完毕,那么守护子进程pthread1 也就被干掉了,随之进程也就退出了。这就是守护线程与非守护线程的不同之处,守护线程随着主线程只执行完毕就退出了,对于非守护线程运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕。所以例二就很好解释了,执行到pthread1 首先就遇到了sleep,程序回到主线程往下执行,执行到main,主线程执行完退出,守护线程create thread:1随之退出,故根本来不及打印create thread:1。
在这个地方被博客园上面的一篇文章就给误导了,具体哪一篇就不提了,给个截图吧
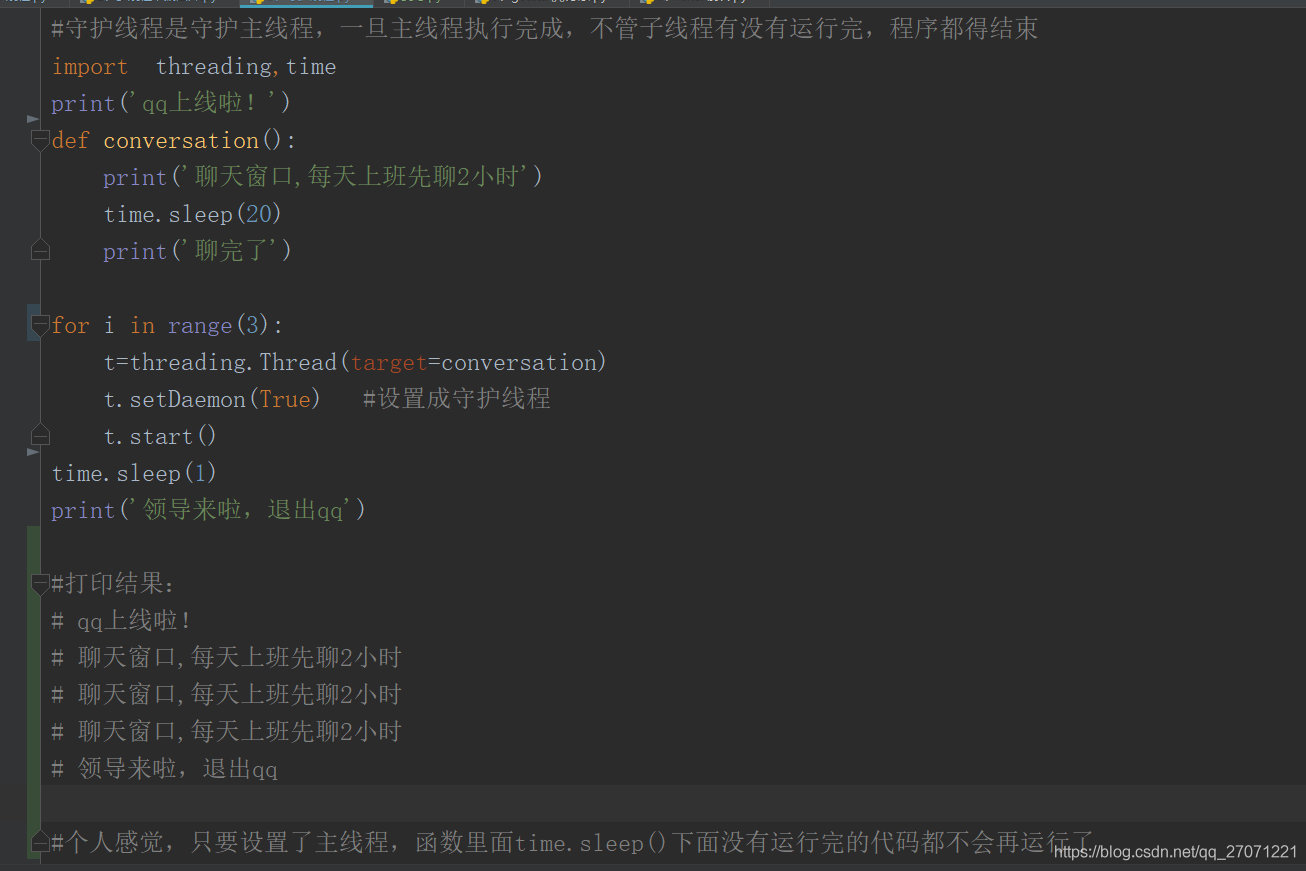
如果想让守护线程执行完再退出,可以用join,来等待守护线程执行完
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
while True:
time.sleep(1)
self.function()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
pthread1.join()
#pthread2 = thread_rewrite(2)
#pthread2.start()
print("main")
程序运行结果:
create thread:1
create thread:1
create thread:1
create thread:1
create thread:1
...
join是起到阻塞作用,子线程执行完毕,才执行主线程,所以加上join
1、执行到join,是起到阻塞作用,就会执行子线程,然后执行完毕,在执行主进程
2、本例中执行到join,会进守护线程执行,由于守护线程里面执行的是一个死循环,永远执行不完,所以主进程永远不会退出,守护进程不会被干掉,继续执行,当然守护线程没执行完也不会在主线程中执行print("main"),所以只会打印create thread:1
2.3 守护线程和非守护线程并存的情况
先看一段守护线程和非守护线程并存的代码
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
while True:
time.sleep(1)
self.function()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
pthread2 = thread_rewrite(2)
pthread2.start()
print("main")
程序运行结果:
main
create thread:2
create thread:1
create thread:2
create thread:1
create thread:2
create thread:1
...可以看到本例中,我把守护线程的join去掉了,两个线程的打印都出来了,而且一直打印着,主线程没有退出。还是上面说到的,主线程退出的条件是主线程所在的进程内所有非守护线程统统运行完毕,本例中非守护线程是一个死循环永远不会退出,故守护线程也不会退出。
那假如说,非守护线程不是一个死循环,执行完非守护线程主线程退出,守护线程执行到一半是什么情况呢
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
#while True:
time.sleep(1)
self.function()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
pthread2 = thread_rewrite(2)
pthread2.start()
print("main")
这个程序根据时机不同会有两个不一样的运行结果
结果一:
main
create thread:1
create thread:2
结果二:
main
create thread:2
Fatal Python error: could not acquire lock for <_io.BufferedWriter name='<stdout>'> at interpreter shutdown, possibly due to daemon threads
Thread 0x00007ff6fe8cb700 (most recent call first):
File "processSetDaemon.py", line 10 in function
File "processSetDaemon.py", line 15 in run
File "/usr/lib64/python3.6/threading.py", line 916 in _bootstrap_inner
File "/usr/lib64/python3.6/threading.py", line 884 in _bootstrap
Current thread 0x00007ff7064f0740 (most recent call first):
Aborted
为什么会出现上面的两种运行结果?这就是守护线程和非守护线程一起使用时需要注意的问题,当执行完非守护线程,主进程执行到print("main"),进程退出之前去结束守护线程,但是守护线程刚好还在sleep阶段,这时候结束守护线程就会出错,触发异常。对于上面的程序延长sleep时间,出错的概率会大大增加。为了避免这个情况,守护线程加上join,等待守护线程执行完毕再退出
正确的程序:
import time
import threading
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function(self):
print(f"create thread:{self.threadNum}")
def run(self):
#while True:
time.sleep(3)
self.function()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread1.setDaemon(True)
pthread1.start()
pthread2 = thread_rewrite(2)
pthread2.start()
pthread1.join()
print("main")
程序运行结果:
create thread:2
create thread:1
main
总结一下:
1 主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束,
2 主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
2.4 锁的基本用法
在多线程场景中,很多时候会用到线程锁。比如多个线程对同一个变量进行操作,如果不设置锁,就会出现线程竞争的情况,操作变得不可控。
下面写一个程序,两个线程对同一个变量进行加1操作,如果不加锁会是什么情况
import time
import threading
addNum = 0;
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function_add(self):
global addNum;
addNum += 1;
time.sleep(0.5)
if addNum <= 10:
print(f"create thread:{self.threadNum},The addNum is {addNum}")
self.function_add()
else:
print(f"thread {self.threadNum} exit!")
def run(self):
#while True:
self.function_add()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread2 = thread_rewrite(2)
pthread1.start()
pthread2.start()
print("main")
程序运行结果:
main
create thread:1,The addNum is 2
create thread:2,The addNum is 2
create thread:1,The addNum is 4
create thread:2,The addNum is 5
create thread:2,The addNum is 6
create thread:1,The addNum is 7
create thread:2,The addNum is 8
create thread:1,The addNum is 9
create thread:2,The addNum is 10
thread 1 exit!
thread 2 exit!
可以看到对addNum 的操作会变得不可控,那看一下加锁后的效果
import time
import threading
mutex = threading.Lock()
addNum = 0;
class thread_rewrite(threading.Thread):
def __init__(self,threadNum):
super(thread_rewrite, self).__init__()
self.threadNum = threadNum
def function_add(self):
global addNum;
mutex.acquire()
addNum += 1;
time.sleep(0.5)
mutex.release()
if addNum <= 10:
print(f"create thread:{self.threadNum},The addNum is {addNum}")
self.function_add()
else:
print(f"thread {self.threadNum} exit!")
def run(self):
#while True:
self.function_add()
if __name__ == '__main__':
pthread1 = thread_rewrite(1)
pthread2 = thread_rewrite(2)
pthread1.start()
pthread2.start()
print("main")
程序运行结果:
main
create thread:1,The addNum is 1
create thread:2,The addNum is 2
create thread:1,The addNum is 3
create thread:2,The addNum is 4
create thread:1,The addNum is 5
create thread:2,The addNum is 6
create thread:1,The addNum is 7
create thread:2,The addNum is 8
create thread:1,The addNum is 9
create thread:2,The addNum is 10
thread 1 exit!
thread 2 exit!
在上面的代码中,threading.Lock()实例化了一个锁对象,锁对象有两个方法:acquire和release,分别是获得锁和释放锁。当一个线程获得所时,另外一个线程在acquire处阻塞,直到当前锁执行release被释放后才可以和其他线程共同争夺锁。acquire和release之间的代码段执行时不会切换到其他线程,保证了操作的完整性。
三:多进程和守护进程
Python的多线程在多核CPU上,只对于IO密集型计算产生正面效果;而当有至少有一个CPU密集型线程存在,那么多线程效率会由于GIL而大幅下降。multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。当然multiprocess也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。就拿计数器来举例子,如果我们要多个线程累加同一个变量,对于thread来说,申明一个global变量,用thread.Lock的context包裹住三行就搞定了。而multiprocess由于进程之间无法看到对方的数据,只能通过在主线程申明一个Queue,put再get或者用share memory的方法。
下面我们还是通过代码来学习一下多进程和守护进程
3.1 多进程创建
类似子线程,创建子进程也有两种方法
方法1:直接使用Process
import time
from multiprocessing import Process
def function(subProcessNum):
time.sleep(1)
print(f"create subprocess:{subProcessNum}")
if __name__ == '__main__':
process1 = Process(target=function, args=(1,))
process2 = Process(target=function, args=(2,))
process1.start()
process2.start()
process1.join()
process2.join()
print("main")
程序运行结果:
create subprocess:1
create subprocess:2
main
方法2:继承Process来自定义进程类,重写run方法
import time
from multiprocessing import Process
class process_rewrite(Process):
def __init__(self,subProcessNum):
super(process_rewrite, self).__init__()
self.subProcessNum = subProcessNum
def function(self):
time.sleep(1)
print(f"create subprocess:{self.subProcessNum}")
def run(self):
#while True:
self.function()
if __name__ == '__main__':
process1 = process_rewrite(1)
process2 = process_rewrite(2)
process1.start()
process2.start()
print("main")
程序运行结果:
main
create subprocess:1
create subprocess:2
子进程join的用途和子线程的join是一样的,都是等待该子进程执行完,这里就不再细说了
3.2 守护进程创建
主进程创建守护进程
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
注意:进程之间是互相独立的,主进程代码运行结束,守护进程随即终止
import time
from multiprocessing import Process
class process_rewrite(Process):
def __init__(self,subProcessNum):
super(process_rewrite, self).__init__()
self.subProcessNum = subProcessNum
def function(self):
time.sleep(1)
print(f"create subprocess:{self.subProcessNum}")
def run(self):
#while True:
self.function()
if __name__ == '__main__':
process1 = process_rewrite(1)
process1.daemon = True
process1.start()
process1.join()
print("main")
程序运行结果:
create subprocess:1
main创建了守护进程process1,由于掉了join会先把守护进程执行完,再接着执行主进程,如果没有join,则遇到proceess1里面的sleep,会继续执行主进程到print("main")主进程退出,守护进程也会随之退出
四:选择多线程还是多进程
在这个问题上,首先要看下你的程序是属于哪种类型的。一般分为两种 CPU 密集型 和 I/O 密集型。
CPU 密集型:程序比较偏重于计算,需要经常使用 CPU 来运算。例如科学计算的程序,机器学习的程序等。
I/O 密集型:顾名思义就是程序需要频繁进行输入输出操作。爬虫程序就是典型的 I/O 密集型程序。
如果程序是属于 CPU 密集型,建议使用多进程。而多线程就更适合应用于 I/O 密集型程序。
在实际项目中,由于python的内存回收机制没有C语言那样可以由开发人员自己申请自己释放,而是有专门的机制回收,有时候就会导致内存使用不可控,不能及时释放,对于耗内存的任务可以用子进程的方式,任务在子进程里执行,执行完子进程退出,任务所使用的内存立马释放。
















 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











