







百度easydl文本分类对垃圾进行分类
1.文本分类创建过程
按照定制化文本中的产品介绍及使用手册完成相关内容。
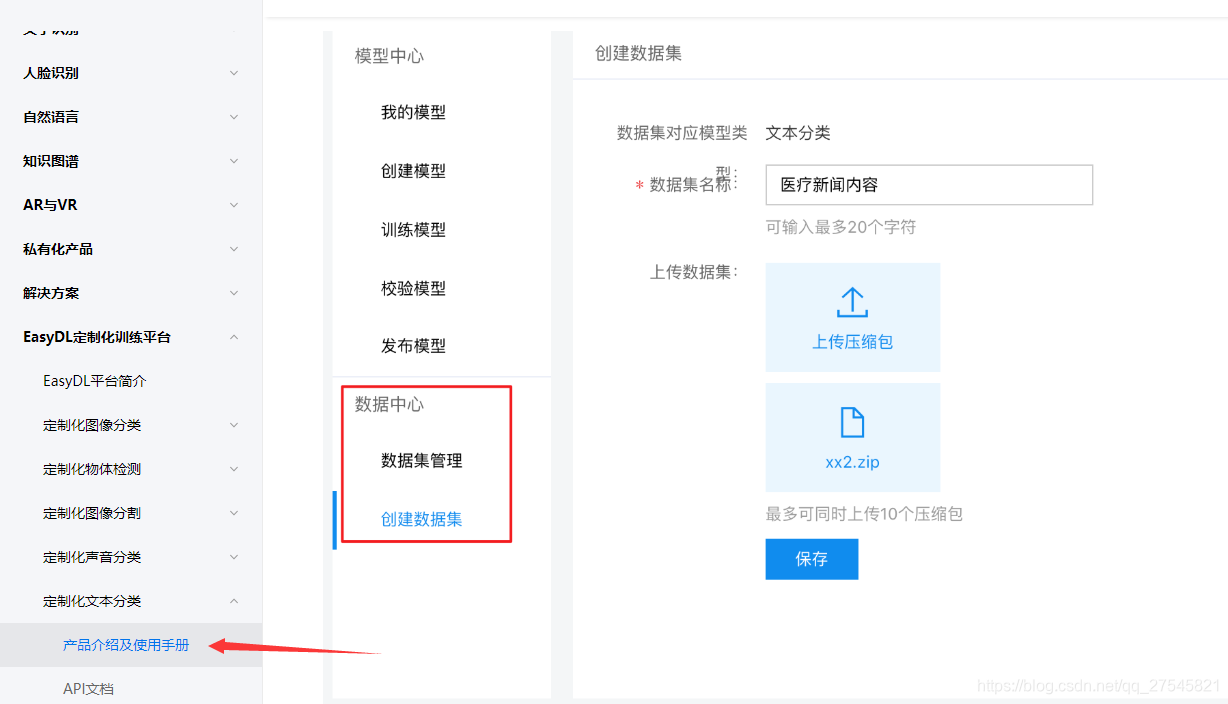
注意要点:
注意1:txt文件必须是utf-8的文件格式
1.1python写一段程序来生成数据文本
a=' 旧浴缸 盆子 坏马桶 旧水槽 贝壳 化妆刷 坛子 海锦 花生壳 菜板 砖块 卫生纸 篮球 桃核 杯子 陶瓷碗 一次性筷子 西梅核 坏的花盆 木质梳子 脏污衣服 烟蒂 渣土 湿垃圾袋 瓦片 扫把 '
b='中国青年报客户端成都9月26日电(实习生 陈静 中国青年报·中国青年网记者 王鑫昕)9月26日上午11时,在四川省青年联合会的组织下,30多名青联委员和各界青年代表在成都开展“祝福香港·点赞祖国”主题活动,表达内地与香港青年心连心,共同祝福新中国成立70周年'
for i in range(100):
if(a[i]==' '):
c=a[i:(i+4)]+b[(i+6):(i+9)]+b[i:(i+6)]#添加一段文字来生成更多数据
#c=a[i:(i+4)]
d=str(i)#生产的txt文件名
f = open(d+'.txt','w',encoding='utf-8')#格式必须为utf-8
f.write(c)
print(c)
注意2:如果多次上传的压缩包里面分类命名存在一致,系统会自动合并数据
注意3:分类的命名需要以数字、字母、下划线格式,目前不支持中文格式命名,同时注意不要存在空格
给出我的数据集


最后打包成zip上传即可
2.模型训练
基本按照文档来做就好了,文档很详细
选择之前上传的数据集,点击训练即可
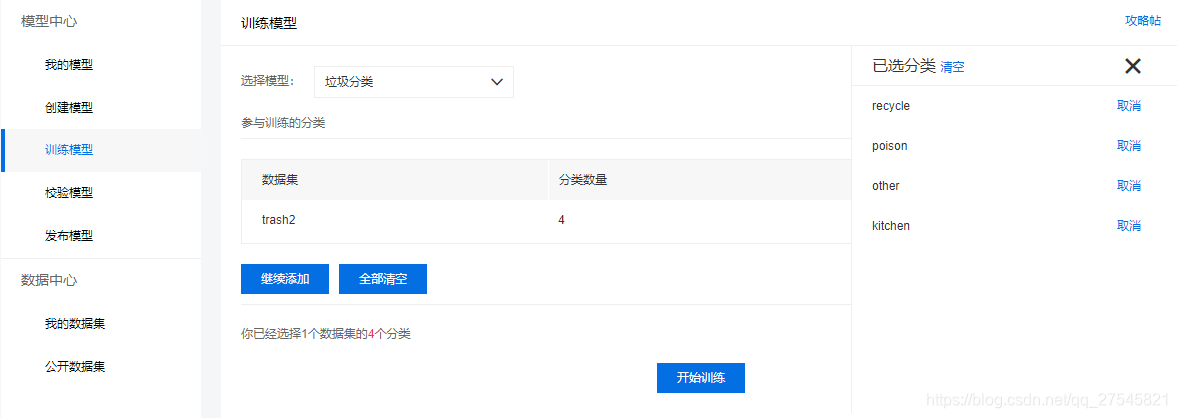
训练一般很快,数据少的15分钟就好了
训练好了下一步就是模型校验
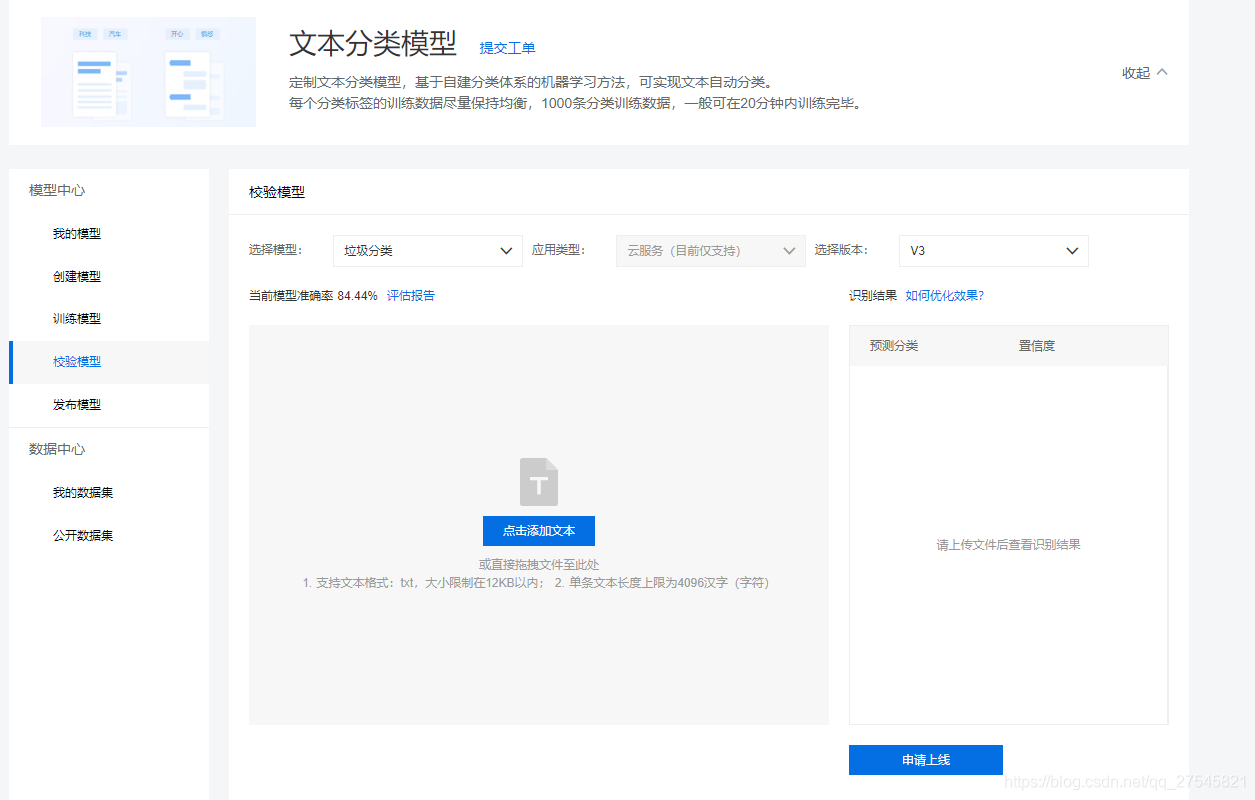
每一类100条数据得到一个84%准确率的还算可以。
3.模型发布
在我的模型列表——找到新训练好的模型版本——点击申请发布
这个一般差不多要等一天,耐心地就是了
4.python3调用在线api接口
由于百度easydl中api文档大都是python2的代码,而且比较老旧
error_code":336002,“error_msg”:"Invalid JSON
这是由于输入的文本格式不对
#api 代码里是
params = "{\"text\":\"西瓜\"}"
应改为
params = {
"text": "西瓜",
"top_num": 5
}
#python2代码
# encoding:utf-8
import urllib2
'''
easydl文本分类
'''
request_url = "【接口地址】"
params = "{\"text\":\"西瓜\"}" ###注意这里不是这样写的,看下面python3的代码
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
request = urllib2.Request(url=request_url, data=params)
request.add_header('Content-Type', 'application/json')
response = urllib2.urlopen(request)
content = response.read()
if content:
print content
#这是给的python2代码
这里给出我的python3代码。
import urllib.request
import urllib, json, base64
request_url = '接口网址'
access_token ='自己的'
params={
"text": "一个盆子",
"top_num": 2
} #********这个才是对的*********弄了好久
params = json.dumps(params).encode('utf-8')
print(params)
headers={'Content-Type':'application/json'}
request_url = request_url+"?access_token="+access_token
print('1',request_url)
mess=urllib.request.Request(url=request_url, headers=headers, data=params)
mess = urllib.request.urlopen(mess)
logInfo = mess.read().decode()
print(logInfo)
输出结果
{"log_id":3173339169514822677,"results":[{"name":"other","score":0.4282606542110443},{"name":"recycle","score":0.2605192959308624}]}
结束 –
第一次写博客,希望以后能多记录自己爬过的坑


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









