







接下来我们来讲提取细节,首先加载库
from lxml import etree
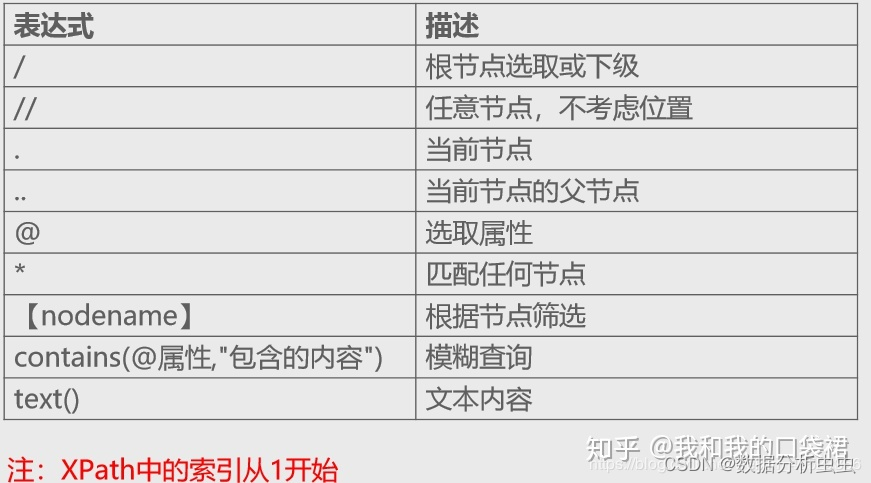
提取标签内容, /text()[0]或者/string()[0]
提取标签属性值, /@属性名
*表示任意节点
,@*表示任何属性,
node()表示任意节点
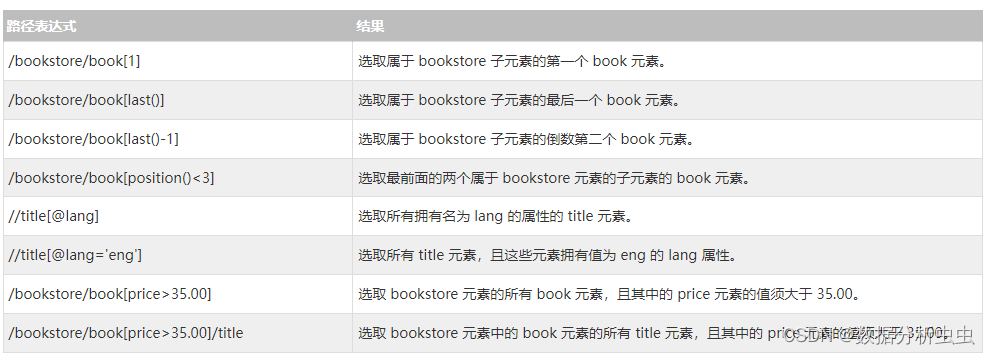
1. 解析html流程说明
url_02 = 'https://www.qdfd.com.cn/qdweb/realweb/fh/FhProjectInfo.jsp'
data_02 = {
'projectID': shuzi_01}
response_02 = requests.post(url_02, data=data_02,headers=header)
if response.status_code == 200:
response_02.encoding = 'GBK'
sleep(random.uniform(0.2, 0.3)) # 生成一个a到b的小数等待时间
# 请求是否成功
# print(response_02.status_code)
html_02 = etree.HTML(response_02.text)
# #/html/body/div[1]/div[2]/ul[2]/table[2]/tbody/tr[position()>1]/td[2]/a
shuzi_2 = html_02.xpath('/html/body/div[1]/div[2]/ul[2]//tr[position()>1]/td[2]/a')
a = '''<title>标题</title>
<body>
<ul class='list1'>
<li>列表1第1项</li>
<li>列表1第2项</li>
</ul>
<p class='first'>文字1</p>
<p class='second'>文字2</p>
<ul class='list2'>
<li>列表2第1项</li>
<li>列表2第2项</li>
</ul>
</body>'''
from lxml import etree
html = etree.HTML(a)
html.xpath('//title/text()')[0] # '标题'
html.xpath("//p[@class='first']//text()")[0] # '文字1'
html.xpath(</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3266
3266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











