






 本文探讨了如何通过AGI技术结合预测平台数据,进行足球比赛结果预测。涉及数据收集预处理、特征工程、模型选择与训练,以及结果预测与验证,展示了AI在体育分析中的潜力和应用价值。
本文探讨了如何通过AGI技术结合预测平台数据,进行足球比赛结果预测。涉及数据收集预处理、特征工程、模型选择与训练,以及结果预测与验证,展示了AI在体育分析中的潜力和应用价值。
引言
沿着我之前的文章思路,如果说上一篇文章只是提供一个思路和遐想的话,那么接下来的这篇文章,则通过一个实际例子,来和各位专家、技术大牛讨论一下,这个思路的可落地性。
注:本来从事产品职业人多年,所以,只能提供想法和思路,无法真正落地。经过这么多年的职业道路,也认识了很多技术大牛和开发高手,所以非常欢迎有志同道合之人,和我一起进行更深入的探讨,本文限于篇幅,权当是娱乐和休闲,大家不必较真,欢迎拍砖,但我更希望看到的是大家通过我的抛砖引玉,萌生更有趣的想法和建议,万一想法实现了呢?
背景
足球赛事结果预测一直是体育分析领域的热门话题。随着人工智能技术的发展,尤其是AGI(通用人工智能)的应用,我们有了更加科学和系统的方法来预测比赛结果。本文将探讨如何利用预测平台的资料库数据,结合AGI技术,对足球比赛结果进行精准预测,并提供实操性强、专业性强且富有趣味性的分析方法。
因为之前发表了一篇《畅想:利用AGI技术融合专业知识与数据分析,精准预测足球比赛结果》的博文,我想沿着这个思路,进一步理顺一下这个思路。
然而,由于本人水平有限,加上这个“产品”目前没有任何可借鉴和参考的友商竞品,我只能是作一些方案和方向性的提纲,欢迎大家给我留言,帮助我一起对这款产品进行一个前期的思路归纳。
正文
以下,就如何结合现有公开数据,通过机器学习技术,做一个简单的实现流程介绍。
一、数据收集与预处理
首先,假设我们可以从各大体育预测平台(如捷报网)收集相关数据。这些数据假设是已经经过了足球评论专业人士的理论建模,也结合了他们的专业知识。从下图中可以看出,这些数据包括球队的历史战绩、球员状态、近期表现、主客场因素等。数据预处理是关键步骤,需要清洗、标准化和转换数据,以便于AGI系统更好地理解和学习。
以下数据示例是以我最喜欢的两支球队为例(数据和图片均来自捷报网),针对欧冠第一场比赛结果进行数据收集:
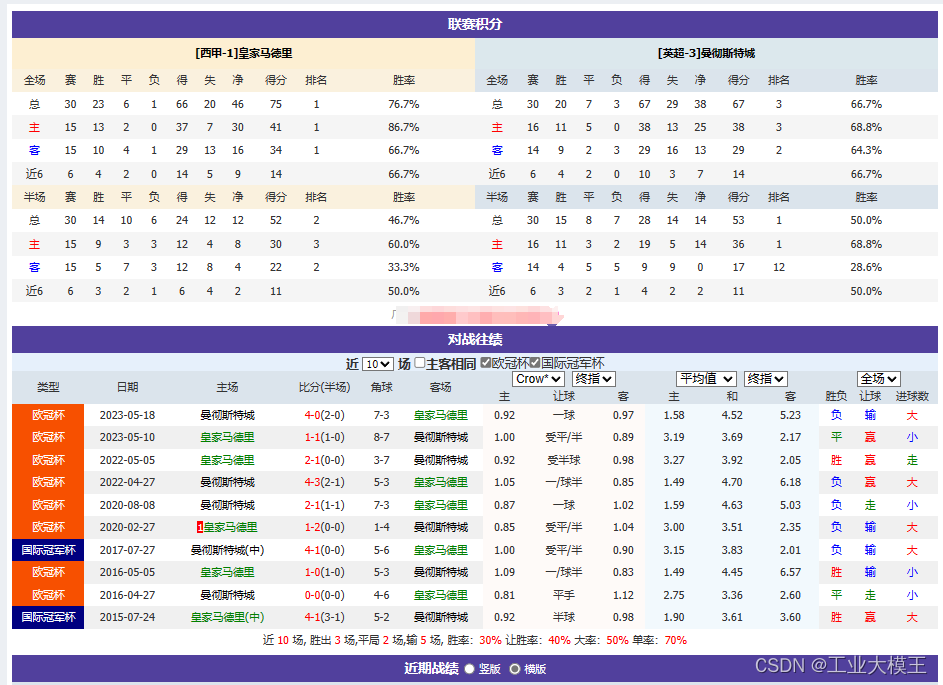
由于篇幅的原因,我这里仅仅只是截取了部分图片作为示意。
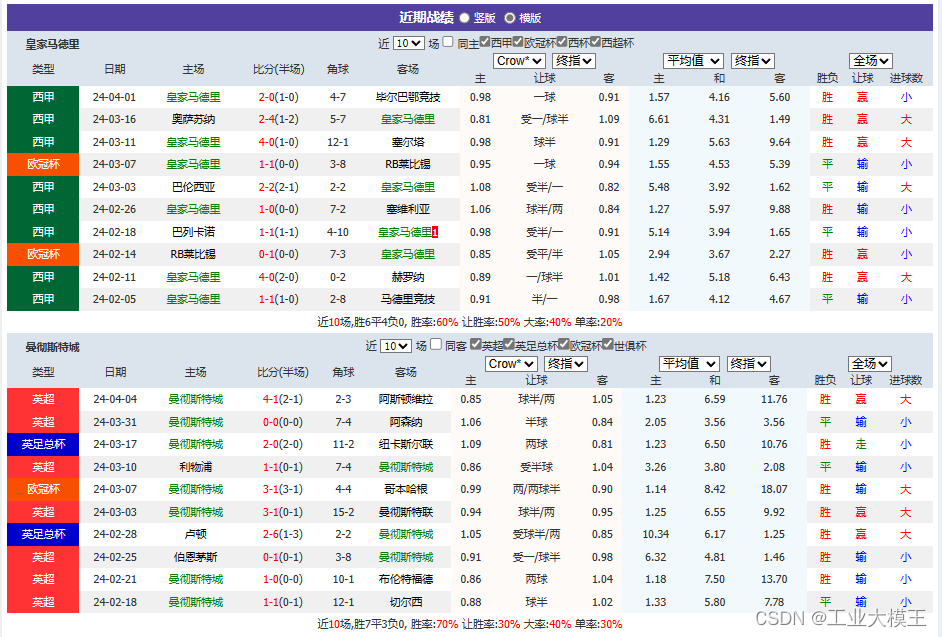
以上这些数据,都可以作为我们模型的输入项,但是,对于这些数据的理解,不同于对于自然语言的理解。我认为两者在原理上,是有着相通之处的,只不过我们缺少的是一个针对这种场景的NLP模型,可以将以上数据处理成计算机能够理解和处理的自注意力机制模型,这个模型需要我们的算法工程师进一步探索,从而得到类似于Q、K、V这样的抽象模型。
当然,目前第一步,是如何处理这些输入项数据,否则,这些数据就是没有任何实际参考意义的内容而已。
二、特征工程
特征工程是提高预测准确性的核心环节。我们可以从数据中提取有意义的特征,如球队的场均进球数、失球数、胜率、平率等。此外,还可以考虑球员的伤病情况、红黄牌记录、历史交锋记录等,这些都是影响比赛结果的重要因素。


以上数据和图片均来自捷报网。
三、模型选择与训练
选择合适的机器学习模型是预测成功的关键。我们可以尝试多种模型,如决策树、随机森林、支持向量机等,并使用交叉验证来评估模型性能。AGI技术可以帮助我们在复杂多变的数据中找到最佳模型,并进行训练。
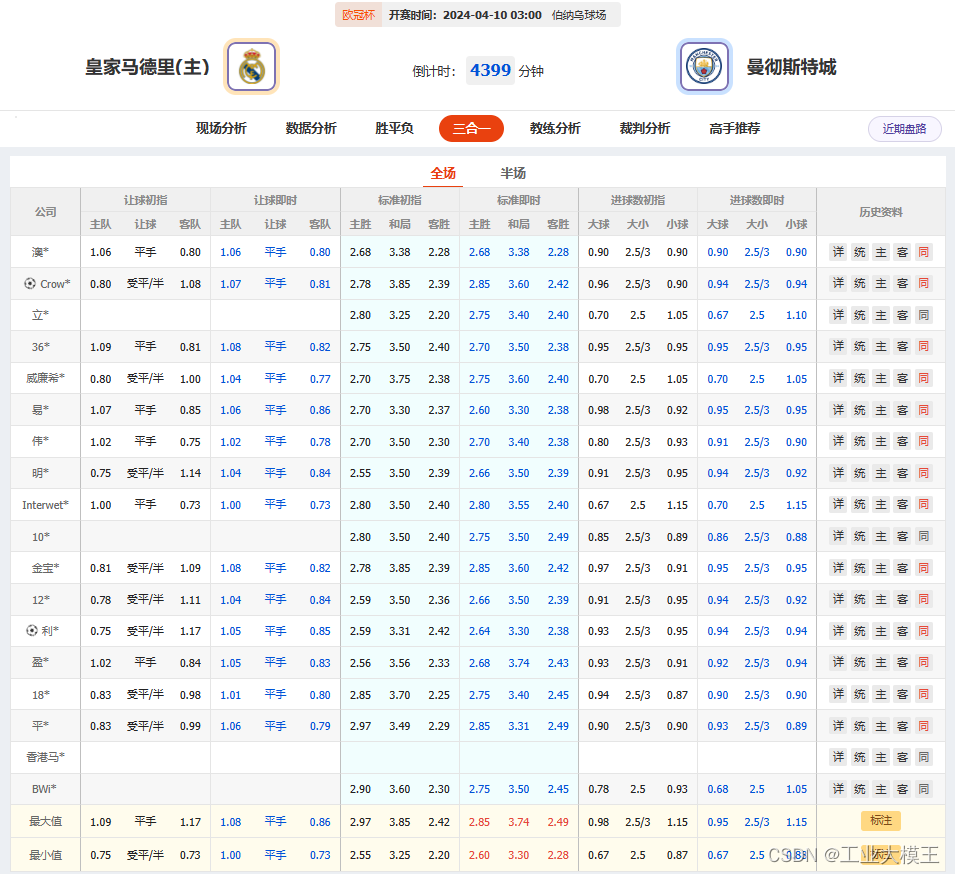
上图仅仅作为示意而已。
四、结果预测与分析
利用训练好的模型,我们可以对即将到来的比赛进行预测。AGI技术不仅可以给出比赛结果的预测,还可以分析可能的进球数、角球数等。此外,AGI还可以根据实时数据调整预测结果,提高预测的准确性。

上图仅仅作为示意而已。通过模型预测和网上数据的对比、概率分析,交叉验证模型预测的精度和准确性。
五、结果验证与优化
预测结果需要通过实际比赛结果进行验证。通过对比预测结果和实际结果,我们可以评估模型的准确性,并根据反馈对模型进行优化。AGI技术可以自动调整参数,不断迭代,以提高预测的准确率。
上图仅仅是作为一个示意而已。
结语
AGI技术在足球赛事结果预测中的应用展现了其强大的数据处理和学习能力。通过结合预测平台的资料库数据,我们可以更加精准地预测比赛结果。这不仅为球迷提供了有趣的参考,也为体育分析师和博彩公司提供了有力的工具。随着技术的不断进步,我们期待AGI在体育预测领域带来更多的创新和突破。
足球赛事预测虽然和数据科学有一定的相关性,但也有其各种不确定性(例如:打假球)。希望读者在享受各种胜负预测的乐趣时,也别忘了比赛本身的精彩和激情。让我们一起期待AGI技术带来的惊喜,同时也享受足球带来的无限可能!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











