






Show-o大致如下:
作者:Mike Shou
链接:https://www.zhihu.com/question/665151133/answer/3608387516
来源:知乎
好久没来知乎了,简单总结下做这个工作的motivation:
1. 宏观来看,当下LLM和Diffusion,都太卷了,进入到靠公司堆资源的阶段。作为科研人员需要破局,更重要的是定义问题,如何将LLM/AR和Diffusion结合,就是一个under-explored的新问题,适合做科研。当下还比较早期,show-o/transfusion都肯定不是最终形态,期待大家一起来探索。show-o只有1.3B,也是为了大家更容易做改进。
2. 为什么结合LLM/AR和Diffusion,是个有意义的问题?
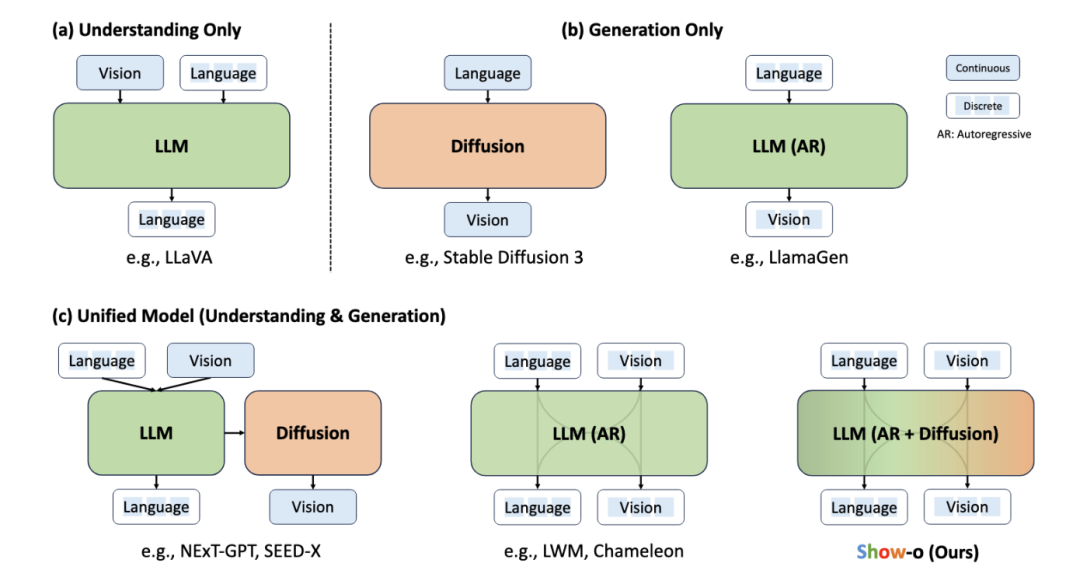
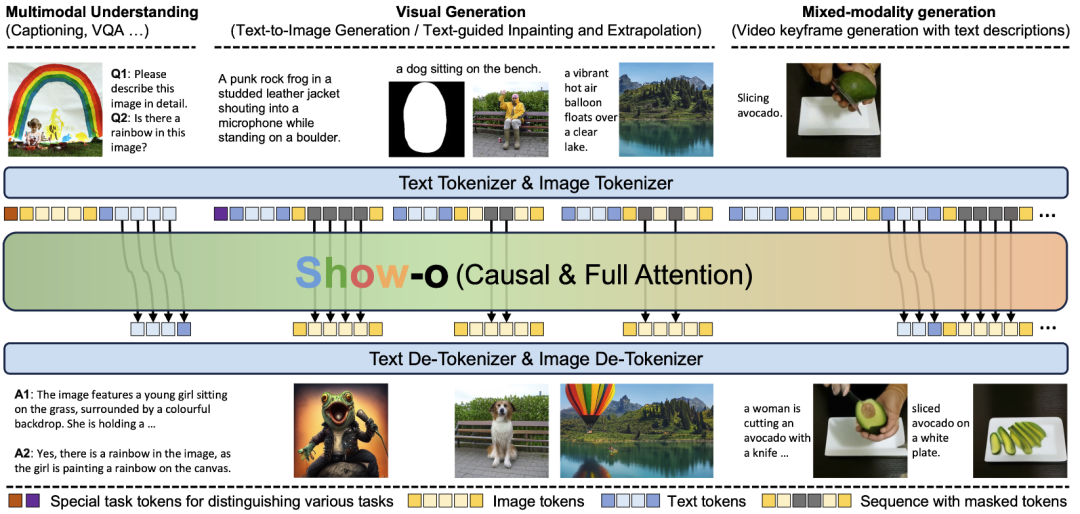
a. 主要还是从第一性原理来考虑。最终的Foundation Model,我们觉得会是个大一统模型,既能做生成,也能做理解,生成和理解的能力相辅相成。输入和输出,都可以是interleaved的text, image, video等的随意组合。
b. 最终的Foundation Model,会是只有AR没有Diffusion吗?现有的技术看来,Diffusion更快(不用像AR一步一步预测),生成效果也是Diffusion遥遥领先,AR不适合inpainting这种task,所以大概率,最终还是得有Diffusion。
c. 所以从上面两个对最终形态的预测反推,我们觉得研究,如何用一个LLM同时做理解和生成,兼容AR和Diffusion,是个很有意义的问题
此外,LLM/AR+Diffusion这是大方向上的,但真正做的时候,有一个更细节的问题大家也都关注到,那就是图像该用continuous还是discrete表征?
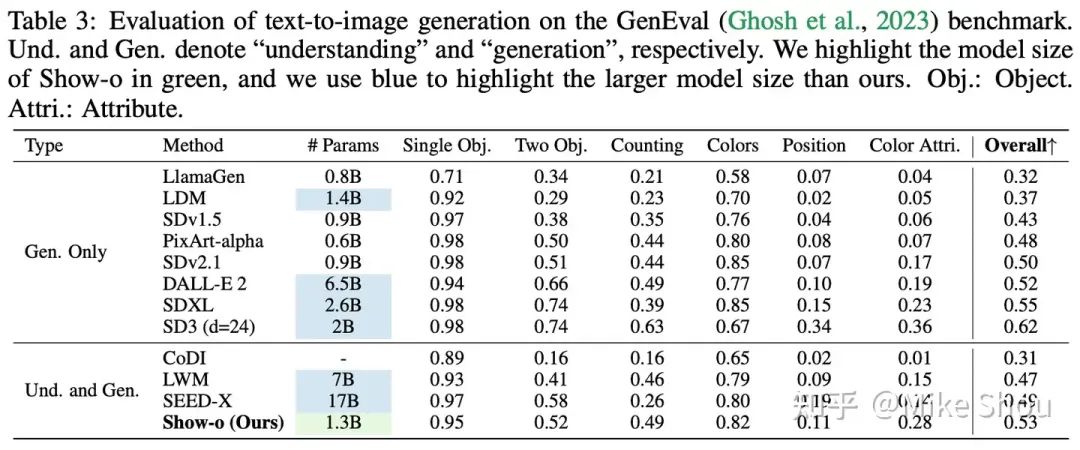
1. 对于这个问题本身,我并没有一个答案,有各种rationale后面可以再开展聊聊,很多还需实验验证。但一个可以观察到的现象是,尽管当下discrete diffusion很火,但真正在image generation做work的,清一色都是continuous diffusion,所以做show-o这个工作,一个目的也是初次探索,discrete diffusion是否在图像生成可比肩continuous diffusion,从下表结果看是可以的。
2. 早期开始这个项目的时候,因为discrete diffusion我们还在试,我也建议过团队用continuous diffusion,不过团队同学把这个否了,理由是更希望对于text和image,用同样的loss模式(predict token index)。或许这样将来更容易scale up,我也不太确定但也没有坚持,因为没多久discrete diffusion我们也做通了。所以后续看到Transfusion这种continuous的特别高兴。
3. 但其实不管generation这边用continuous还是discrete,理解那边最好的show-o模式,其实还是要用上Clip-ViT的表征。但值得注意的是,这可能并不能说明continuous比discrete的要好,只是说明Clip-ViT好,而Clip-ViT正好是continuous的:一个很重要的问题就是,我们当下的discrete image tokenizer没有像Clip那样用超大规模图文对训练,跟LLM align的还不太好。如果用上SPAE那种Pyramid,再加上大规模图文对训练,很可能discrete token的做image理解也会不错。
总之,不管是LLM/AR+Diffusion,还是连续 vs 离散,感觉都是非常有意义的科研问题,都挺早期的,值得探索。非常欢迎大家在这儿多多交流讨论。如果希望更深入的讨论,我们也建了个群,在show-o的GitHub上面可以找到。https://github.com/showlab/Show-o
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









