







爬虫课程笔记
网址补全

贴吧案例
# -*- coding: utf-8 -*-
import scrapy
import urllib
import requests
class TbSpider(scrapy.Spider):
name = 'tb'
allowed_domains = ['tieba.baidu.com']
start_urls = ['http://tieba.baidu.com/mo/q----,sz@320_240-1-3---2/m?kw=%E6%9D%8E%E6%AF%85&lp=9001']
def parse(self, response):
#根据帖子进行分组
div_list = response.xpath("//div[contains(@class,'i')]")
for div in div_list:
item = {}
item["href"] = div.xpath("./a/@href").extract_first()
item["title"] = div.xpath("./a/text()").extract_first()
item["img_list"] = []
if item["href"] is not None:
item["href"] = urllib.parse.urljoin(response.url,item["href"])
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta = {"item":item}
)
#列表页的翻页
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse,
)
def parse_detail(self,response):
item = response.meta["item"]
# if "img_list" not in item:
# item["img_list"] = response.xpath("//img[@class='BDE_Image']/@src").extract()
# else:
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None: #表示由下一页
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse_detail,
meta={"item":item}
)
else:
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
print(item)
# yield item
HR使用crawlspider
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TtSpider(CrawlSpider):
name = 'tt'
allowed_domains = ['tencent.com']
start_urls = ['https://hr.tencent.com/position.php']
rules = (
Rule(LinkExtractor(allow=r'position_detail\.php\?id=\d+&keywords=&tid=0&lid=0'), callback='parse_item'),
Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'),follow=True),
)
def parse_item(self, response):
item = {}
item["title"] = response.xpath("//td[@id='sharetitle']/text()").extract_first()
item["aquire"] = response.xpath("//div[text()='工作要求:']/../ul/li/text()").extract()
# return i
print(item)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class Tt1Spider(CrawlSpider):
name = 'tt1'
allowed_domains = ['tencent.com']
start_urls = ['https://hr.tencent.com/position.php/']
rules = (
#提取翻页列表页的URL地址
Rule(LinkExtractor(allow=r'position\.php\?&start=\d+#a'), callback='parse_item', follow=True),
)
def parse_item(self, response):
tr_list = response.xpath("//table[@class='tablelist']/tr")[1:-1]
for tr in tr_list:
item = {}
item["title"] = tr.xpath("./td[1]/a/text()").extract_first()
item["href"] = "https://hr.tencent.com/"+tr.xpath("./td[1]/a/@href").extract_first()
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta = {"item":item}
)
def parse_detail(self,response):
item = response.meta["item"]
item["aquire"] = response.xpath("//div[text()='工作要求:']/../ul/li/text()").extract()
print(item)
Scrapy_redis
Github地址:https://github.com/rmax/scrapy-redis
Scrapy_redis在scrapy的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
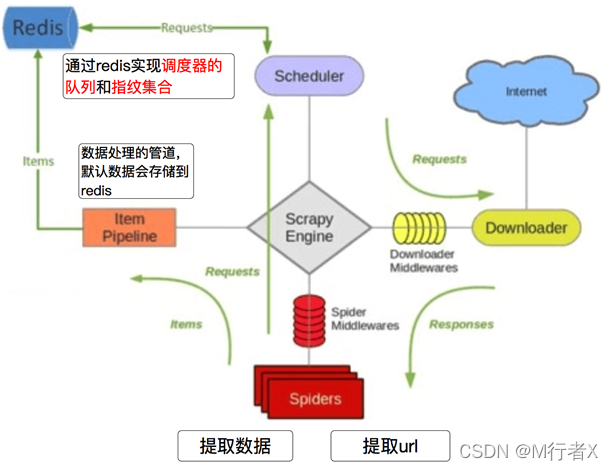
复习redis


使用Scrapy_redis
1、clone github scrapy-redis源码文件
git clone https://github.com/rolando/scrapy-redis.git
2、研究项目自带的三个demo
mv scrapy-redis/example-project ~/scrapyredis-project
DOMZ-demo



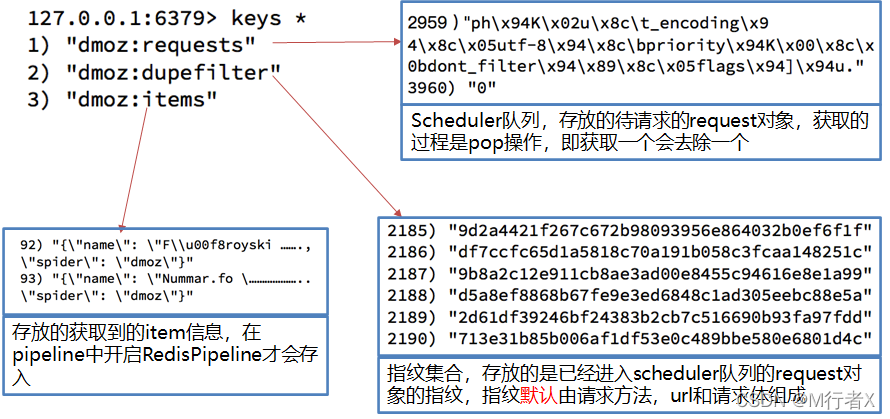
我们可以尝试在setting中关闭redispipeline,
观察redis中三个键的存储数据量的变化

以上的这些功能scrapy_redis都是如何实现的呢?
Scrapy_redis之RedisPipeline

Scrapy_redis之RFPDupeFilter

Scrapy_redis之Scheduler


抓取京东图书的信息
目标:抓取京东图书包含图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
url:https://book.jd.com/booksort.html
spider.py
# -*- coding: utf-8 -*-
import scrapy
from copy import deepcopy
import json
import urllib
class JdSpider(scrapy.Spider):
name = 'jd'
allowed_domains = ['jd.com','p.3.cn']
start_urls = ['https://book.jd.com/booksort.html']
def parse(self, response):
dt_list = response.xpath("//div[@class='mc']/dl/dt") #大分类列表
for dt in dt_list:
item = {}
item["b_cate"] = dt.xpath("./a/text()").extract_first()
em_list = dt.xpath("./following-sibling::dd[1]/em") #小分类列表
for em in em_list:
item["s_href"] = em.xpath("./a/@href").extract_first()
item["s_cate"] = em.xpath("./a/text()").extract_first()
if item["s_href"] is not None:
item["s_href"] = "https:" + item["s_href"]
yield scrapy.Request(
item["s_href"],
callback=self.parse_book_list,
meta = {"item":deepcopy(item)}
)
def parse_book_list(self,response): #解析列表页
item = response.meta["item"]
li_list = response.xpath("//div[@id='plist']/ul/li")
for li in li_list:
item["book_img"] = li.xpath(".//div[@class='p-img']//img/@src").extract_first()
if item["book_img"] is None:
item["book_img"] = li.xpath(".//div[@class='p-img']//img/@data-lazy-img").extract_first()
item["book_img"]="https:"+item["book_img"] if item["book_img"] is not None else None
item["book_name"] = li.xpath(".//div[@class='p-name']/a/em/text()").extract_first().strip()
item["book_author"] = li.xpath(".//span[@class='author_type_1']/a/text()").extract()
item["book_press"]= li.xpath(".//span[@class='p-bi-store']/a/@title").extract_first()
item["book_publish_date"] = li.xpath(".//span[@class='p-bi-date']/text()").extract_first().strip()
item["book_sku"] = li.xpath("./div/@data-sku").extract_first()
yield scrapy.Request(
"https://p.3.cn/prices/mgets?skuIds=J_{}".format(item["book_sku"]),
callback=self.parse_book_price,
meta = {"item":deepcopy(item)}
)
#列表页翻页
next_url = response.xpath("//a[@class='pn-next']/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse_book_list,
meta = {"item":item}
)
def parse_book_price(self,response):
item = response.meta["item"]
item["book_price"] = json.loads(response.body.decode())[0]["op"]
print(item)
middlewares.py
import random
class RandomUserAgentMiddleware:
def process_request(self,request,spider):
ua = random.choice(spider.settings.get("USER_AGENTS_LIST"))
request.headers["User-Agent"] = ua
class CheckUserAgent:
def process_response(self,request,response,spider):
# print(dir(response.request))
print(request.headers["User-Agent"])
return response
settings.py
BOT_NAME = 'book'
SPIDER_MODULES = ['book.spiders']
NEWSPIDER_MODULE = 'book.spiders'
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://127.0.0.1:6379"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
RedisSpider(分布式爬虫)


当当图书爬虫(案例)
需求:抓取当当图书的信息
目标:抓取当当图书又有图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
url:http://book.dangdang.com/
# -*- coding: utf-8 -*-
import scrapy
from scrapy_redis.spiders import RedisSpider
from copy import deepcopy
import urllib
class DangdangSpider(RedisSpider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
# start_urls = ['http://book.dangdang.com/']
redis_key = "dangdang"
def parse(self, response):
#大分类分组
div_list = response.xpath("//div[@class='con flq_body']/div")
for div in div_list:
item = {}
item["b_cate"] = div.xpath("./dl/dt//text()").extract()
item["b_cate"] = [i.strip() for i in item["b_cate"] if len(i.strip())>0]
#中间分类分组
dl_list = div.xpath("./div//dl[@class='inner_dl']")
for dl in dl_list:
item["m_cate"] = dl.xpath("./dt//text()").extract()
item["m_cate"] = [i.strip() for i in item["m_cate"] if len(i.strip())>0][0]
#小分类分组
a_list = dl.xpath("./dd/a")
for a in a_list:
item["s_href"] = a.xpath("./@href").extract_first()
item["s_cate"] = a.xpath("./text()").extract_first()
if item["s_href"] is not None:
yield scrapy.Request(
item["s_href"],
callback=self.parse_book_list,
meta = {"item":deepcopy(item)}
)
def parse_book_list(self,response):
item = response.meta["item"]
li_list = response.xpath("//ul[@class='bigimg']/li")
for li in li_list:
item["book_img"] = li.xpath("./a[@class='pic']/img/@src").extract_first()
if item["book_img"] == "images/model/guan/url_none.png":
item["book_img"] = li.xpath("./a[@class='pic']/img/@data-original").extract_first()
item["book_name"] = li.xpath("./p[@class='name']/a/@title").extract_first()
item["book_desc"] = li.xpath("./p[@class='detail']/text()").extract_first()
item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first()
item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/text()").extract()
item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first()
item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/text()").extract_first()
print(item)
#下一页
next_url = response.xpath("//li[@class='next']/a/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse_book_list,
meta = {"item":item}
)
settings.py
BOT_NAME = 'book'
SPIDER_MODULES = ['book.spiders']
NEWSPIDER_MODULE = 'book.spiders'
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
REDIS_URL = "redis://192.168.82.64:6379"
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
亚马逊图书(案例)
需求:抓取亚马逊图书的信息
目标:抓取亚马逊图书又有图书的名字、封面图片地址、图书url地址、作者、出版社、出版时间、价格、图书所属大分类、图书所属小的分类、分类的url地址
url:https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
import re
class AmazonSpider(RedisCrawlSpider):
name = 'amazon'
allowed_domains = ['amazon.cn']
# start_urls = ['https://www.amazon.cn/%E5%9B%BE%E4%B9%A6/b/ref=sd_allcat_books_l1?ie=UTF8&node=658390051']
redis_key = "amazon"
rules = (
#匹配大分类的url地址和小分类的url
Rule(LinkExtractor(restrict_xpaths=("//div[@class='categoryRefinementsSection']/ul/li",)), follow=True),
#匹配图书的url地址
Rule(LinkExtractor(restrict_xpaths=("//div[@id='mainResults']/ul/li//h2/..",)),callback="parse_book_detail"),
#列表页翻页
Rule(LinkExtractor(restrict_xpaths=("//div[@id='pagn']",)),follow=True),
)
def parse_book_detail(self,response):
# with open(response.url.split("/")[-1]+".html","w",encoding="utf-8") as f:
# f.write(response.body.decode())
item = {}
item["book_title"] = response.xpath("//span[@id='productTitle']/text()").extract_first()
item["book_publish_date"] = response.xpath("//h1[@id='title']/span[last()]/text()").extract_first()
item["book_author"] = response.xpath("//div[@id='byline']/span/a/text()").extract()
# item["book_img"] = response.xpath("//div[@id='img-canvas']/img/@src").extract_first()
item["book_price"] = response.xpath("//div[@id='soldByThirdParty']/span[2]/text()").extract_first()
item["book_cate"] = response.xpath("//div[@id='wayfinding-breadcrumbs_feature_div']/ul/li[not(@class)]/span/a/text()").extract()
item["book_cate"] = [i.strip() for i in item["book_cate"]]
item["book_url"] = response.url
item["book_press"] = response.xpath("//b[text()='出版社:']/../text()").extract_first()
# item["book_desc"] = re.findall(r'<noscript>.*?<div>(.*?)</div>.*?</noscript>',response.body.decode(),re.S)
# item["book_desc"] = response.xpath("//noscript/div/text()").extract()
# item["book_desc"] = [i.strip() for i in item["book_desc"] if len(i.strip())>0 and i!='海报:']
# item["book_desc"] = item["book_desc"][0].split("<br>",1)[0] if len(item["book_desc"])>0 else None
print(item)
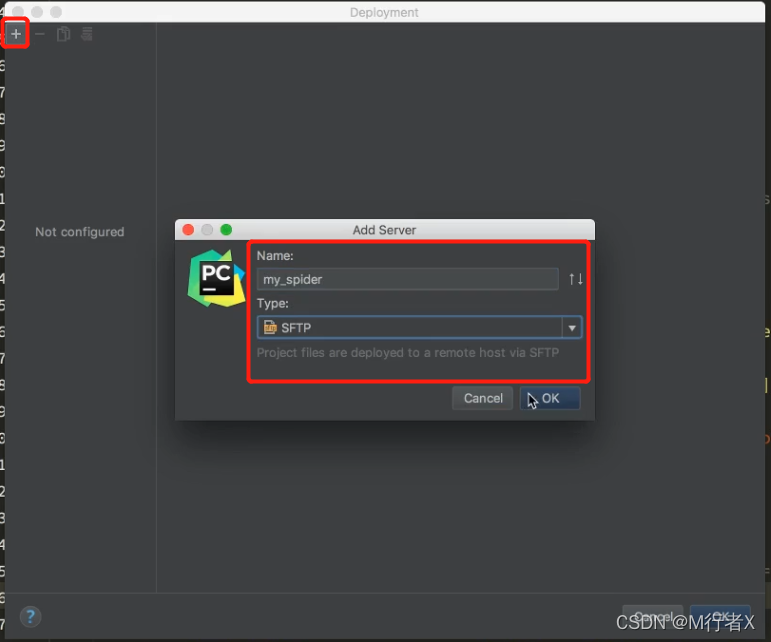
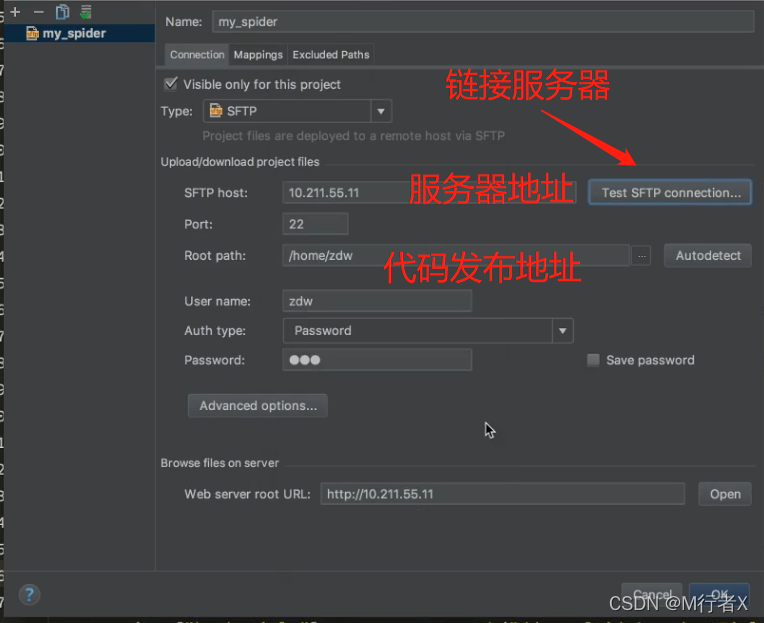
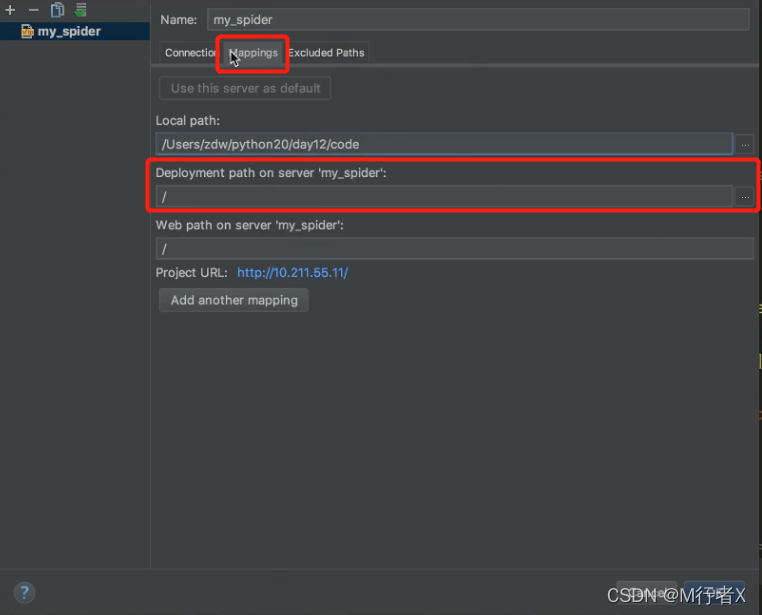
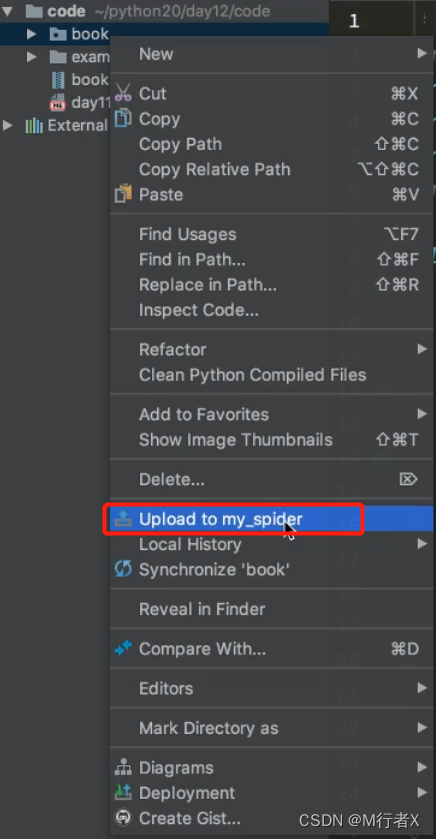
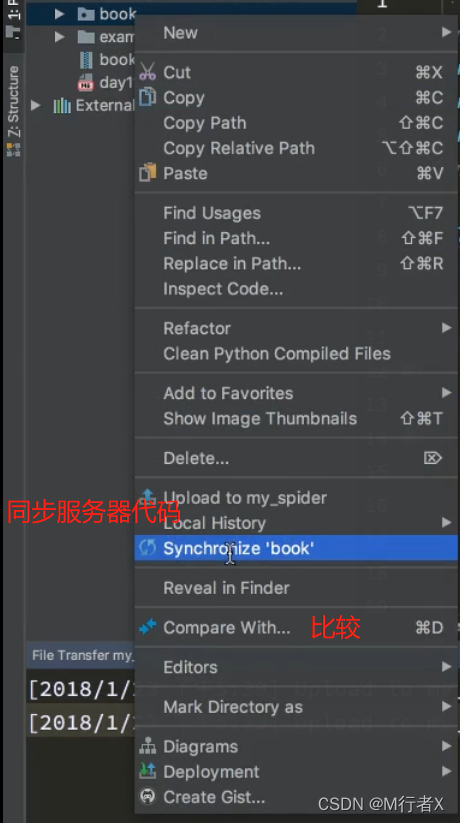
Pycharm 发布代码

Crontab爬虫定时执行


重点
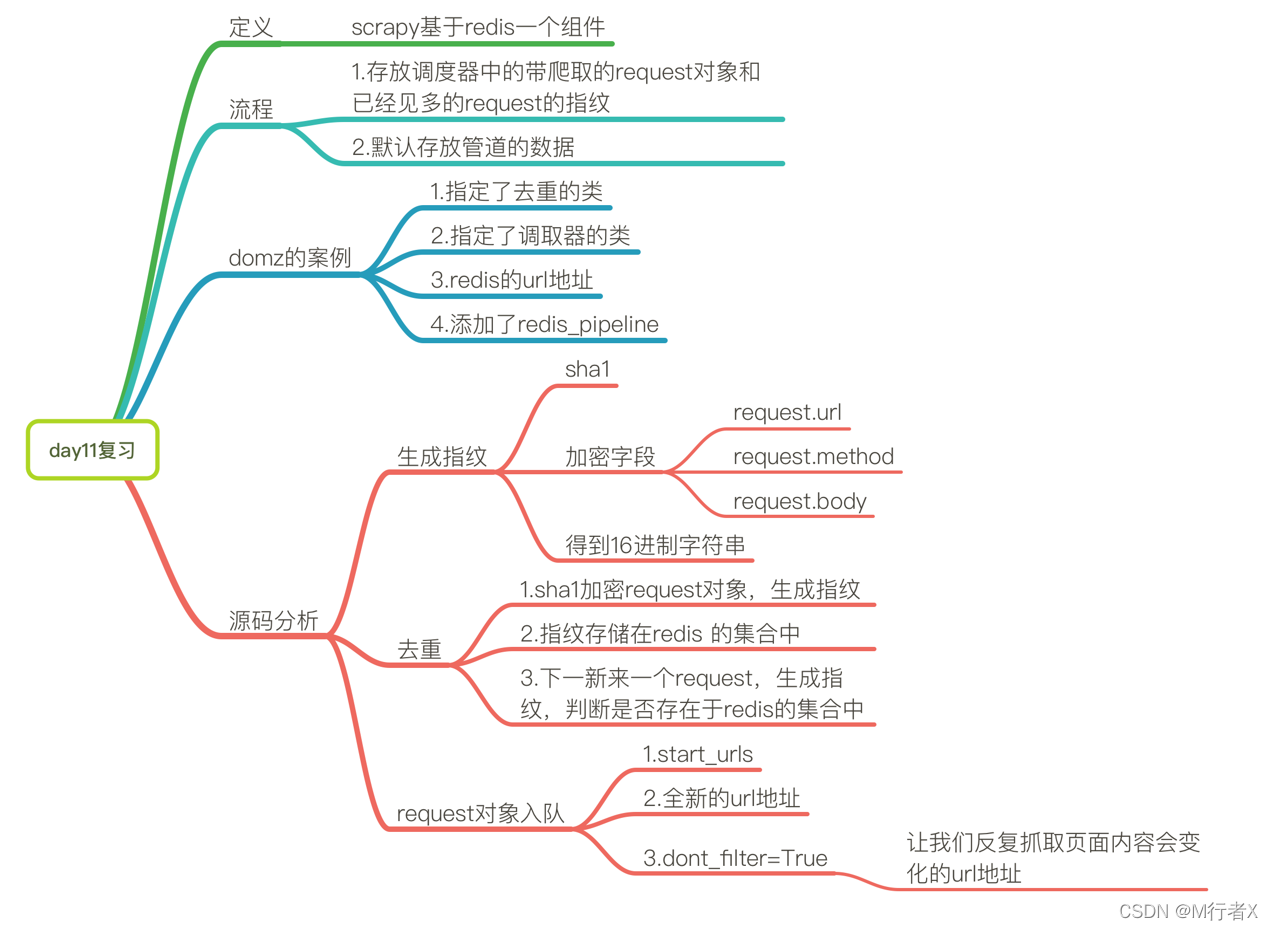
### request对象什么时候入队
- dont_filter = True ,构造请求的时 候,把dont_filter置为True,该url会被反复抓取(url地址对应的内容会更新的情况)
- 一个全新的url地址被抓到的时候,构造request请求
- url地址在start_urls中的时候,会入队,不管之前是否请求过
- 构造start_url地址的请求时候,dont_filter = True
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request指纹已经存在 #不会入队
# dont_filter=False Ture False request指纹已经存在 全新的url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
self.queue.push(request) #入队
return True
### scrapy_redis去重方法
- 使用sha1加密request得到指纹
- 把指纹存在redis的集合中
- 下一次新来一个request,同样的方式生成指纹,判断指纹是否存在reids的集合中
### 生成指纹
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #url
fp.update(request.body or b'') #请求体
return fp.hexdigest()
### 判断数据是否存在redis的集合中,不存在插入
added = self.server.sadd(self.key, fp)
return added != 0
### 爬虫项目
- 项目名字
- request+selenium爬虫
- 项目周期
- 项目介绍
- 爬了XXXXX,XXX,XXX,等网站,获取网站上的XXX,XXX,XXX,数据,每个月定时抓取XXX数据,使用该数据实现了XXX,XXX,XX,
- 开发环境
- linux+pycharm+requests+mongodb+redis+crontab+scrapy_redis+ scarpy + mysql+gevent+celery+threading
- 使用技术
- 使用requests...把数据存储在mongodb中
- 使用crontab实现程序的定时启动抓取
- url地址的去重
- 使用redis的集合,把request对象的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现基于url地址的增量式爬虫
- 布隆过滤
- 对数据的去重
- 把数据的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现增量式爬虫
- 反扒
- 代理ip
- 购买了第三的代理ip,组成代理ip池,其中的ip没两天更新一次,同时使用单独的程序来检查代理ip的可用
- cookie
- 准备了XX个账号,使用requests获取账号的对应的cookie,存储在redis中,后续发送请求的时候随机选择cookie
- 使用selenium来进行模拟登陆,获取cookie,保存在Redis中
- 数据通过js生成
- 分析js,通过chrome浏览器定位js的位置,寻找js生成数据的方式
- 通过selenium来模拟页面的加载内容,获取页面动态加载后的数据
- 提高爬虫效率
- 使用多线,线程池,协程,celery来完成爬虫
- 使用scrapy框架来实现爬虫,
- 不能断点续爬,请求过的url地址不能持久化
- 使用scrapy_redis
- 不能对数据进行去重
- 把数据的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现增量式爬虫
- scrapy_redis
- domz实现增量式,持久化的爬虫
- 实现分布式爬虫
- 项目名字
- scarpy爬虫
- 项目周期
- 项目介绍
- 爬了XXXXX,XXX,XXX,等网站,获取网站上的XXX,XXX,XXX,数据,每个月定时抓取XXX数据,使用该数据实现了XXX,XXX,XX,
- 开发环境
- linux+pycharm+requests+mongodb+redis+crontab+scrapy_redis+ scarpy + mysql+gevent+celery+threading
- 使用技术
- 使用requests...把数据存储在mongodb中
- 使用crontab实现程序的定时启动抓取
- url地址的去重
- 使用redis的集合,把request对象的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现基于url地址的增量式爬虫
- 布隆过滤
- 对数据的去重
- 把数据的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现增量式爬虫
- 反扒
- 代理ip
- 购买了第三的代理ip,组成代理ip池,其中的ip没两天更新一次,同时使用单独的程序来检查代理ip的可用
- cookie
- 准备了XX个账号,使用requests获取账号的对应的cookie,存储在redis中,后续发送请求的时候随机选择cookie
- 使用selenium来进行模拟登陆,获取cookie,保存在Redis中
- 数据通过js生成
- 分析js,通过chrome浏览器定位js的位置,寻找js生成数据的方式
- 通过selenium来模拟页面的加载内容,获取页面动态加载后的数据
- 提高爬虫效率
- 使用多线,线程池,协程,celery来完成爬虫
- 使用scrapy框架来实现爬虫,
- 不能断点续爬,请求过的url地址不能持久化
- 使用scrapy_redis
- 不能对数据进行去重
- 把数据的XXX字段通过sha1生成指纹,放入redis的集合中进行去重,实现增量式爬虫
- scrapy_redis
- domz实现增量式,持久化的爬虫
- 实现分布式爬虫














 1714
1714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









