







我们的分析过程基于之前章节搭建的es集群为基础。
一、分片
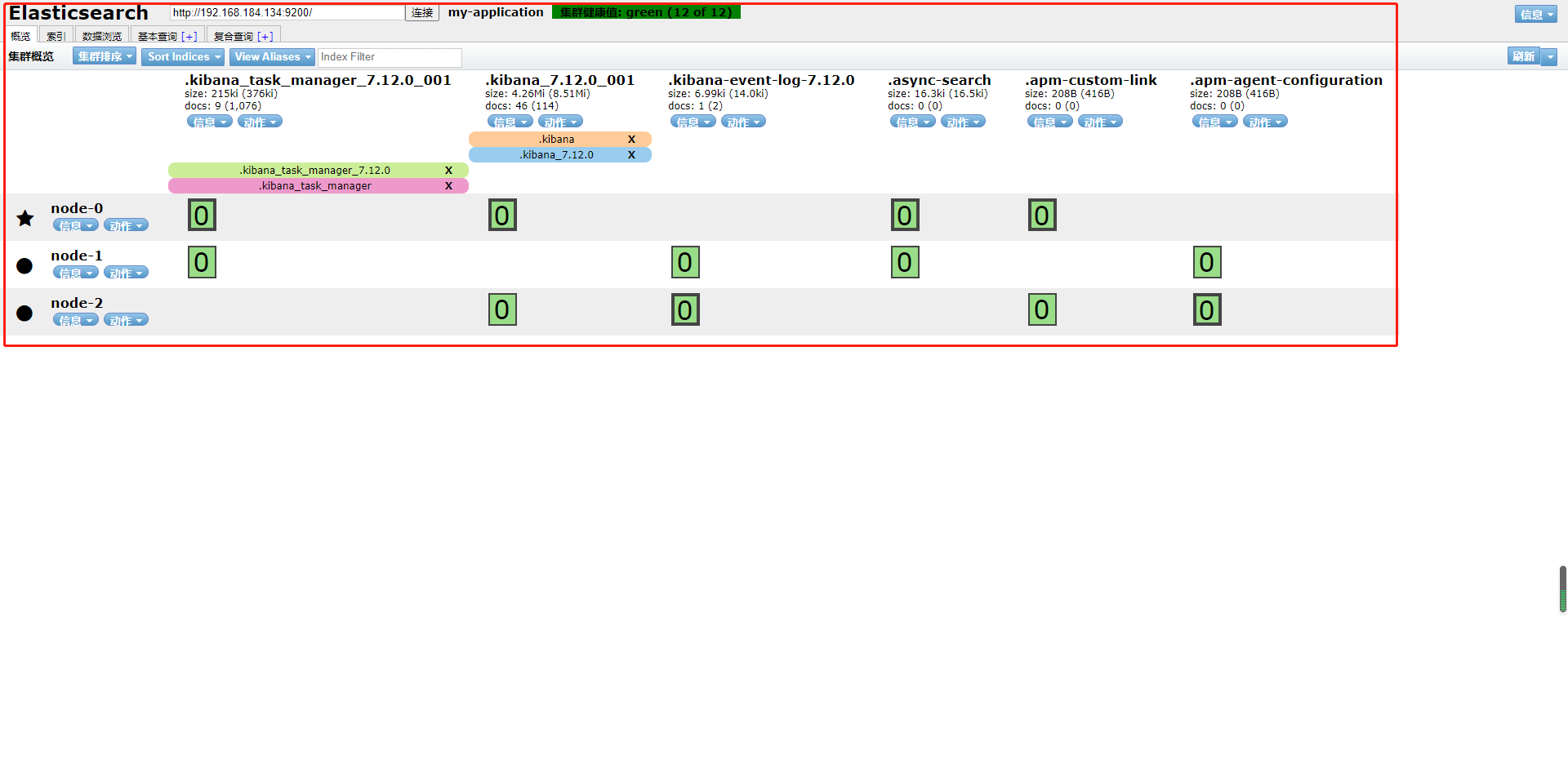
什么是分片?
分片的存在是为了解决单个索引大量文档的存储问题、以及搜索响应慢等问题。从而将一个索引划分成了多份,每一份就称之为分片。每个分片也是一个功能完善的“索引”,这个“索引”可以被放置到集群的任意节点上。
分片存在的重要原因有以下两个:
1)允许水平分扩展容量。
2)允许在分片之上进行分布式的,并行的操作,从而提高其吞吐量。
上面所说的分片其实指的是lucene的索引,一个分片就是一个lucene索引。一个elasticsearch索引就是一个lucene索引的集合。当进行查询时,会将查询请求发送到每一个属于当前elasticsearch索引的分片上,然后将每个分片得到的结果进行合并返回。
测试:
首先我们通过建立索引的方式来看下什么是分片,会产生哪些变化。
我们首先创建一个名为test的索引,让它有一个分片,我们看看结果,在kibana执行以下命令:
PUT /test/
{
"settings":{
"index":{
"number_of_shards" : "1",
"number_of_replicas" : "0"
}
}
}
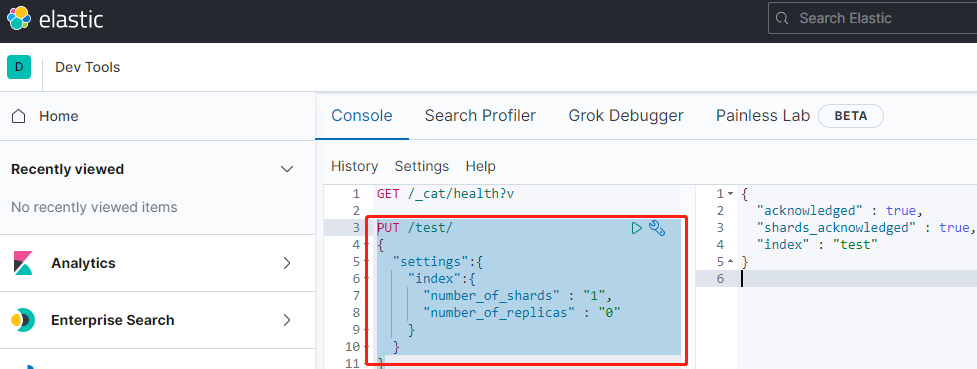
head中查看结果,我们看到test只在node-2节点上:
我们再次创建两个分片的test1:
PUT /test1/
{
"settings":{
"index":{
"number_of_shards" : "2",
"number_of_replicas" : "0"
}
}
}
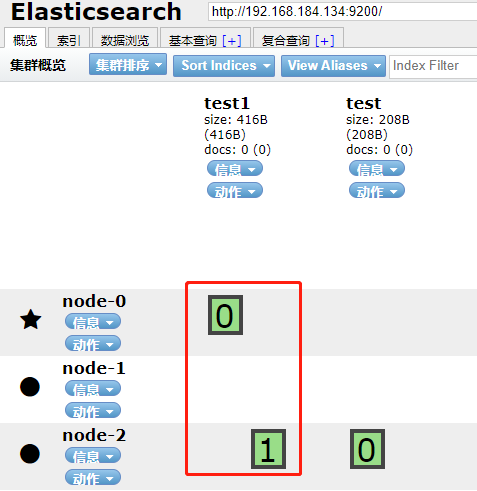
如上图看到分片分别分布在两个节点上,不用想,如果是3个那么肯定均匀分布在三个节点上。
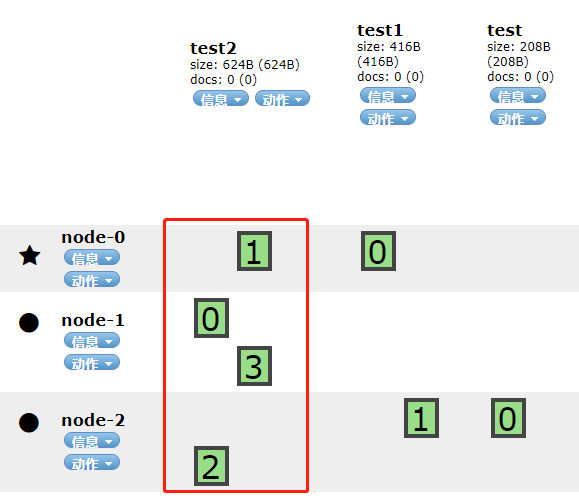
如果是4个会是什么样呢?其中一个节点会被分配2个分片,如下所示:
二、副本
什么是副本?
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
副本存在的两个重要原因:
1)提高可用性:注意的是副本不能与主/原分片位于同一节点。
2)提高吞吐量:搜索操作可以在所有的副本上并行运行。
测试:
创建一个含有一个分片,三个副本的test3:
PUT /test3/
{
"settings":{
"index":{
"number_of_shards" : "1",
"number_of_replicas" : "2"
}
}
}
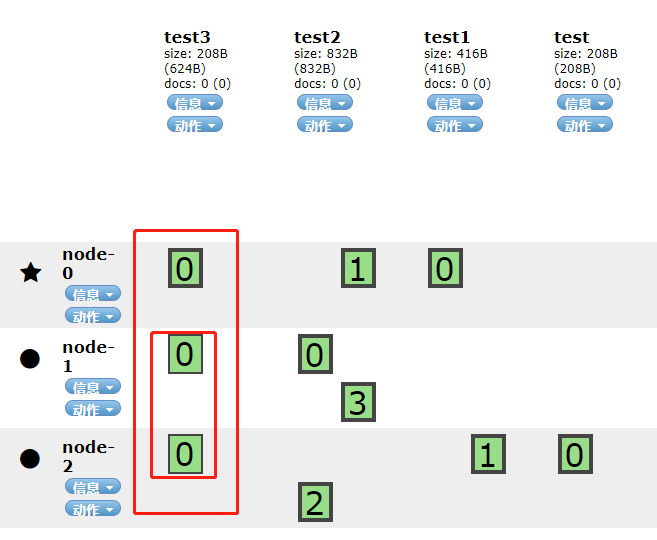
如上图所示,我们看到了3个绿色的0,其中在node-0节点的边框是粗体的,这个表示分片,而另外两个节点的0的边框是细体的,这两个就是分片的副本。
通常我们三个节点建立两个副本就可以了,三份数据均匀得到分布在三个节点。如果建立三个副本会怎么样呢?
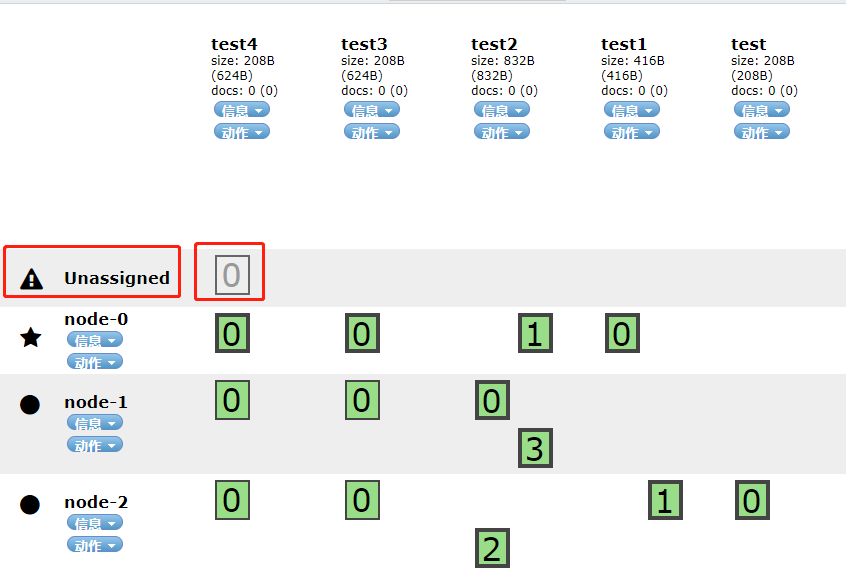
如上所示我们看到多出一个Unassigned的副本,这个副本其实是多余的了,因为每个节点已经包含了分片的本身和其副本,多于这个没有意义!
#分片与副本的组合
首先我们看下不指定分片和副本所创建的索引是什么样儿的?
PUT /test6/
{
"settings":{
"index":{
}
}
}
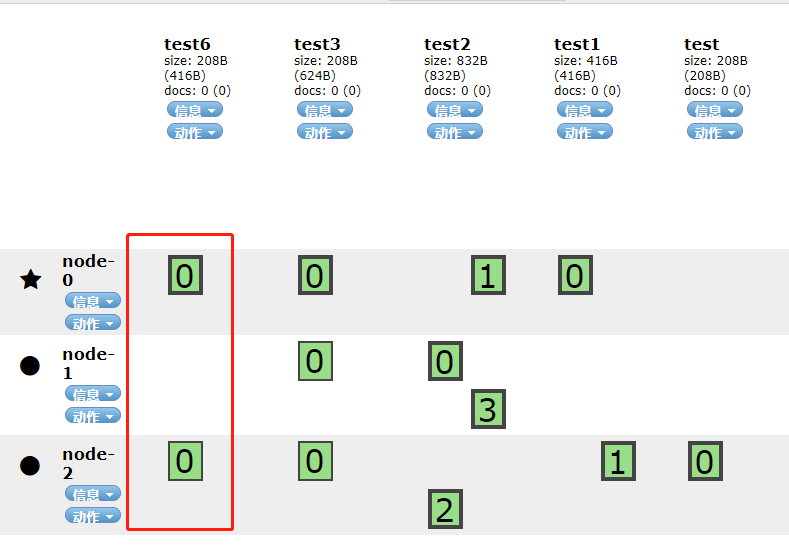
如上图所示看到默认是有一个分片和一个副本的。
下面我们创建两个分片和两个副本:
PUT /test7/
{
"settings":{
"index":{
"number_of_shards" : "2",
"number_of_replicas" : "2"
}
}
}
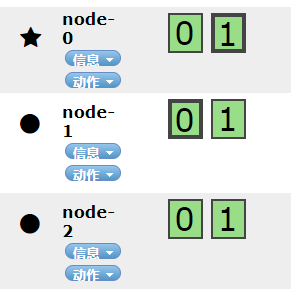
再来一个三个分片两个副本的情况:
PUT /test8/
{
"settings":{
"index":{
"number_of_shards" : "3",
"number_of_replicas" : "2"
}
}
}
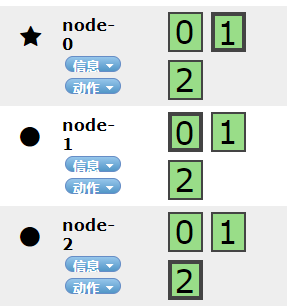
如上所示看到分片和副本都均匀的分布在每个节点上。
三、缩容与扩容
缩容
我们首先看下如果三个节点有一个节点宕机了,上文的test8的分片和副本会有哪些变化?我们将node-2节点关闭,然后查看head。
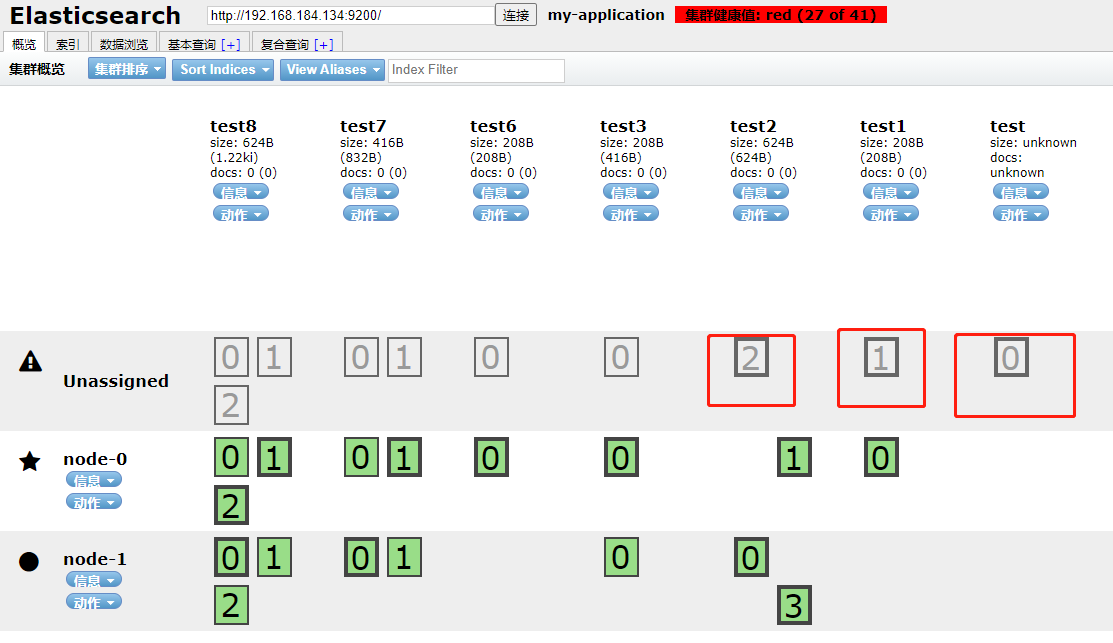
如上所示,原本的node-2节点变成了Unassigned,并且注意我标注的三个红框内的分片,这三个分片已经随着节点的宕机消息了,这就造成了数据的丢失;反观后面几个,虽然node2宕机了,但是由于我们做了分片与备份,索引仍然可以正常的工作。
不知道各位同学发现更加有趣的没有,原本在node-2的2号分片移动到了node-0节点:
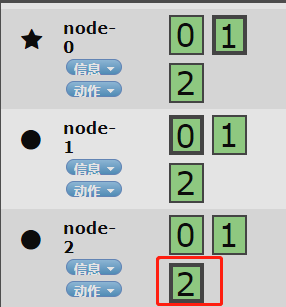
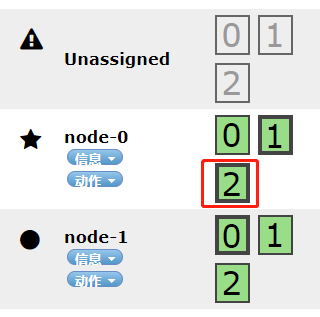
综上所述:在使用es集群的过程中,一定要注意分片和副本的使用,保证我们整个集群的高可用性。
另外我们再次将node-1节点停掉,看看会发生什么现象?
通过head发现整个集群已经无法进行访问了。

通过接口去查询集群状态也不能够访问了:

结论:当集群中只有一个节点的时候,将导致整个集群不可用。
扩容
经过上面的宕机试验后,我们现在要对宕机的服务进行重启,首先启动node-1服务。
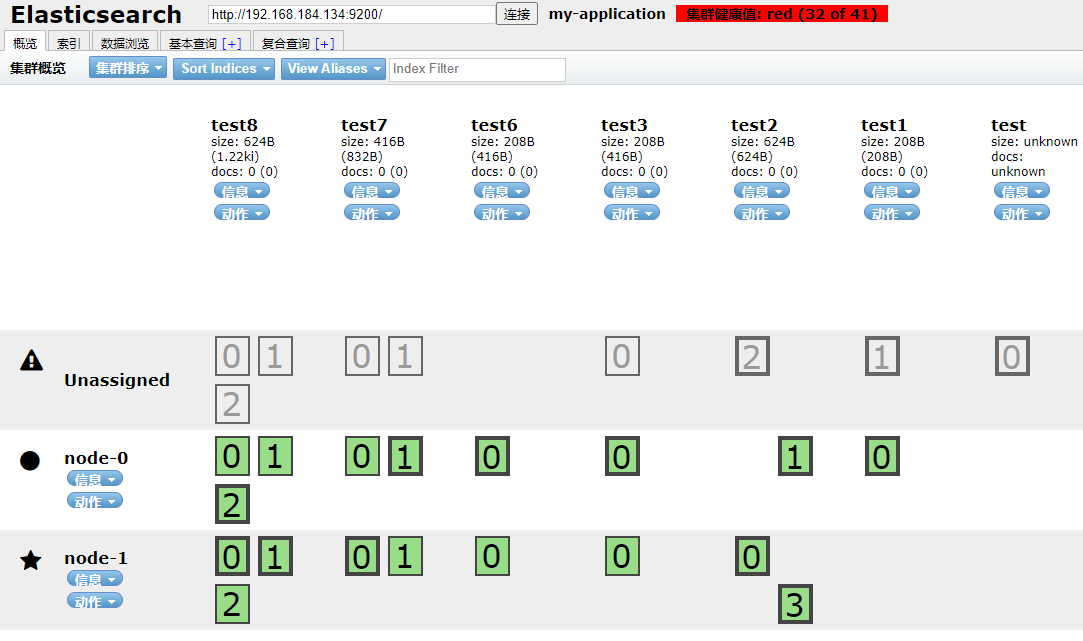
如上发现集群已经能够恢复访问了。
此时我们在两个几点可用的情况下创建一个三分片,两个副本的索引。
PUT /test9/
{
"settings":{
"index":{
"number_of_shards" : "3",
"number_of_replicas" : "2"
}
}
}
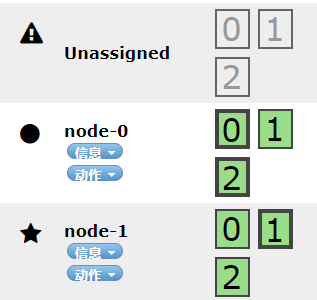
如上所示,分片与副本的分布没有问题,这是将node-2恢复
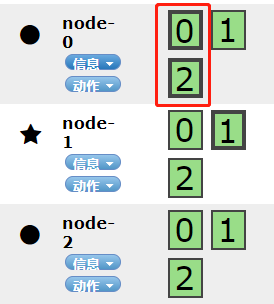
如上所示发现node-2的全部都是副本,并没有将分片移动到node-2上。
四、索引的路由计算
通过上面的实验,我们发现了分片和副本的存储规律,那么在每次我们进行索引的时候,是通过什么样的路由方式去找到对应的分片,从而获取我们想要的数据呢?
实际es是通过hash运算找到每次数据存储的位置,公式如下:

routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。
通过上面的公式,我们理解并且也需要记住一个重要的规律:
创建索引的时候就确定好主分片的数量,并且永远不会改变这个数量
数量的改变将导致上述公式的结果变化,最终会导致我们的数据无法被找到。















 2979
2979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











