







Epoll性能特点
对Select、Poll、Epoll、Kqueue几种I/O多路复用做测试(限制100个活动连接,并且每一个连接会有1000次写入)
下图是 libevent(一个知名的异步事件处理软件库)对这几个 I/O 多路复用技术做的性能测试。
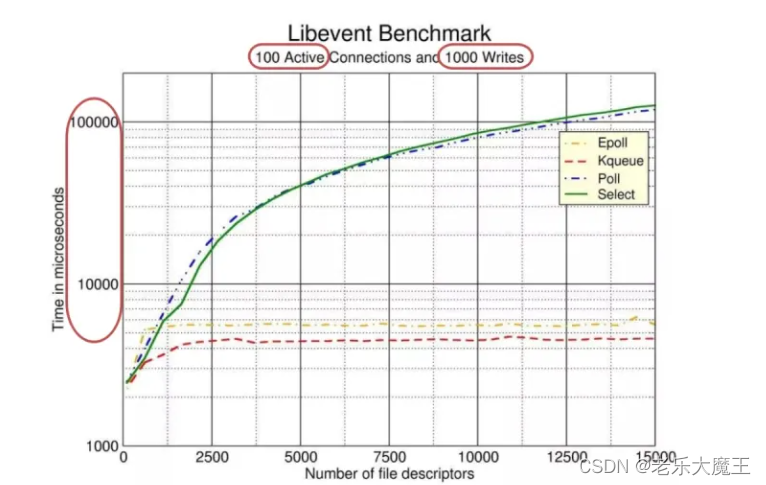
实验结果
在fd数量<1000时,这几种I/O复用的性能相互接近,当随着fd的数量越来越多,EPOLL和Kqueue的相应时间相接近,并且远小Select和Poll的响应时间
实验分析
通过实验结果,可以看出Epoll在面对大量连接时性能表现优异。
但是,不是任何时候,Epoll面对大量连接时都能够有如此表现,上述实验有个很重要的限制条件,100 Active Connections,也就是说,假设Epoll应对大量fd(15000个),此时其中只有100个活跃连接,Epoll才会明显优于其他I/O复用。
如果当活跃连接也为15000个时,Epoll将会和Select以及Poll性能相近。
在谈Epoll原理之前,先看几个问题(无需知道为什么),并且通过下面的原理解读来理解这些问题
Q: 为什么会出现I/O多路复用?
A: 为了减少进程上下文切换带来的开销。
Q: 是Linux已发行就有Epoll了吗?
A:
I/O多路复用是一种技术,而Select、Poll、Epoll是实现了该技术的框架。
框架的api发布的时间线:
- 1983,socket 发布在 Unix(4.2 BSD)
- 1983,select 发布在 Unix(4.2 BSD)
- 1994,Linux的1.0,已经支持socket和select
- 1997,poll 发布在 Linux 2.1.23
- 2002,epoll发布在 Linux 2.5.44
这些框架的出现是以不断改进的方式向前推进的:Select->Poll->Epoll,Poll是在Select的基础上改进,Epoll在Poll的基础上改进,可以这么说,Epoll是在I/O多路复用框架不断发展的结果。
Q: Epoll解决了什么问题?
A: Epoll优化了内核和监视进程(监视fd的进程)的交互。
1 Epoll原理
1.1 阻塞
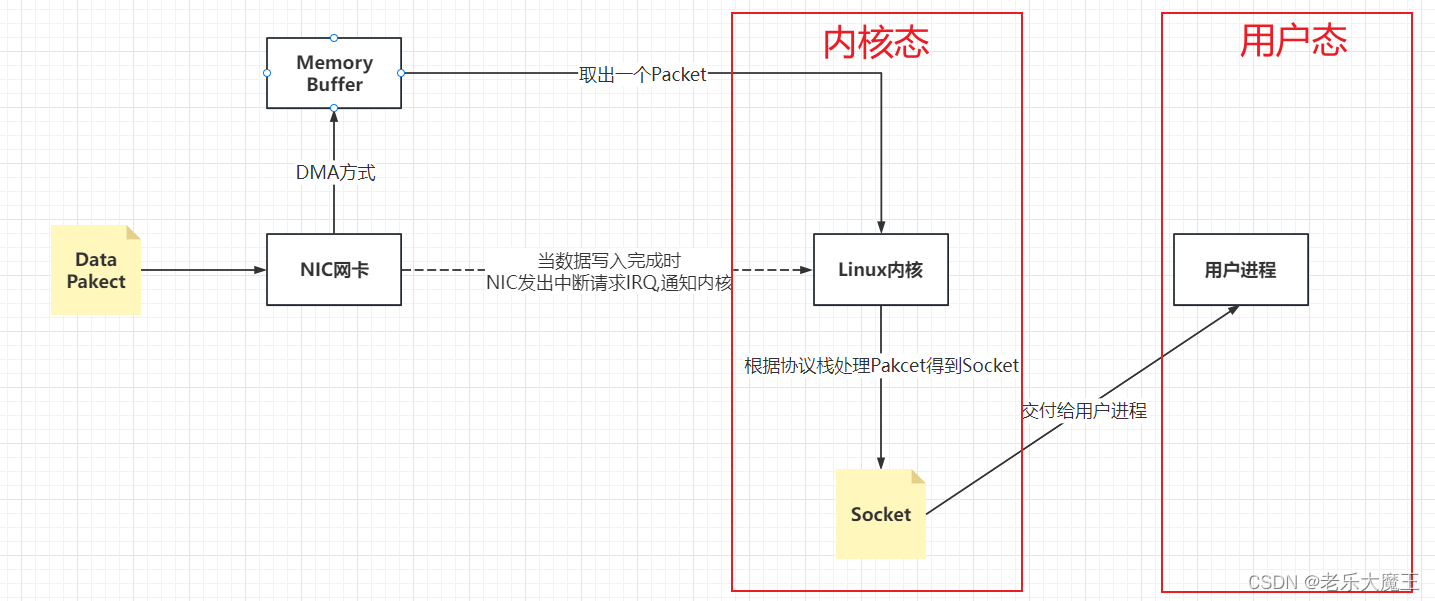
Epoll为什么是阻塞的,这是因为内核收发网络数据的底层机制导致的,并且,阻塞才是高效的方式。
接收网络数据的过程:














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









