






过去的 LLM 在推理时,每一步只能选一个确定的词(比如“苹果”或“香蕉”),就像考试时必须在ABCD中硬选一个答案。这种离散符号的思考方式有两个致命问题:
容易走错路:一旦某一步选错词,后续推理全盘崩坏(比如解题时第一步算错,后面全错);
效率低下:必须像“挤牙膏”一样一步步生成文字,耗时长且算力浪费严重。

论文:Soft Thinking: Unlocking the Reasoning Potential of LLMs in Continuous Concept Space
链接:https://arxiv.org/pdf/2505.15778
而人类的思维更灵活:我们会在脑中模糊地考虑多种可能性(比如同时想到“苹果、水果、红色”),最后再整理成语言。论文指出,学会这种“模糊思考”才是突破的关键。
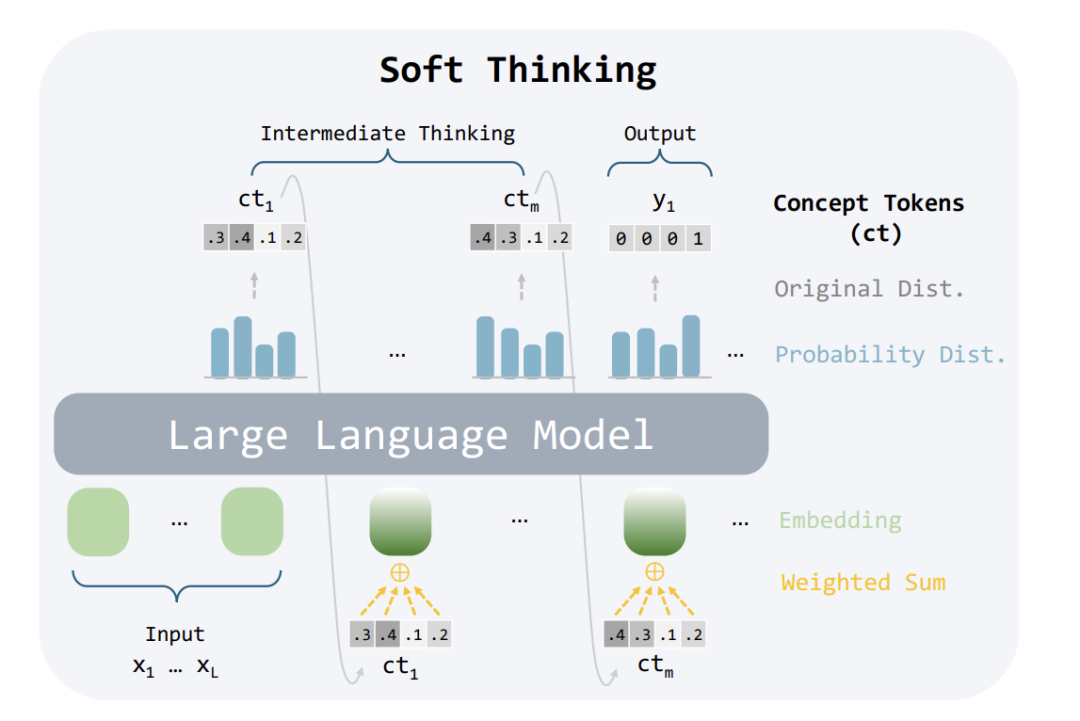
软思考:让LLM学会“模糊推理”
论文提出的Soft Thinking方法,核心是用“概念标记”替代传统词汇。
概念标记是什么?
每个推理步骤不再是某个具体词,而是所有可能词的概率混合体。例如,在思考“水果”时,可能同时包含“苹果(30%)、香蕉(20%)、红色(15%)……”的混合概念。数学公式解析
假设词表有10万个词,每个词的嵌入向量是 ,概率分布是 ,则“概念标记”的嵌入值为:
翻译一下:把10万个词按概率高低“加权平均”,生成一个代表模糊概念的新向量。
这种方法让LLM在推理时保留所有可能性,像人类一样“边想边调整”,避免过早锁定错误答案。
防崩溃:Cold Stop机制
但问题来了:如果LLM在模糊思考中“迷路”了怎么办?比如一直循环“红色→苹果→水果→红色……”停不下来。 论文设计了Cold Stop机制:
熵(Entropy):衡量“纠结程度”。熵值低=很自信,熵值高=在犹豫。
动态停止:当连续几步都高度自信(熵值低于阈值),就提前结束推理,直接输出答案。
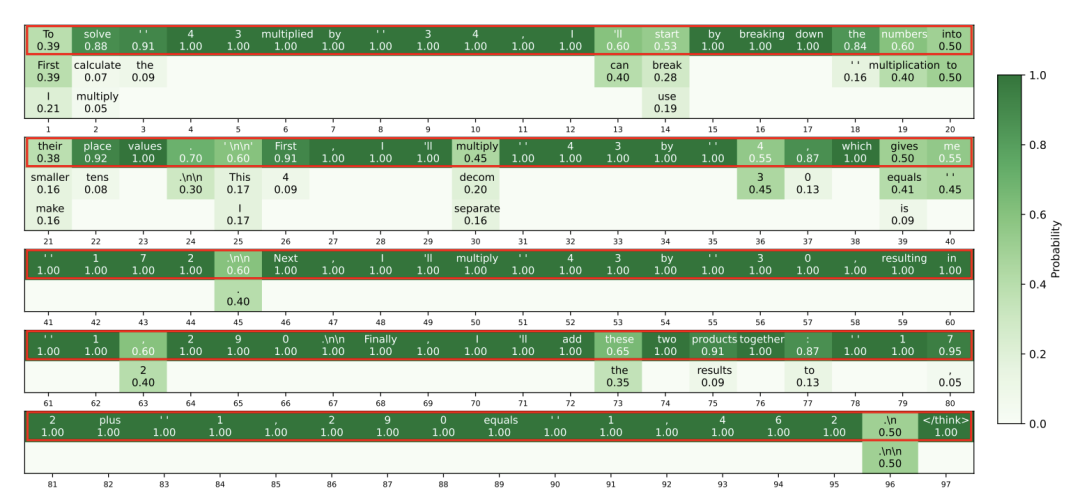
实验:又快又准,鱼与熊掌兼得
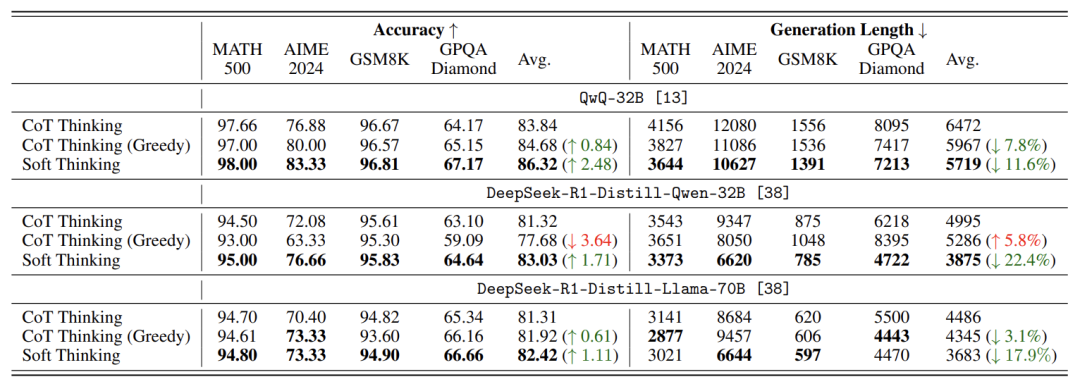
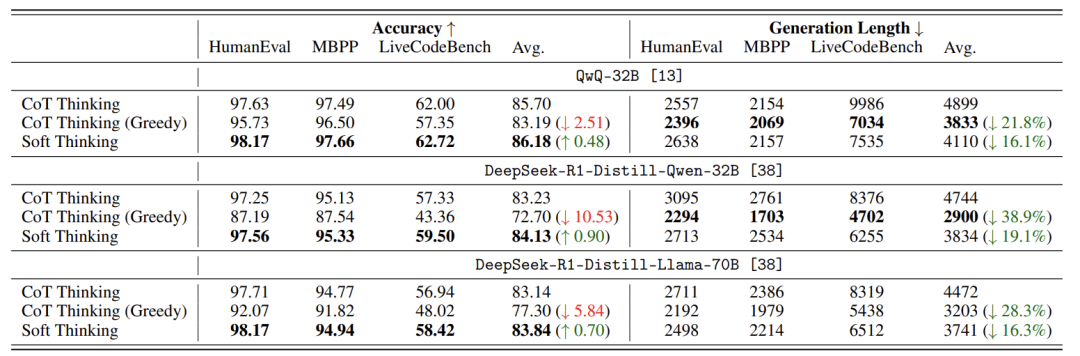
论文在数学题和编程题上测试,结果惊艳:
准确率提升:数学题平均正确率最高涨2.48%(如从83.8%→86.3%),编程题也有小幅提升;
效率飙升:生成答案所需的计算量(token数)减少22.4%,相当于跑车换赛道还省油。
更厉害的是,软思考的答案更简洁。例如同一道题,传统方法需要157个token,而软思考只用96个,且逻辑更清晰。
谈下研究意义
这项研究的意义远超论文本身:无需额外训练,现有模型直接可用;AI的思考过程会更接近人类,更容易被理解。
总之,很有意思的一个研究,值得阅读原文。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









