






实验目的:
将给定训练集文章分成单个单词并统计,之后采用朴素贝叶斯分类器,对新闻文本实现文本分类,并统计正确率
实验原理:
将文章属于某一类别作为假设h,该文章出现的所有单词作为数据D
基于贝叶斯公式可以推导得

可以认为文章类别仅与各单词出现频率有关,而与出现位置无关,即
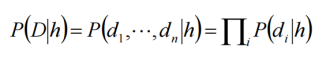
实际计算时,考虑到测试文章中有单词在训练集中未出现,故作近似处理
即对应单词在测试集中的数目均加一

实验设计:
在预先设定好各类型名称的前提下,进入各训练、测试目录提取新闻文本内的单词,并进行统计、储存,最后带入公式计算,并得出准确率。
程序说明:
训练与测试结果会储存在result.txt中,测试完毕后会有提示是否输出训练集中单词,此时若继续程序,则将会将各类别中单词及其出现次数输出到words.txt中
运行环境:
C++11, g++ (x86_64-posix-seh-rev0, Built by MinGW-W64 project) 8.1.0
#include <iostream>
#include <iomanip>
#include <cmath>
#include <cstring>
#include <fstream>
#include <io.h>
#include <vector>
#include <thread>
using namespace std;
typedef unsigned long long ull;
typedef vector<string> v_str;
class words_list; // 储存单词内容及出现频率的链表
ofstream &operator<<(ofstream &os, words_list &list_ptr); // 输出链表内容
v_str *list_all_files(string pathName); // 返回指定目录内所有文件或文件夹名
inline void add_words(string &file_content, words_list &list); // 将文章中的单词数量计入指定words_list
inline bool cnt_process(string compath, words_list &list); // 将文件的内容全部加入指定链表计数
void train(words_list *arg_list, int *arg_train_text);
void train_start(int thr_num, words_list *lists, int *train_text);
void test(words_list *lists, int *train_text, ull *corr_num, ull *wron_num, int i);
void test_start(words_list *lists, int *train_text, ull *corr_num, ull *wron_num, int thr_num);
class words_list
{ // 储存单词内容及出现频率的链表
public:
string word; // 单词内容,头结点表示类别名
ull count; // 出现次数,头结点表示单词出现总数
words_list *next; // 下一单词的指针
words_list()
{
count = 0;
next = NULL;
}
void insert(string new_word); // 增加某个单词出现次数
ull search(string target_word); // 返回某个单词出现次数
ull clean(); // 清理无关单词,返回数目
};
string train_path;
string test_path;
int cata_size = 0; // 类别数目
int train_text_total = 0; // 已训练文章的总数
ull total_words = 0; // 已训练文章单词总数
ull total_vocab = 0; // 已训练文章单词种类数
ull corr_num_total = 0; // 测试正确总数
ull wron_num_total = 0; // 测试错误总数
words_list all_vocab; // 储存所有训练单词的链表
int main(int argc, char **argv)
{
string argv_str = argv[0]; // 得到运行目录
argv_str.erase(argv_str.rfind('\\')); // 移除文件名部分
train_path = argv_str + "\\20news-bydate-train"; // 训练数据目录
test_path = argv_str + "\\20news-bydate-test"; // 测试数据目录
ofstream file_out;
file_out.open("result.txt"); // 存放训练与测试结果
v_str *catagories = list_all_files(train_path); // 根据文件夹名得到各种类别名称
cata_size = catagories->size(); // 类别数目
words_list lists[cata_size]; // 建立各类别储存单词数链表的头结点
int train_text[cata_size] = {0}; // 各类别下已训练文章的数目
cout.setf(ios::left | ios::fixed);
file_out.setf(ios::left | ios::fixed);
cout.precision(2);
file_out.precision(2);
cout << "--------------------" << endl
<< "Total number of catagories: " << cata_size << endl
<< "--------------------" << endl;
file_out << "--------------------" << endl
<< "Total number of catagories: " << cata_size << endl
<< "--------------------" << endl;
for (int i = 0; i < cata_size; i++)
{
lists[i].word = catagories->at(i); // 将类别名赋给链表
cout << lists[i].word << endl; // 根据训练样本目录名输出类别名
}
cout << "--------------------\n"
<< endl;
// system("pause");
// 开始训练
cout << "--------------------" << endl
<< "Training begins:" << endl
<< "--------------------" << endl
<< setw(30) << "Catagory"
<< setw(10) << "Texts"
<< setw(10) << "Words" << endl;
file_out << setw(30) << "Catagory"
<< setw(10) << "Texts"
<< setw(10) << "Words" << endl;
train_start(cata_size, lists, train_text); // 多线程训练
words_list *count_ptr = all_vocab.next;
while (count_ptr != NULL) // 计算测试集所有类别单词种类数
{
total_vocab++;
count_ptr = count_ptr->next;
}
for (int i = 0; i < cata_size; i++) // 遍历类别
{
cout << setw(30) << lists[i].word
<< setw(10) << train_text[i]
<< setw(10) << lists[i].count << endl;
file_out << setw(30) << lists[i].word
<< setw(10) << train_text[i]
<< setw(10) << lists[i].count << endl;
}
cout << "--------------------" << endl
<< "Total texts:" << train_text_total << endl
<< "Total words: " << total_words << endl
<< "Training completed.\n\n";
file_out << "Total texts:" << total_words << endl
<< "Total words: " << train_text_total << endl
<< "--------------------" << endl;
// system("pause");
// 开始测试
cout << "--------------------" << endl
<< "Testing begins:" << endl
<< "--------------------" << endl;
ull corr_num[cata_size] = {0}; // 各类别正确数
ull wron_num[cata_size] = {0}; // 各类别错误数
test_start(lists, train_text, corr_num, wron_num, cata_size);
// 多线程测试
for (int i = 0; i < cata_size; i++) // 遍历类别输出结果
{
cout << setw(30) << lists[i].word
<< corr_num[i] + wron_num[i] << endl;
file_out << setw(30) << lists[i].word
<< corr_num[i] + wron_num[i] << endl;
}
cout << "--------------------" << endl
<< "Testing completed.\n"
<< "--------------------" << endl
<< endl
<< "Result:\n"
<< "Overall accuracy: "
<< corr_num_total << "/" << corr_num_total + wron_num_total << " "
<< 100.0l * corr_num_total / (corr_num_total + wron_num_total) << "\%\n";
file_out << "Overall accuracy: "
<< corr_num_total << "/" << corr_num_total + wron_num_total << " "
<< 100.0l * corr_num_total / (corr_num_total + wron_num_total) << "\%\n";
for (int i = 0; i < cata_size; i++)
{
cout << setw(30) << catagories->at(i)
<< corr_num[i] << "/" << (corr_num[i] + wron_num[i]) << " "
<< 100.0l * corr_num[i] / (corr_num[i] + wron_num[i]) << "\%\n";
file_out << setw(30) << catagories->at(i)
<< corr_num[i] << "/" << (corr_num[i] + wron_num[i]) << " "
<< 100.0l * corr_num[i] / (corr_num[i] + wron_num[i]) << "\%\n";
}
cout << "--------------------" << endl;
file_out << "--------------------" << endl;
file_out.close(); // 主体输出结束
cout << "Continue to output training words information?\n";
system("pause");
ofstream words_out; // 输出各类别下词汇出现频率
words_out.open("words.txt");
words_out << "--------------------" << endl
<< "Training words frequency:" << endl;
for (int i = 0; i < cata_size; i++)
{
words_out << catagories->at(i) << ":\n";
words_out << lists[i];
}
words_out.close();
system("pause");
return 0;
}
void words_list::insert(string new_word)
{ // 增加某个单词出现次数
if (new_word == "")
return;
words_list *ptr = this;
while (ptr->next != NULL)
{
if ((ptr->next->word).compare(new_word) == 0)
{
// 找到单词
(ptr->next->count)++; // 单词数增加
(this->count)++; // 单词总数增加
return;
}
ptr = ptr->next; // 继续下一个判断
}
ptr->next = new words_list; // 未找到,是新单词
ptr = ptr->next;
ptr->word = new_word;
(ptr->count)++;
(this->count)++;
return;
}
ull words_list::search(string target_word)
{ // 返回某个单词出现次数
if (target_word == "")
return 0;
words_list *ptr = this->next;
while (ptr != NULL)
{
if ((ptr->word).compare(target_word) == 0) // 找到单词
return ptr->count;
ptr = ptr->next; // 继续下一个判断
}
return 0;
}
ull words_list::clean()
{ // 清理无关单词,返回数目
return 0;
// 请注意:
// 经测试,该函数清理掉出现此处过少的单词后,准确率有所下降
words_list *ptr = this;
ull clean_count = 0;
while (ptr->next != NULL)
{
if (ptr->next->count < 2)
{
words_list *temp_word = ptr->next;
ptr->next = temp_word->next;
delete temp_word;
clean_count++;
}
else
ptr = ptr->next;
}
this->count -= clean_count;
return clean_count;
}
ofstream &operator<<(ofstream &os, words_list &list_ptr)
{ // 输出链表内容
words_list *ptr = list_ptr.next;
while (ptr != NULL)
{
os << "\t\"" << ptr->word << "\": " << ptr->count << endl;
ptr = ptr->next;
}
return os;
}
v_str *list_all_files(string pathName)
{ // 根据给定路径,返回目录内包含所有文件名或文件夹名容器的指针
v_str *file_names = new v_str;
intptr_t hFile = 0; // 文件句柄
_finddata_t fileInfo; // 文件信息
pathName.append("\\*"); // 表示列举所有文件
hFile = _findfirst(pathName.c_str(), &fileInfo);
// 获得第一个文件的句柄
if (hFile == -1)
// 数据应存放于源程序目录下,且对应目录不为空,否则报错
{
cout << "\nCan not find files or folders.\n";
system("pause");
exit(-1);
return NULL;
}
do
{
string temp_name = fileInfo.name;
if (temp_name == "." || temp_name == "..")
continue;
// 不知道是什么原因会出现“.”和“..”两项,打个补丁
file_names->push_back(temp_name); // 查找到后加入到容器
} while (_findnext(hFile, &fileInfo) == 0);
_findclose(hFile); // 结束查找,释放文件占用
return file_names;
}
inline void add_words(string &file_content, words_list &list)
{ // 将文章中的单词数量计入指定word_list
string intrvl("`~!@#$%^&*()_+-/*=,./<>?;':\"[]{}\\|\n\r\t");
// 需要替换的各类间隔符
for (ull i = 0; file_content[i]; i++)
if (intrvl.find(file_content[i]) != intrvl.npos)
file_content[i] = ' '; // 替换为空格
else if (file_content[i] <= 'Z' && file_content[i] >= 'A')
file_content[i] += 32; // 字母应全部小写
ull loc = file_content.find(' ');
// 指向第一个空格位置
while (loc != file_content.npos)
{
if (loc == 0)
{
// 空格位于开头的情况
file_content.erase(0, 1);
loc = file_content.find(' ');
continue;
}
string temp_word = file_content.substr(0, loc);
list.insert(temp_word); // 加入指定类别链表
all_vocab.insert(temp_word); // 加入总链表
file_content.erase(0, loc + 1); // 计数后连带空格擦除
loc = file_content.find(' '); // 开始下一次查找
}
list.insert(file_content); // 加入最后剩下的一个
}
inline bool cnt_process(string compath, words_list &list)
{ // 将文件的内容全部加入指定链表计数
ifstream file(compath.c_str()); // 打开文件
if (file.bad())
{
cout << "Failed to read file: " << compath << endl;
return false;
}
char cnt[1000000] = {0}; // 文件内容
file.read(cnt, 1000000); // 读入文件
cnt[file.gcount()] = 0;
string cnt_str(cnt); // 将文件内容转化为string型
add_words(cnt_str, list);
file.close();
return true;
}
void train(words_list *arg_list, int *arg_train_text)
{
words_list &list = *arg_list;
int &train_text = *arg_train_text;
string path = train_path + '\\' + list.word; // 文件夹完整路径
v_str *files = list_all_files(path); // 文件夹中的所有文件名
for (int j = 0; j < files->size(); j++)
{
string compath = path + "\\" + files->at(j); // 文件完整路径
if (cnt_process(compath, list))
train_text++; // 成功则计数
}
train_text_total += train_text;
delete files; // 减少不必要内存占用
list.clean();
total_words += list.count;
return;
}
void train_start(int thr_num, words_list *lists, int *train_text)
{
thread th(train, &lists[thr_num - 1], &train_text[thr_num - 1]);
if (thr_num > 1)
train_start(thr_num - 1, lists, train_text);
th.join();
return;
}
void test(words_list *lists, int *train_text, ull *corr_num, ull *wron_num, int i)
{
string path = test_path + '\\' + lists[i].word; // 文件夹完整路径
v_str *files = list_all_files(path); // 文件夹中的所有文件名
for (int j = 0; j < files->size(); j++) // 文件的遍历
{
string compath = path + "\\" + files->at(j); // 文件完整路径
words_list temp_list; // 关于本篇文章的链表
cnt_process(compath, temp_list); // 内容统计
temp_list.clean();
// 以下概率均进行对数化处理
long double log_P_h_D[cata_size]; // 各类别概率
int argmax_k = 0; // 最可能的类别
for (int k = 0; k < cata_size; k++) // 各类别的遍历
{
// long double log_P_h = logl(1.0l * train_text[k] / train_text_total); // 某类型文章所占比例
long double log_P_h = logl(1.0l * lists[k].count / total_words); // 某类型文章所占比例
long double log_P_D_h = 0;
words_list *ptr = temp_list.next;
while (ptr != NULL) // 遍历文章中单词
{
long double log_P_di_h = logl(lists[k].search(ptr->word) + 1) - logl(lists[k].count + total_vocab);
log_P_D_h += log_P_di_h * ptr->count; // 考虑单词数
ptr = ptr->next; // 继续下一个判断
}
log_P_h_D[k] = log_P_h + log_P_D_h; // 该文章属于某类别的概率
if (log_P_h_D[k] > log_P_h_D[argmax_k])
argmax_k = k; // 更大的类别
}
if (argmax_k == i) // 识别正确
{
corr_num[i]++;
corr_num_total++;
}
else // 识别错误
{
wron_num[i]++;
wron_num_total++;
}
}
delete files; // 减少不必要内存占用
}
void test_start(words_list *lists, int *train_text, ull *corr_num, ull *wron_num, int thr_num)
{
thread th(test, lists, train_text, corr_num, wron_num, thr_num - 1);
if (thr_num > 1)
test_start(lists, train_text, corr_num, wron_num, thr_num - 1);
th.join();
return;
}
















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









