






每天给你送来NLP技术干货!
来自:南大NLP

01
—
研究动机
随着人工智能技术的不断发展,人工智能在经济贸易、教育、医疗、养老以及城市运行等社会生活中扮演了越发重要的角色。在这一背景下,如何高效便捷地实现人机交互成为了一个现实的需求,相应地,如何实现自然语言的高效生成对新一代以自然语言为交互手段的人机协作系统而言具有重要的研究价值。
并行文本生成(Parallel Text Generaion)是近年新兴的一种生成范式,它与传统自回归式模型串行地对句子进行解码的方式不同,以非自回归式Transformer(Non-autoregressive Transformer, NAT)为代表的并行文本生成模型可以同时预测出句子中所有的词,实现了生成效率上的极大突破。然而,与生成效率优势形成极大反差的是,并行文本生成模型的性能远落后于自回归式模型。
大量的研究工作致力于提升并行文本生成模型的质量。其中一类重要的研究是改善并行生成的单词之间的依赖建模,例如,Qian等人[1]提出的Glancing Transformer模型不仅在传统的基线系统上取得了性能的提升,更在WMT-2021中的德语-英语翻译任务上超过了众多参赛的自回归式翻译系统,验证了并行文本生成模型的巨大潜力[2]。另一类重要的研究则是利用隐变量来提取目标序列的信息来辅助模型对目标序列的并行生成建模,例如,本组此前的研究工作《基于隐式类别建模的非自回归式翻译》正属于这一类方法,探索通过建模目标序列的隐式词类别信息,实现了在翻译任务上性能的极大提升。
遗憾的是,虽然上述上述研究实现了生成质量的改进,但提出的方案往往仍依赖于知识蒸馏技术帮助模型克服数据中的多样性问题:例如在翻译任务中,相同的单词、短语总是可以有多种不同的翻译方案与之对应,这种多样化直接会导致模型优化困难,利用一个教师模型(例如自回归式Transformer)的输出作为目标,可以直接筛选掉原本过于多样的数据目标,使得学生模型可以在较为“单一”的数据上进行训练。
然而,这种方式显然存在着诸多局限。首先,知识蒸馏技术的引入需要额外训练一个教师模型,增添额外的训练代价。其次,这一方案会受到教师模型性能的限制,事实上,我们很难保证教师模型的性能总是足够高质量。值得说明的是,目前大多数的研究更多关注在知识蒸馏技术下的探索,对于如何摆脱知识蒸馏技术直接在多样化数据上进行学习,实际上并未得到充分的关注。因此,如何实现对多样化数据的学习仍是一个开放且值得探索的问题。
02
—
贡献
1. 本文提出了一种基于隐变量的并行生成模型latent-GLAT,探索了结合使用隐变量建模技术和渐进式学习的策略,帮助模型实现了在多样化数据上的学习。
2. 本文对多项文本生成任务进行了实验,不仅验证了latent-GLAT模型的有效性,同时也验证了知识蒸馏技术的潜在局限——Transformer模型并不能获得令人满意的性能,难以支持作为教师模型。
03
—
解决方案
为了对多样化的数据进行学习问题,本文探索了一种基于隐变量的并行生成模型latent-GLAT,利用离散隐变量抽取目标序列的信息,并划分多样化的目标以改善并行生成模型的建模。
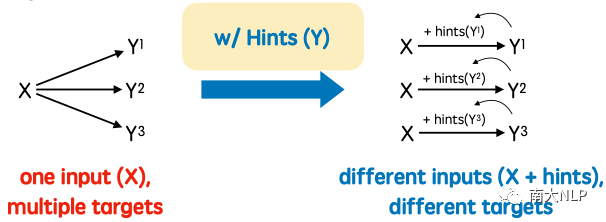
图1: 引入隐变量转化“一对多”目标为“一对一”
基于隐变量这一技术路线背后的思想如图1所示,不妨将对多样化数据的学习过程表述为:对于输入X,有Y1、Y2、Y3三个可能的输出目标需要建模。显然,不同目标之间的差异会使得模型的优化带来极大的困扰,导致输出混合多个输出的情况。而基于隐变量的方案可以从目标Y中提取出一定的提示信息(Hints),从而将原本X—>{Y1,Y2,Y3}的“一对多”的学习目标转变为{X,Hints(Yi)}—>Yi的“一对一”以及X—> Hints(Yi)的建模,而若能选择易于建模的Hints(Yi)作为目标,则可以有效地对多样化数据进行学习,从而摆脱对知识蒸馏技术的依赖,可以将其形式化地描述为:
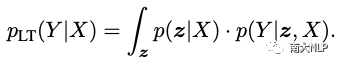
其中,p(z|X)用于建模X—> Hints(Yi),p(Y|z,X)则用于建模{X,Hints(Yi)}—>Yi。如何获取以及有效地使用Hints即为此类方案的研究重点。
尽管目前基于隐变量的方案实现了生成质量的改进,但值得注意的是,现有方案通常使用自回归式或者深层次的迭代模型来参数化p(z|X),往往生成效率不高。更重要的是,现有方案中往往欠缺对目标文本中词依赖关系的建模,仍存在生成质量上的隐患。
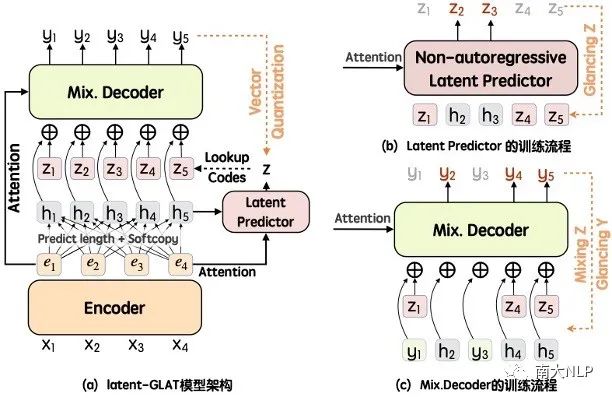
图2: latent-GLAT模型的架构和隐变量预测器以及词解码器的的训练流程示意
针对上述问题,latent-GLAT探索了结合隐变量建模以及依赖建模方案的改进方案。如图2(a)所示,latent-GLAT使用了向量量化技术(Vector Quantization)获取与目标序列等长的隐式词类别信息,并作为Hints来分解原始目标,其好处是:相较于词来说,词类别的数目非常少,其潜在的多样化问题更小,可能更易于学习。更为重要的是,词类别信息往往有助于对词的预测。
基于上述假设,使用词的隐式类别信息作为Hints信息更好地支持并行文本生成模型对多样化数据进行学习。如图2(b)所示,本文提出使用非自回归式的隐变量预测器建模离散的隐变量序列,缓解原本隐变量预测效率低的问题。而有限且简单的隐变量也支持本文参考Qian等人提出的渐进式学习策略Glancing Training(GLT)优化该隐变量预测器,并计算其损失项为:
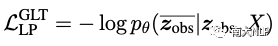
从原始的z中采样出的zobs,并作为条件预测剩下部分序列,建模两者之间的依赖关联。
进一步地,如图2(c)所示,latent-GLAT提出利用结合离散隐变量和词共同进行Glancing Training优化对目标文本序列的预测,从而在利用隐变量缓解数据多样化问题的同时,进一步考虑了对目标序列词之间的依赖关系建模,也鼓励了模型更依赖于隐变量信息,保证模型预测时的性能。
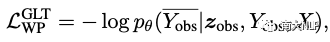
最终的优化损失项为:
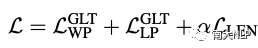
04
—
实验
本文在机器翻译、复述生成和对话生成任务上对提出的latent-GLAT模型进行分析。其中,对机器翻译任务的分析选用了常用的WMT14、IWSLT14德语-英语翻译数据集,同样地,选用常用的Quora数据集和DailyDialog数据分别对复述生成和对话生成任务进行实验。参考了相关论文,对各个数据集进行划分和预处理,此外,任务性能的评估则主要采用BLEU评价生成质量,计算单句解码延时并使用与自回归式模型的相对加速比反映模型的生成效率。
为了验证latent-GLAT模型的有效性,本文选择了NAT模型以及GLAT模型作为基线系统进行对比,同时将自回归式Transformer模型的结果作为参照。在实验中,各个数据集上模型的参数和优化策略则参考相关论文,使用了最为通用或与对比系统一致的设置。
表1: 各模型在机器翻译、复述生成和对话生成等数据集上的BLEU值和生成效率分析

表1所示为latent-GLAT和基线系统在各个任务上的性能,需要说明的是,本文主要在直接使用原始数据集训练的实验设置下进行比较。可以看到,在这一条件下,latent-GLAT模型的生成质量显著地超出了基线系统NAT和GLAT,同时也保持了一个高效的解码效率(加速比>10),验证了结合隐变量和扫视训练技术带来了巨大收益。
值得注意的是,Transformer模型在Quora以及DailyDialog数据集上的生成质量并不是那么让人满意,与NAT或者GLAT模型并没有太为显著的优势,表明了利用Transformer模型作为教师模型进行知识蒸馏训练方法的局限性。
为了进一步验证latent-GLAT模型的有效性,本文在更常用的机器翻译任务上对比了一些更为前沿的并行文本生成模型,其中包含基于隐变量的技术方案(LV-NAR、SynST、Flowseq、CNAT)以及基于迭代式解码的技术方案(CMLM和LevT)。
如表2所示,尽管基于隐变量的方案和基于迭代解码的方案可以显著地提升并行文本生成模型的翻译质量,但显而易见的是,这些依赖于复杂的迭代更新或者深层编码转换的方案极大地牺牲了模型的解码效率,并非最佳选择。与之相反的是,latent-GLAT保持了极为高效的解码速度,并显著地提升了生成质量。
表2: 各模型在机器翻译任务数据集上的BLEU分数和相对加速比

可以看到表2中,模型的生成质量和生成效率之间存在着一定的权衡:模型效率最高的LV-NAR并未取得令人满意的生成质量,而迭代式模型的生成质量则伴随着显著的效率下降。因此,本文进一步通过图2对质量和效率之间的权衡进行了分析,可以看到本文提出的latent-GLAT模型位于图2的右上角,表明:当效率相近时,latent-GLAT模型具备更高的生成质量,当质量相近时,latent-GLAT则具备更快的加速速度。
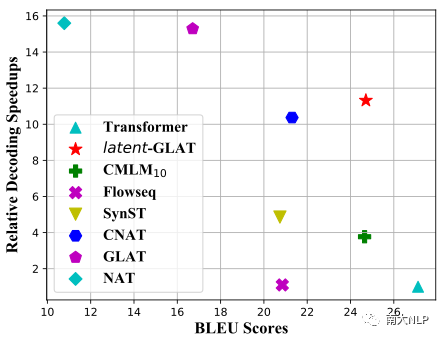
图3: 各模型在WMT14英-德测试集上的BLEU值和相对加速比
为了验证latent-GLAT是否能够有效地缓解数据多样性的问题以及摆脱对知识蒸馏技术的依赖,本文提出结合知识蒸馏技术训练前后的模型性能差异来进行分析。
如表3所示,可以看到latent-GLAT模型在机器翻译任务上仍可以通过知识蒸馏技术训练获取性能增益,但在多个数据集的平均BLEU值增益仅为0.95,而原始NAT模型以及GLAT模型的增益在5~6.5,表明latent-GLAT模型可以有效缓解了对于知识蒸馏技术的依赖。值得注意的是,基于隐变量的模型(CNAT/Flowseq)获得的增益在2.5~3之间,侧面验证了结合隐变量分解建模目标方案的有效性。
表3: 各模型在机器翻译任务中使用以及不使用知识蒸馏技术训练的BLEU值

为了验证引入的离散隐变量本身相较于原始的词(或句子)更易于学习,本文尝试利用Zhou等人提出的复杂度指标(Complexity)对数据的多样化程度进行了相应的分析。如表3所示,可以看到在WMT14上隐变量z和输入之间的对应关系(Inputs-z)相较于原始的输入(Raw ourputs)以及自回归式模型的输出(AT outputs)具备更小的Complexity值,表明从输入序列到隐变量z的多样性程度更低,更加易于被建模和预测,验证了latent-GLAT模型的设计动机。
表4: 各种数据集配置下的词级别和句子级别Complexity值
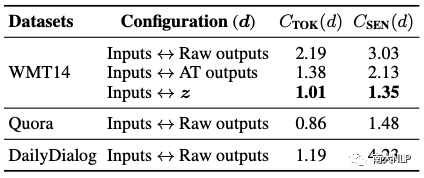
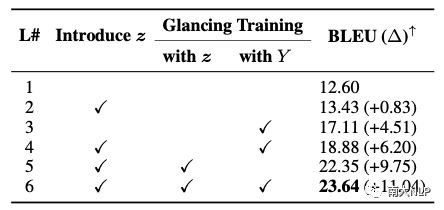
表5中则对latent-GLAT进行了消融分析,可以看到引入隐变量总是可以改善生成质量(L#2 vs. L#1,+0.83 BLEU 以及 L#4 vs. L3,+1.69 BLEU),基于离散隐变量使用渐进式训练策略Glancing Training对模型进行训练,生成质量获得了极大的提升(L#5 vs. L#1,+9.75 BLEU),超过了原始基于词的Glancing Training的性能(L#5 vs. L4, +3.55 BLEU),验证了离散隐变量对Glancing Training的改进作用。最终,基于词和隐变量上同时进行Glancing Training,模型取得了最好的性能。
表5: 在WMT14 EN-DE验证集上对latent-GLAT进行消融分析
05
—
总结
并行文本生成是一个极有前景的文本生成范式,如何进一步提升其生成质量也是时下的一个热点研究。为了克服数据中普遍存在的多样化现象为并行文本生成模型带来的挑战,大多数研究中默认采用了结合知识蒸馏技术训练的方案,虽然带来的性能的提升,但也一定程度上限制了模型的使用场景。为了直接学习原始的多样化数据,本文提出了latent-GLAT模型,利用离散隐变量所建模的隐式词类别信息来帮助模型摆脱对知识蒸馏技术的依赖。具体而言,latent-GLAT使用离散潜变量建模词的类别信息,并将原始目标划分为隐变量建模和基于隐变量的词预测任务。词类别的多样化程度远比单词弱,并且对词的预测很有帮助。随后,本文进一步结合渐进式学习策略建模每个目标,并鼓励模型建立对隐变量的依赖,最终在机器翻译、复述生成和对话生成任务验证了latent-GLAT的有效性。(相关链接:[论文][代码])
最近技术文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!














 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









