







内存泄漏可以使用kmemleak等工具排查,但我的项目使用该工具无法查到原因。在跑Linux休眠唤醒的压力测试过程中发现,meminfo里的free内存一直在减小,SUnreclaim内存一直在增大,即系统发生了内存泄露。该压力测试只测试系统的休眠唤醒稳定性,基本就是各个驱动模块的suspend和resume函数在反复调用,因此猜测极大概率是某个驱动的suspend或者resume函数里存在内存泄露。我的测试脚本非常简单,如下所示:
cp /mnt/nfs/lib/libpmu.so /lib
#加载pmu驱动
modprobe pmu
#循环打印meminfo和slabinfo
(
while :
do
echo 3 > /proc/sys/vm/drop_caches
cat /proc/meminfo
cat /proc/slabinfo
sync
sleep 1
done
)&
#循环执行休眠唤醒测试999999次
cd /mnt/nfs/app/pmu_sample && ./pmu_sample -p cfg/pmu_rtc_sleep.cfg -r 999999以下是内存泄露的情况,系统运行20多分钟泄露了148KB的内存,运行一晚上会泄露8MB的内存。可以看到主要是Slab中的SUnreclaim内存在泄露。
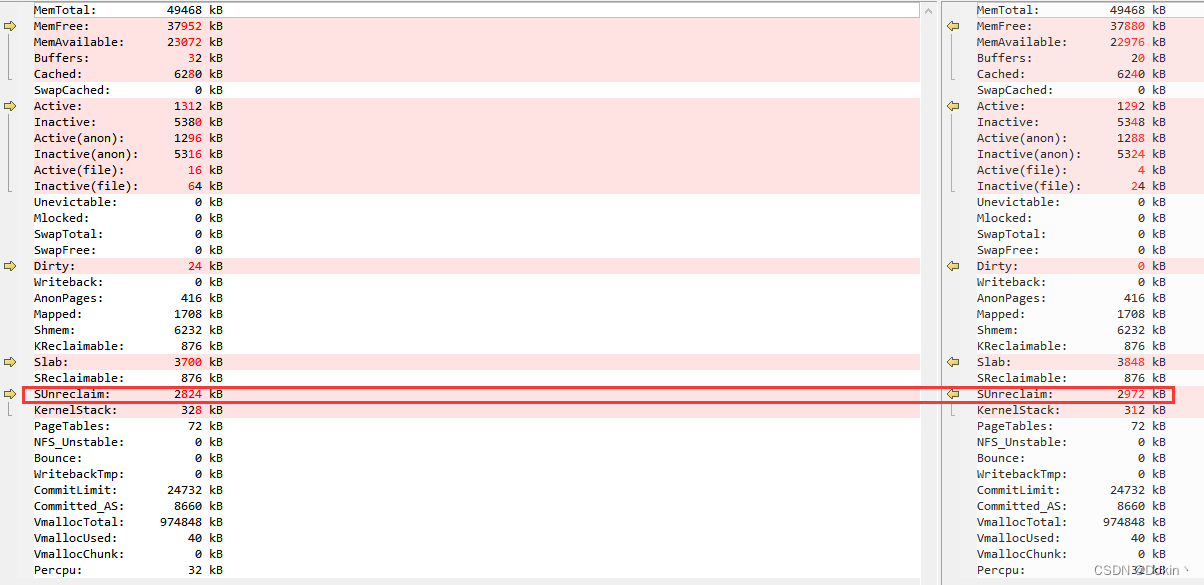
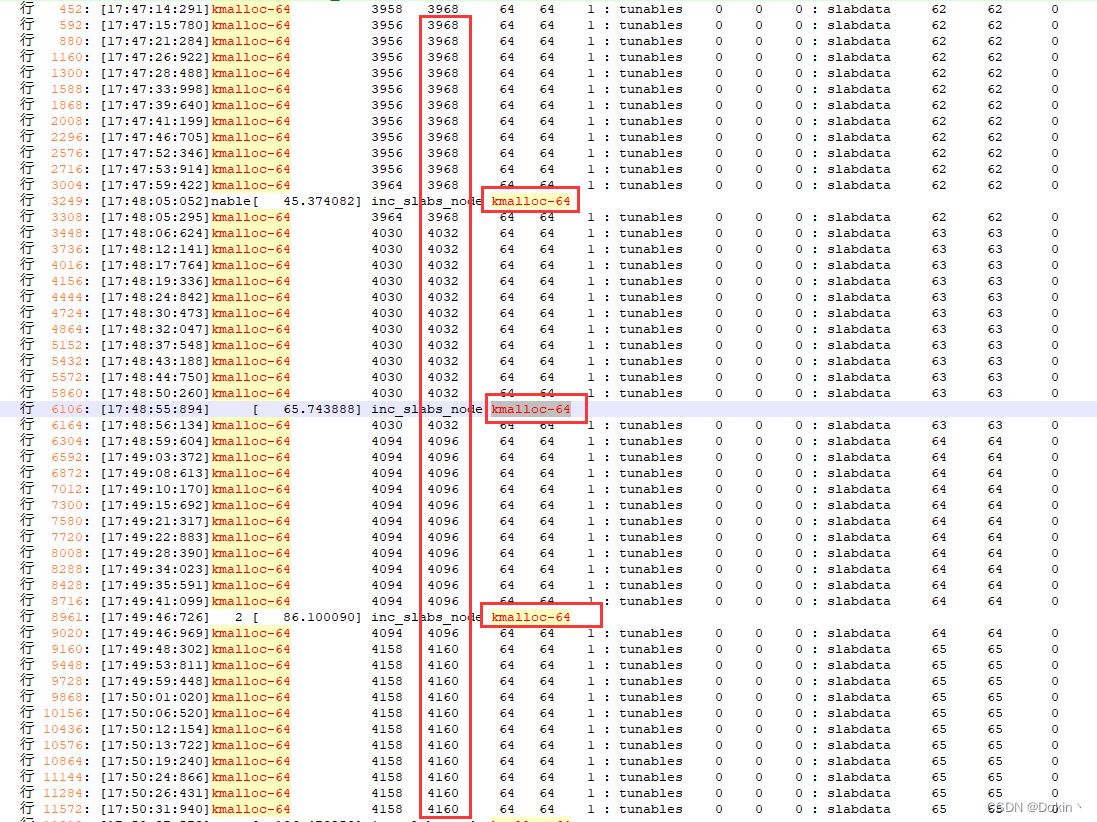
既然是slab内存泄露,通过cat /proc/slabinfo就可以更具体的信息,前后对比如下:

从前后对比的slabinfo来看,是slab中的kmalloc-64内存池在不停的泄露。由于我的设备运行环境是休眠唤醒压力测试,没有什么业务在运行,因此理论上系统开始休眠唤醒之后内存申请和释放的地方是极少的,这种情况下可以考虑直接用dump_stack这个利器去查找泄露的地方。可以从两个地方入手,一是kmalloc函数,可以在判断出是申请kmalloc-64时进行dump_stack;二是找到/proc/slabinfo实现的地方,并进一步找到让slabinfo->num_objs成员增加的地方。这里我选择了后者。
首先查看一下/proc/slabinfo的实现:

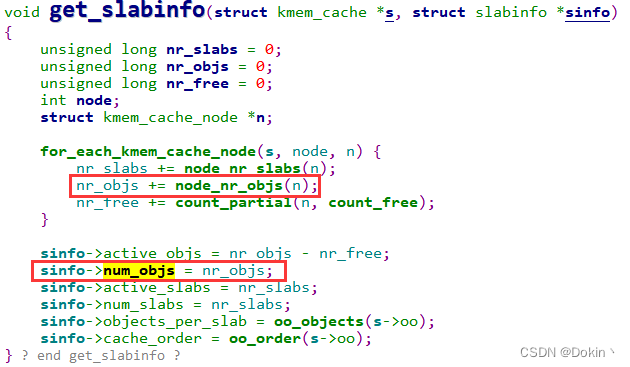

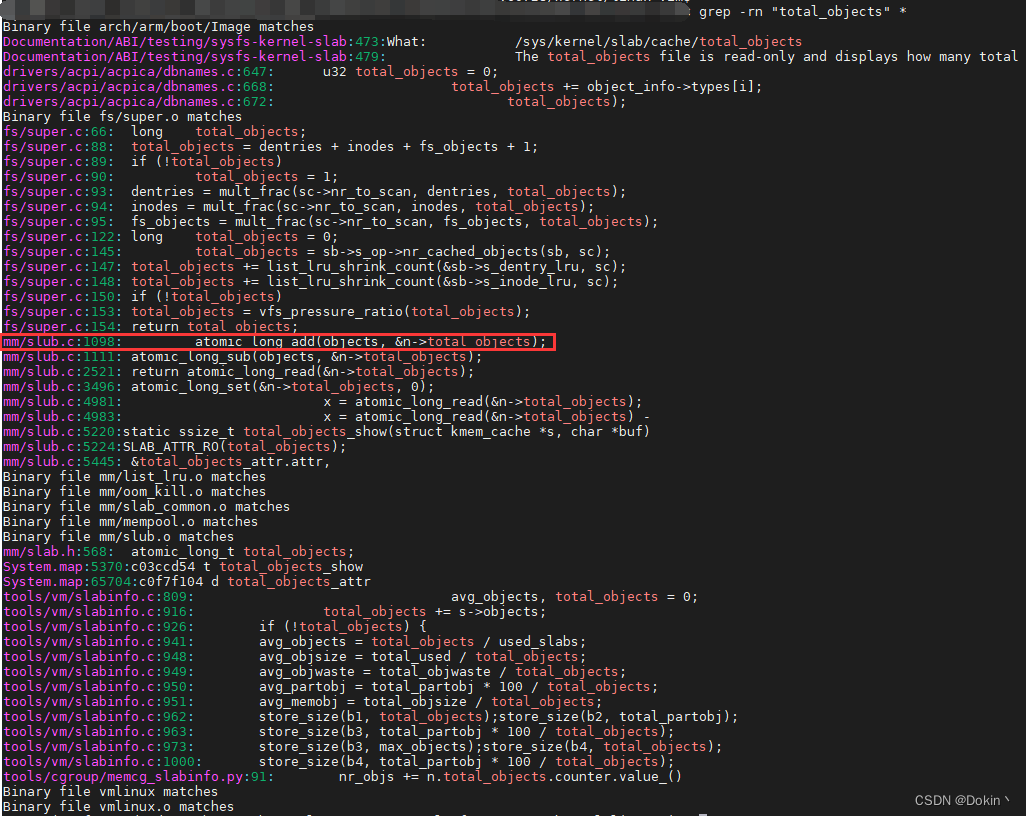
可以看到,cat /proc/slabinfo打印的值是来源于kmem_cache_node的total_objects成员,在内核中检索total_objects,如下所示,发现只有“atomic_long_add(objects, &n->total_objects)”。
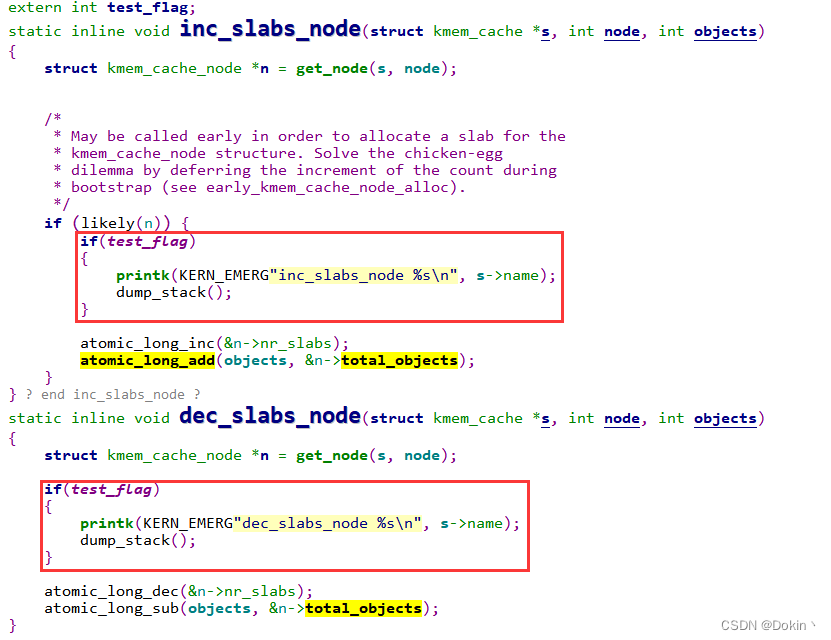
找到atomic_long_add调用的地方,在此处加上dump_stack。test_flag是我加的触发条件,避免在开机阶段就触发dump_stack,这个test_flag是在系统开始休眠唤醒操作时置1的,因此开机阶段不会打印。这里起始还可以通过判断s->name是否等于kmalloc-64来进一步过滤出kmalloc-64,但我的测试环境不会有很多内存申请和释放,所以干脆不加。
加上之后再次进行压力测试,在打印的日志中搜索kmalloc-64,如下所示。可以看到kmalloc-64是一直在泄漏的,而且每次都是dump_stack之后增加,这说明我们增加的dump_stack正确捕捉到了泄漏的位置。
下面是dump_stack的打印:

从dump_stack的信息可知是clk模块申请了内存,在clk的resume函数中调用了clk_get,clk_get调用clk_hw_create_clk,clk_hw_create_clk函数会调用alloc_clk,这个函数实现如下。就是其中的kzalloc申请的内存没有释放。实际上clk_get有一个对应的函数clk_put,这个函数会释放对应的内存,而我们的clk驱动只调用了clk_get,没有调用clk_put,因此造成了内存泄漏。
static struct clk *alloc_clk(struct clk_core *core, const char *dev_id,
const char *con_id)
{
struct clk *clk;
clk = kzalloc(sizeof(*clk), GFP_KERNEL);
if (!clk)
return ERR_PTR(-ENOMEM);
clk->core = core;
clk->dev_id = dev_id;
clk->con_id = kstrdup_const(con_id, GFP_KERNEL);
clk->max_rate = ULONG_MAX;
return clk;
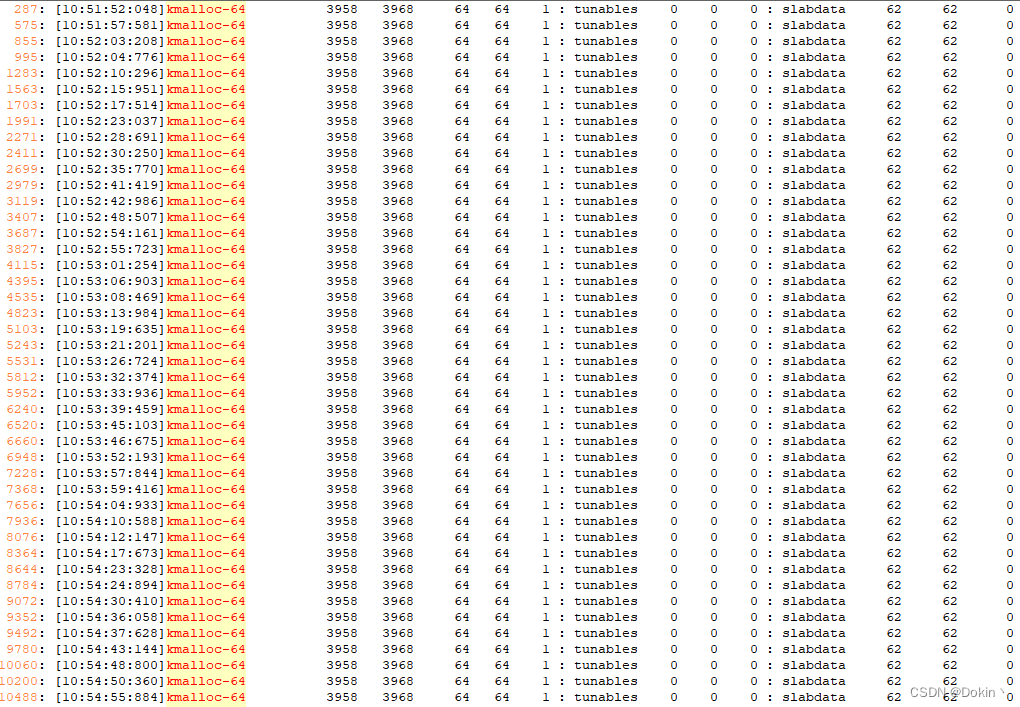
}修改完毕后再次运行,可以看到,没有再出现泄漏了。
















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











