






主题
当LLM开始做足球解说:关于多模态模型在体育领域的应用
时间
2024.9.28 20:00-21:00 周六
入群

论文:MatchTime: Towards Automatic Soccer Game Commentary Generation (EMNLP 2024)
地址:https://arxiv.org/pdf/2406.18530所有代码、数据集均已开源
代码链接: https://github.com/jyrao/MatchTime/
项目网页: https://haoningwu3639.github.io/MatchTime/
数据集: https://huggingface.co/datasets/Homie0609/MatchTime/
演示视频: https://www.bilibili.com/video/BV1L4421U76m
大纲
关于多模态视频理解(简要介绍视频方面的跨模态应用)
体育领域的人工智能(数据集、分类任务、足球理解)
论文分享:"MatchTime: Towards Automatic Soccer Game Commentary Generation"
当前工作与未来规划(足球项目进展、通用模型概想)
引言
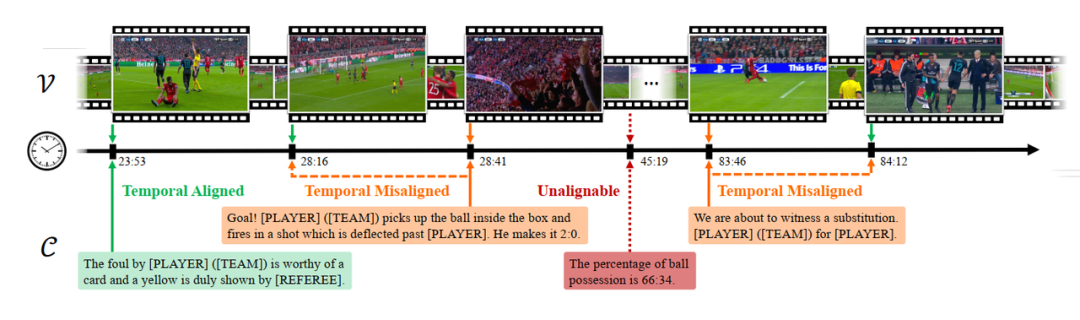
本文围绕MatchTime英文的两种释义解决目前足球领域视频理解的两方面问题,从而实现更好的足球解说:
- 对齐时间戳
大量视频与文本的精确对应是多模态模型学习理解视频的基础。然而,观察到现有足球解说数据集中普遍存在视频文本时序不对齐问题,远无法达到训练所需的精准水平。此研究首先对部分比赛的解说时间戳进行手动标注,构建了一个精准的的足球比赛解说生成基准测试集SN-Caption-test-align。并在此基础上,提出了一个多模态时序对齐流水线,实现对现有数据集自动校正和过滤,生成高质量的足球解说数据集 MatchTime。
- 比赛期间解说
此研究提出了多模态足球解说模型 MatchVoice,在MatchTime优质数据的加持下,讲视频数据进行编码,在对部分编码器和多模态嫁接部分进行训练后,利用冻结的LLM作为解码器,实现了对足球比赛的精准解说生成。该模型利用LLM的推理能力进行轻量化模型训练,结合该研究生成的优质数据,提出了新的足球解说评述基准并实现了足球解说的state-of-the-art效果。
此研究对体育数据集构建提供了新的思路,也展现了AI体育理解领域的发展潜力。
嘉宾介绍

饶珈源,直博二年级@上海交通大学&上海人工智能实验室,导师:谢伟迪。
研究方向为计算机视觉、多模态学习,内容主要聚焦于人工智能在体育领域应用。当前所开展运动项目为足球。个人主页:http://jyrao.github.io
编辑:聂耳聪


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









