










 本文介绍了使用Python的Selenium库进行模拟浏览器操作,包括安装Chrome驱动、元素定位与交互、页面控制、模拟点击与拖拽、键盘事件、获取页面信息、处理多窗口与iframe、处理警告框、文件上传、cookies操作、JavaScript执行、页面截图以及处理动态加载内容。Selenium使得动态渲染页面和复杂交互的爬虫变得可能,如处理Ajax、ECharts图表、淘宝页面等。
本文介绍了使用Python的Selenium库进行模拟浏览器操作,包括安装Chrome驱动、元素定位与交互、页面控制、模拟点击与拖拽、键盘事件、获取页面信息、处理多窗口与iframe、处理警告框、文件上传、cookies操作、JavaScript执行、页面截图以及处理动态加载内容。Selenium使得动态渲染页面和复杂交互的爬虫变得可能,如处理Ajax、ECharts图表、淘宝页面等。
前言
Ajax其实也是JavaScript动态渲染的页面的一种情形,不过JavaScript 动态渲染的页面不止Ajax 这一种: 比如中国青年网(详见 http://news.youth.cn/gn/ ), 它的分页部分是由 JavaScript 生成的,并非原始 HTML代码,这其中并不包含 Ajax 请求。 比如 ECharts 的官方实例(详见 http: //echarts.baidu.com/demo.html#bar-negative ),其图形都是经过 JavaScript 计算之后生成的。 再有淘宝这种页面,它即使是Ajax 获取的数据,但是其 Ajax 接口含有很多加密参数,我 一一 们难以直接找出其规律,也很难直接分析 Ajax 来抓取。
为了解决这些问题,我们可以直接使用模拟浏览器运行的方式来实现, 这样就可以做到在浏览器 中看到是什么样,抓取的源码就是什么样,也就是可见即可爬,这样我们就不用再去管网页内部的 JavaScript用了什么算法渲染页面,不用管网页后台的A jax 接口到底有哪些参数.
Python 提供了许多模拟浏览器运行的库,如 Selenium、 Splash、 PyV8、 Ghost
1、二 安装驱动``python
安装浏览器和驱动,并将驱动路径r’D:\anaconda2021\Scripts\chromedriver.exe’
我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,“F:\GeckoDriver”目录添加到Path的值中。比如:Path字段;D:\anaconda2021\Scripts\chromedriver.exe
2. selenium定位操作
- find_element_by_id() #id查找获取
- find_element_by_name() #name属性
- find_element_by_class_name() #class属性
- find_element_by_tag_name() #标签名字
- find_element_by_link_text() #可点击的文本查找
- find_element_by_xpath() #通过xpath表达式**
- find_element_by_css_selector() #css选择器****
driver=webdriver.Chrome() #实例化一个浏览器
driver.get('https://www.baidu.com') #浏览器访问百度
input_tag=driver.find_element_by_id('kw') #获取输入框
input_tag.send_keys('赵丽颖')#输入框中输入‘赵丽颖
driver.find_element_by_id('su').click() #找到’百度一下‘按钮,并点击,开始搜索
driver.find_element_by_link_text('知道').click() #点击页面上的 ’知道‘
find_element_by_id('kw'):
find_element_by_link_text('知道')
3 浏览器控制相关操作函数
设置浏览器窗口大小:driver.set_window_size(480, 800)
回退到上一个访问页面:driver.back()
前进到下一个访问页面:driver.forward()
drive.quit() #退出浏览器
#设置浏览器显示窗口大小
driver.set_window_size(480,800)
driver.get('https://www.zhihu.com') #访问知乎
driver.back() #回退到上一个访问页面
driver.forward() #前进到下一个访问过的页面
drive.quit() #退出浏览器
4 webdriver常用的方法
点击和输入
click() 点击
send_keys(value) 输入值
clear() 清空输入
driver=webdriver.Chrome() #实例化一个浏览器
driver.get('https://www.baidu.com') #浏览器访问百度
input_tag.send_keys('赵丽颖')#输入框中输入‘赵丽颖
driver.find_element_by_id('kw').clear() #清空输入框
driver.find_element_by_id('kw').send_keys('周杰伦') #输入查询 ’周杰伦‘
driver.find_element_by_id("su").click() #点击百度一下
size 元素对应的大小
text 获取对应元素的文字
# 属性 size和文本
driver.get('http://www.baidu.com')
driver.find_element_by_id('kw').size #获取搜索的元素的尺寸{'height': 22, 'width': 395}
driver.find_element_by_id("cp").text #获取指定标签的文本值
driver.quit()
5 鼠标事件/ActionChains(动作链)
在 WebDriver 中, 将这些关于鼠标操作的方法封装在 ActionChains 类提供。
perform():执行所有ActionChains中存储的所有行为
context_click():右击
double_click():双击
drag_and_drop():拖动
move_to_element():悬浮
click_and_hold():鼠标按住不松手
move_to_lelment():拖动到某元素
move_by_offset(xoffset=50,yoffset=60):按坐标移动
执行流程
1 定位到响应元素
2 ActionChains(实例化的浏览器).鼠标操作(带操作的元素).perform() 使用(什么浏览器),用什么鼠标操作功能,操作(什么元素),perform()提交给浏览器执行响应的行为
#引入 ActionChains类
from selenium.webdriver.common.action_chains import ActionChains
driver=webdriver.Chrome()
driver.get("https://www.baidu.cn")
#鼠标定位到需要悬浮的元素
above=driver.find_element_by_link_text('设置')
ditu=driver.find_element_by_link_text('地图')
#对定位的元素执行鼠标操作
ActionChains(driver).move_to_element(above).perform()
ActionChains(driver).double_click(above).perform() #鼠标右击
driver.quit() #退出
拖拽滑块移动小实例
from selenium import webdriver
from selenium.webdriver import ActionChains #导入动作链
import time
browser = webdriver.Chrome()
url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
#必须转内部网页(html套html格式),否则拿不到数据
browser.switch_to.frame('iframeResult')
#获取被拖动的物体,和拖动到的目标元素
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
#实例动作链对象
actions = ActionChains(browser)
#执行一系列动作
# actions.drag_and_drop(source, target)
actions.click_and_hold(source).perform() #鼠标选取并按住元素source,不松手
time.sleep(1)
actions.move_to_element(target).perform() #拖动元素到target的位置
time.sleep(1)
actions.move_by_offset(xoffset=50,yoffset=0).perform() #在目标位置进行偏移拖动
actions.release() #释放动作链
6. 键盘事件
1 引入Keys 模块: from selenium.webdriver.common.keys import Keys
2 通过send_keys()发送信息
3 组合形式 Keys.BACK_SPACE 删除键
Keys.SPACE 空格键
Keys.F1 键盘F1键
Keys.CONTROL,'a' 全选 contrl表示contrl键
#引入Keys模块
from selenium.webdriver.common.keys import Keys
driver=webdriver.Chrome()
driver.get('https://www.baidu.com')
#输入一个内容
input=driver.find_element_by_id('kw')
input.send_keys('seleniumGG')
#删除多余的GG
input.send_keys(Keys.BACKSPACE)
input.send_keys(Keys.BACKSPACE)
#继续输入
input.send_keys('教程')
#全选输入框的内容,一次性删除
input.send_keys(Keys.CONTROL,'a')
input.send_keys(Keys.BACKSPACE)
#输入周杰伦,通过回车键来代替点击'百度一下'
input.send_keys('周杰伦')
input.send_keys(Keys.ENTER)
driver.quit()
7.获取信息
掌握三个属性
title:用于获得当前页面的标题。
current_url:用户获得当前页面的URL。
text:获取搜索条目的文本信息。
tag_name:获取标签名
get_attribute(‘id’) :获取id的属性值
#调用方式
driver.title #返回当前页面的标题
driver.current_url #返回当前页面的url
user = driver.find_element_by_class_name('nums').text #获取某元素的文本信息
user = driver.find_element_by_class_name('nums').tag_name
user = driver.find_element_by_class_name('nums').get_attribute('id')
8.定位一组元素
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
a_list=driver.find_elements_by_xpath('//div[@id="u1"]/a')
#获取图片中的a标签文本信息
from time import sleep
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
a_list=driver.find_elements_by_xpath('//div[@id="u1"]/a')
for a in a_list:
print(a.text)
driver.quit()
9. 多表单切换(人人网登录)
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.renren.com/")
#输入账户密码
driver.find_element_by_id('email').send_keys('1837081**31(账号)') #换成自己的账号
driver.find_element_by_id('password').send_keys('QWERT***IO(密码)') #换成自己的密码
#点击登录
driver.find_element_by_id('login').click()
driver.quit()
10. 多窗口切换
driver.switch_to_window(某窗口)
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get("http://www.baidu.com")
#获取百度搜索窗口句柄
search_windows=driver.current_window_handle
driver.find_element_by_link_text('登录').click()
driver.find_element_by_link_text('立即注册').click()
#获取当前窗口句柄
register_windows=driver.current_window_handle
driver.switch_to_window(search_windows) #浏览器跳转记录的窗口
11.警告框的处理
1 获取警告框 dialog=driver.switch_to_alert
2 dialog.accept() 或者 dialog.send_keys(1) text:返回 alert/confirm/prompt 中的文字信息。
基本方法
accept():接受现有警告框。
dismiss():解散现有警告框。
send_keys(keysToSend):发送文本至警告框。keysToSend:将文本发送至警告框。
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import time
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
# 鼠标悬停至“设置”链接
link = driver.find_element_by_link_text('设置')
ActionChains(driver).move_to_element(link).perform()
# 打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
# 保存设置
driver.find_element_by_class_name("prefpanelgo").click()
time.sleep(2)
#获取警告框对象
dialog=driver.switch_to_alert()
dialog.text #获取警告框的内容
dialog.accept() #接受结果,确认
driver.quit()
12.下拉框选择
#核心代码
from selenium.webdriver.support.select import Select
#搜索结果显示条数设置
sel=driver.find_element_by_xpath('//*[@id="nr"]')
Select(sel).select_by_value('10')
#第一步导包
from selenium import webdriver
from selenium.webdriver.support.select import Select
from time import sleep
#驱动网页
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
# 鼠标悬停至“设置”链接
driver.find_element_by_link_text('设置').click()
sleep(1)
# 打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
sleep(2)
#搜索结果显示条数设置
sel=driver.find_element_by_xpath('//*[@id="nr"]')
Select(sel).select_by_value('10')
#保存并关闭
driver.find_element_by_class_name('prefpanelgo').click()
#处理警告框
#1 获取警告框对象
dialog=driver.switch_to_alert()
#2 打印文本值
print(dialog.text) #已经记录下您的使用偏好
#3 接受
dialog.accept()
driver.quit()
13.文件上传
定位上传按钮,添加本地文件 -
driver.find_element_by_name("file").send_keys('D:\upload_file.txt')
14cookie操作
- get_cookies(): 获得所有cookie信息。
- get_cookie(name): 返回字典的key为“name”的cookie信息。
- add_cookie(cookie_dict) : 添加cookie。“cookie_dict”指字典对象,必须有name 和value 值。
- delete_cookie(name,optionsString):删除cookie信息。“name”是要删除的 - cookie的名称,“optionsString”是该cookie的选项,目前支持的选项包括“路径”,“域”。
- delete_all_cookies(): 删除所有cookie信息。
实际使用
cookie= driver.get_cookies() #获取cookie
driver.add_cookie({'name': 'key-aaaaaaa', 'value': 'value-bbbbbb'}) #添加cookie
15.调用JavaScript代码
-
window.scrollTo(0,450); #滑动条往下滑动450
-
执行方式 js=“window.scrollTo(100,450);”
-
driver.execute_script(js)
js='window.scrollTo(0,document.body.scrollHeight)' #下滑到底部
driver.execute_script(js)
16 窗口截图
截取当前窗口,并指定截图图片的保存位置
- driver.get_screenshot_as_file(“D:\baidu_img.jpg”)
17关闭浏览器
- close() 关闭单个窗口
- quit() 关闭所有窗口
18. 显示等待与隐式等待
延时等待一定时间,确保节点已经加载出来。这里等待的方式有两种:一种是隐式等待,一种是显式等待。
隐式等待:
当使用隐式等待执行测试的时候,如果Selenium没有在DOM中找到节点,将继续等待,超出设定时间后,则抛出找不到节点的异常。
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10)
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents)
browser.close()
显示等待
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
browser=webdriver.Chrome()
browser.get('https://www.baidu.com')
input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
#显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left')))
contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents)
browser.close()
19. cookies操作
使用Selenium,还可以方便地对Cookies进行操作,例如获取、添加、删除Cookies等。示例如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name': 'name', 'domain': 'www.zhihu.com', 'value': 'germey'}) #添加cookie
print(browser.get_cookies()) #获取cookies
browser.delete_all_cookies() #删除所有的cookies
print(browser.get_cookies()) #获取cookies
20 .异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
#三个异常:超时,没有这个元素,使用switch_to_frame出现的没有这个子html错误
try:
browser=webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframssseResult')
except TimeoutException as e:
print(e)
except NoSuchFrameException as e:
print(e)
finally:
browser.close()
21.获取网页源码(****)
- driver.page_source
#互动到页面底部js
window.scrollTo(0,document.body.scrollHeight)
22. phantotomJs
from selenium import webdriver
from time import sleep
bro = webdriver.PhantomJS(executable_path='./phantomjs-2.1.1-windows/bin/phantomjs.exe')
sleep(2)
bro.get(url='https://www.baidu.com/')
sleep(3)
text_input = bro.find_element_by_id('kw')
text_input.send_keys('周杰伦')
sleep(2)
btn = bro.find_element_by_id('su')
btn.click()
sleep(3)
#浏览器执行js代码
js = 'window.scrollTo(0,document.body.scrollHeight)'
bro.execute_script(js)
sleep(3)
#截屏
bro.save_screenshot('./ppppppp.png')
#获取当前浏览器显示的页面数据
page_text = bro.page_source #页面数据也包含动态加载出来的数据
print(page_text)
bro.quit()
23 内联表iframe
from selenium import webdriver
driver = webdriver.Firefox()
driver.switch_to.frame(0) # 1.用frame的index来定位,第一个是0
driver.switch_to.frame("frame1") # 2.用id来定位
driver.switch_to.frame("myframe") # 3.用name来定位
driver.switch_to.frame(driver.find_element_by_tag_name("iframe")) # 4.用WebElement对象来定位
browser.switch_to.parent_frame() # 退出顶级页面
browser.switch_to.default_content() # 退出顶级页面
iframe是个特殊的标签,相当于在网页内部重新嵌套一个网页。如果selenium要操作iframe里面的元素,则需要先切入iframe。selenium操作iframe方法如下:
1、selenium切换到iframe(定位iframe)
1)iframe有id(理论上id本来就是唯一的),直接写id
driver.switch_to_frame(“xxx”)
2)有name且唯一,直接写name
driver.switch_to_frame(“xxxx”)
3)通过索引切换
driver.switch_to_frame(0) # 第一个iframe
4)先定位iframe元素再切换
iframe = driver.find_elements_by_xxxx
driver.switch_to_frame(iframe)
2、frame嵌套
1)从frame中切回主文档
switch_to.default_content()
2)切到父文档(相当于后退)
switch_to.parent_frame()
3)如果iframe1嵌套iframe2,从主文档切到iframe2需要先切入iframe1再切iframe2。
selenium要操作iframe比较简单,下节课我们用网易邮箱测试下,网页邮箱登陆元素就是在iframe里面的。
进入到iframe
<html lang="en">
<head>
<title>FrameTest</title>
</head>
<body>
<iframe src="a.html" id="frame1" name="myframe"></iframe>
</body>
</html>
想要定位其中的iframe并切进去,可以通过如下代码:
from selenium import webdriver
driver = webdriver.Chrome()
driver.switch_to.frame(0) # 1.用frame的index来定位,第一个是0
driver.switch_to.frame("frame1") # 2.用id来定位
driver.switch_to.frame("myframe") # 3.用name来定位
driver.switch_to.frame(driver.find_element_by_tag_name("iframe")) # 4.用WebElement对象来定位
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get("xxxxx")
driver.maximize_window()
sleep(3)
driver.switch_to.frame("loginIframe")
# 定位到 frame 页面。id=loginIframe
driver.find_element_by_id("username").clear()
driver.find_element_by_id("username").send_keys("123")
driver.find_element_by_id("password").send_keys("123456")
driver.find_element_by_id("btnLogin").click()
driver.quit()
退出iframe
driver.switch_to.default_content()
嵌套iframe
<html>
<iframe id="frame1">
<iframe id="frame2" / >
</iframe>
</html>
从主文档切到frame2,一层层切进去
driver.switch_to.frame("frame1")
driver.switch_to.frame("frame2")
从frame2再切回frame1,这里selenium给我们提供了一个方法能够从子frame切回到父frame,而不用我们切回主文档再切进来。
driver.switch_to.parent_frame() # 如果当前已是主文档,则无效果
有了parent_frame()这个相当于后退的方法,我们可以随意切换不同的frame,随意的跳来跳去了。
所以只要善用以下三个方法,遇到frame分分钟搞定:
driver.switch_to.parent_frame()
driver.switch_to.default_content()
实战
01.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>左侧</title>
<script type="text/javascript">
function dispalay_alert() {
alert('I am alert...')
}
</script>
</head>
<body>
<p>这是左侧frame上的文字</p>
<input type="button" onclick="dispalay_alert()" value="Display alert box">
</body>
</html>
02.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>右侧</title>
</head>
<body>
<p>这是右侧frame上的文字</p>
<input type="radio" id="python" name="book" checked>python selenium
<br />
<input type="radio" id="java" name="book">java selenium
</body>
</html>
03.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>中间</title>
</head>
<body>
<p>这是中间frame上的文字</p>
<input type="input" id="text" >文本框
</body>
</html>
04.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>综合</title>
<frameset cols="25%,50%,25%">
<frame id="leftframe" src="01.html" />
<frame id="middleframe" src="03.html" />
<frame id="rightframe" src="02.html" />
</frameset>
</head>
<body>
<p>这是中间frame上的文字</p>
<input type="button" id="text" >文本框
</body>
</html>
把所有文件放在一个目录下,打开04.html,页面如下
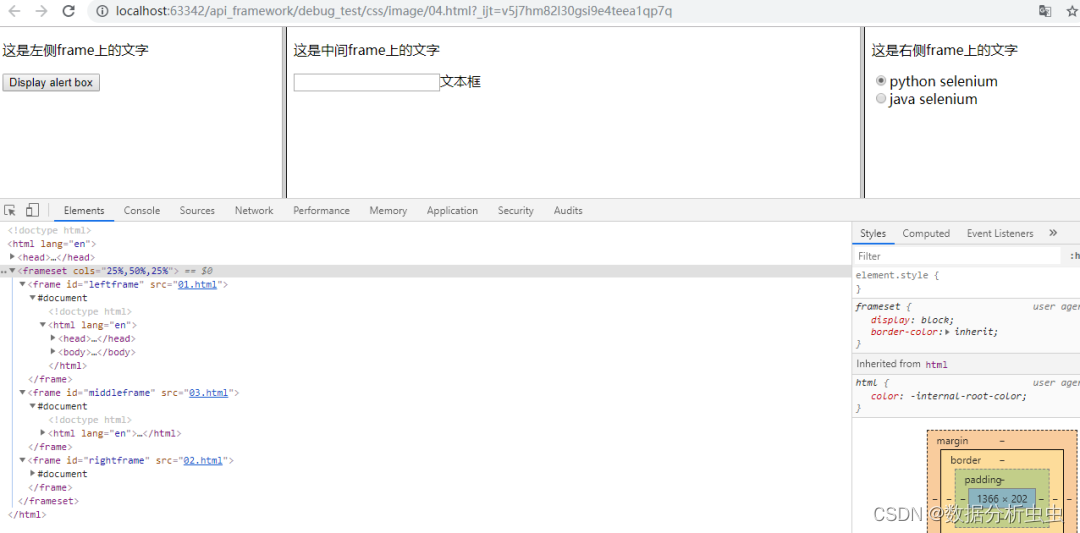
代码如下
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
class Test_frame():
def test_handle_frame(self):
url = r'F:\api_framework\debug_test\css\image\04.html'
self.driver = webdriver.Chrome()
self.driver.get(url)
'''
使用索引方式进入frame页面,索引号从0开始
如果想进入中间的frame,则索引为1
'''
self.driver.switch_to.frame(0)
'''
找到左侧frame中的p标签
'''
leftFrame = self.driver.find_element_by_xpath('//p')
self.driver.find_element_by_tag_name('input').click()
try:
'''
等待alert弹框
'''
alertWindow = WebDriverWait(self.driver, 10, 0.2).until(EC.alert_is_present())
time.sleep(2)
print(alertWindow.text) # 获取弹出框内的内容
alertWindow.accept() # 对弹出框点击确定
except Exception as e:
print(e)
'''
使用driver.switchTo.default_content方法,从左侧中回到frameset页面
如果不执行,则无法进入到其他frame中
'''
self.driver.switch_to_default_content()
'''
通过标签名找到页面中所有frame元素,然后通过索引进入frame
'''
self.driver.switch_to.frame(self.driver.find_elements_by_tag_name('frame')[1])
'''
断言
'''
assert '这是中间frame上的文字' in self.driver.page_source
self.driver.find_element_by_tag_name('input').send_keys('我在中间')
self.driver.switch_to_default_content()
'''
通过id进入右边的iframe
'''
self.driver.switch_to.frame(self.driver.find_element_by_id('rightframe'))
assert '这是右侧frame上的文字' in self.driver.page_source
self.driver.find_element_by_id('java').click()
self.driver.switch_to_default_content()
test1 = Test_frame()
test1.test_handle_frame()
通过循环frame操作frame
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
import time
class Test_frame():
def test_handle_frame(self):
url = r'F:\api_framework\debug_test\css\image\04.html'
self.driver = webdriver.Chrome()
self.driver.get(url)
'''
找到页面上所有的frame对象,并存到列表中
'''
frameList = self.driver.find_elements_by_tag_name('frame')
'''
通过循环遍历列表中的所有frame页面,
'''
for frame in frameList:
self.driver.switch_to.frame(frame)
if "中间" in self.driver.page_source:
p = self.driver.find_elements_by_xpath('p')
print('找到你了。。。')
break
else:
self.driver.switch_to_default_content()
test1 = Test_frame()
test1.test_handle_frame()
实例
selenium+phantomjs 就是爬虫终极解决方案
有些网站上的内容信息是通过动态加载js形成的,所以使用普通爬虫程序无法回去动态加载的js内容。例如豆瓣电影中的电影信息是通过下拉操作动态加载更多的电影信息。
from selenium import webdriver
from time import sleep
import time
if __name__ == '__main__':
url = 'https://movie.douban.com/typerank?type_name=%E6%81%90%E6%80%96&type=20&interval_id=100:90&action='
# 发起请求前,可以让url表示的页面动态加载出更多的数据
path = r'C:\Users\Administrator\Desktop\爬虫授课\day05\ziliao\phantomjs-2.1.1-windows\bin\phantomjs.exe'
# 创建无界面的浏览器对象
bro = webdriver.PhantomJS(path)
# 发起url请求
bro.get(url)
time.sleep(3)
# 截图
bro.save_screenshot('1.png')
# 执行js代码(让滚动条向下偏移n个像素(作用:动态加载了更多的电影信息))
js = 'window.scrollTo(0,document.body.scrollHeight)'
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(2)
bro.execute_script(js) # 该函数可以执行一组字符串形式的js代码
time.sleep(2)
bro.save_screenshot('2.png')
time.sleep(2)
# 使用爬虫程序爬去当前url中的内容
html_source = bro.page_source # 该属性可以获取当前浏览器的当前页的源码(html)
with open('./source.html', 'w', encoding='utf-8') as fp:
fp.write(html_source)
bro.quit()
注意:不能直接打开爬取出来的html文件,文件中存在js语句,阻止本地打开,渲染数据。
破解滑动验证码
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait # 等待元素加载的
from selenium.webdriver.common.action_chains import ActionChains #拖拽
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.common.by import By
from PIL import Image
import requests
import re
import random
from io import BytesIO
import time
def merge_image(image_file,location_list):
"""
拼接图片
"""
im = Image.open(image_file)
im.save('code.jpg')
new_im = Image.new('RGB',(260,116))
# 把无序的图片 切成52张小图片
im_list_upper = []
im_list_down = []
# print(location_list)
for location in location_list:
# print(location['y'])
if location['y'] == -58: # 上半边
im_list_upper.append(im.crop((abs(location['x']),58,abs(location['x'])+10,116)))
if location['y'] == 0: # 下半边
im_list_down.append(im.crop((abs(location['x']),0,abs(location['x'])+10,58)))
x_offset = 0
for im in im_list_upper:
new_im.paste(im,(x_offset,0)) # 把小图片放到 新的空白图片上
x_offset += im.size[0]
x_offset = 0
for im in im_list_down:
new_im.paste(im,(x_offset,58))
x_offset += im.size[0]
#new_im.show()
return new_im
def get_image(driver,div_path):
'''
下载无序的图片 然后进行拼接 获得完整的图片
:param driver:
:param div_path:
:return:
'''
background_images = driver.find_elements_by_xpath(div_path)
location_list = []
for background_image in background_images:
location = {}
result = re.findall('background-image: url\("(.*?)"\); background-position: (.*?)px (.*?)px;',background_image.get_attribute('style'))
# print(result)
location['x'] = int(result[0][1])
location['y'] = int(result[0][2])
image_url = result[0][0]
location_list.append(location)
image_url = image_url.replace('webp','jpg')
# '替换url http://static.geetest.com/pictures/gt/579066de6/579066de6.webp'
image_result = requests.get(image_url).content
image_file = BytesIO(image_result) # 是一张无序的图片
image = merge_image(image_file,location_list)
return image
def get_track(distance):
# 初速度
v=0
# 单位时间为0.2s来统计轨迹,轨迹即0.2内的位移
t=0.2
# 位移/轨迹列表,列表内的一个元素代表0.2s的位移
tracks=[]
tracks_back=[]
# 当前的位移
current=0
# 到达mid值开始减速
mid=distance * 7/8
print("distance",distance)
global random_int
random_int=8
distance += random_int # 先滑过一点,最后再反着滑动回来
while current < distance:
if current < mid:
# 加速度越小,单位时间的位移越小,模拟的轨迹就越多越详细
a = random.randint(2,5) # 加速运动
else:
a = -random.randint(2,5) # 减速运动
# 初速度
v0 = v
# 0.2秒时间内的位移
s = v0*t+0.5*a*(t**2)
# 当前的位置
current += s
# 添加到轨迹列表
if round(s)>0:
tracks.append(round(s))
else:
tracks_back.append(round(s))
# 速度已经达到v,该速度作为下次的初速度
v= v0+a*t
print("tracks:",tracks)
print("tracks_back:",tracks_back)
print("current:",current)
# 反着滑动到大概准确位置
tracks_back.append(distance-current)
tracks_back.extend([-2,-5,-8,])
return tracks,tracks_back
def get_distance(image1,image2):
'''
拿到滑动验证码需要移动的距离
:param image1:没有缺口的图片对象
:param image2:带缺口的图片对象
:return:需要移动的距离
'''
# print('size', image1.size)
threshold = 50
for i in range(0,image1.size[0]): # 260
for j in range(0,image1.size[1]): # 160
pixel1 = image1.getpixel((i,j))
pixel2 = image2.getpixel((i,j))
res_R = abs(pixel1[0]-pixel2[0]) # 计算RGB差
res_G = abs(pixel1[1] - pixel2[1]) # 计算RGB差
res_B = abs(pixel1[2] - pixel2[2]) # 计算RGB差
if res_R > threshold and res_G > threshold and res_B > threshold:
return i # 需要移动的距离
def main_check_code(driver,element):
"""
拖动识别验证码
:param driver:
:param element:
:return:
"""
login_btn = driver.find_element_by_class_name('js-login')
login_btn.click()
element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_guide_tip')))
slide_btn = driver.find_element_by_class_name('gt_guide_tip')
slide_btn.click()
image1 = get_image(driver, '//div[@class="gt_cut_bg gt_show"]/div')
image2 = get_image(driver, '//div[@class="gt_cut_fullbg gt_show"]/div')
# 图片上 缺口的位置的x坐标
# 2 对比两张图片的所有RBG像素点,得到不一样像素点的x值,即要移动的距离
l = get_distance(image1, image2)
print('l=',l)
# 3 获得移动轨迹
track_list = get_track(l)
print('第一步,点击滑动按钮')
element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'gt_slider_knob')))
ActionChains(driver).click_and_hold(on_element=element).perform() # 点击鼠标左键,按住不放
import time
time.sleep(0.4)
print('第二步,拖动元素')
for track in track_list[0]:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
#time.sleep(0.4)
for track in track_list[1]:
ActionChains(driver).move_by_offset(xoffset=track, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
time.sleep(0.1)
import time
time.sleep(0.6)
# ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
# ActionChains(driver).move_by_offset(xoffset=8, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
# ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform() # 鼠标移动到距离当前位置(x,y)
print('第三步,释放鼠标')
ActionChains(driver).release(on_element=element).perform()
time.sleep(1)
def main_check_slider(driver):
"""
检查滑动按钮是否加载
:param driver:
:return:
"""
while True:
try :
driver.get('https://www.huxiu.com/')
element = WebDriverWait(driver, 30, 0.5).until(EC.element_to_be_clickable((By.CLASS_NAME, 'js-login')))
if element:
return element
except TimeoutException as e:
print('超时错误,继续')
time.sleep(5)
if __name__ == '__main__':
try:
count = 3 # 最多识别3次
driver = webdriver.Chrome()
while count > 0:
# 等待滑动按钮加载完成
element = main_check_slider(driver)
main_check_code(driver,element)
try:
success_element = (By.CSS_SELECTOR, '.gt_success')
# 得到成功标志
success_images = WebDriverWait(driver,3).until(EC.presence_of_element_located(success_element))
if success_images:
print('成功识别!!!!!!')
count = 0
import sys
sys.exit()
except Exception as e:
print('识别错误,继续')
count -= 1
time.sleep(1)
else:
print('too many attempt check code ')
exit('退出程序')
finally:
driver.close()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











