






 这篇博客是Spark RDD编程的指南,涵盖了Spark概述、链接、初始化、Shell、RDD概念、本地模式与集群模式、Transformations和Actions算子、RDD的持久性和去持久化等内容。介绍了Spark应用程序的结构,RDD作为并行操作的容错数据集,以及如何创建、操作和管理RDD,强调了RDD的持久化在提升性能中的关键作用。
这篇博客是Spark RDD编程的指南,涵盖了Spark概述、链接、初始化、Shell、RDD概念、本地模式与集群模式、Transformations和Actions算子、RDD的持久性和去持久化等内容。介绍了Spark应用程序的结构,RDD作为并行操作的容错数据集,以及如何创建、操作和管理RDD,强调了RDD的持久化在提升性能中的关键作用。
一.概述
在较高级别上,每个Spark应用程序都包含一个驱动程序,该程序运行用户的main功能并在集群上执行各种并行操作。Spark提供的主要抽象是弹性分布式数据集(RDD),它是跨集群节点划分的元素的集合,可以并行操作。通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的文件或驱动程序中现有的Scala集合开始,并进行转换来创建RDD。用户还可以要求Spark将RDD 保留在内存中,以使其能够在并行操作中有效地重用。最后,RDD自动从节点故障中恢复。
Spark中的第二个抽象是可以在并行操作中使用的共享变量。默认情况下,当Spark作为一组任务在不同节点上并行运行一个函数时,它会将函数中使用的每个变量的副本传送给每个任务。有时,需要在任务之间或任务与驱动程序之间共享变量。Spark支持两种类型的共享变量:广播变量(可用于在所有节点上的内存中缓存值)和累加器(accumulator),这些变量仅被“添加”到其上,例如计数器和总和。
二.Spark 链接
默认情况下,Spark 2.4.5已构建并分发为与Scala 2.12一起使用。(也可以将Spark构建为与其他版本的Scala一起使用。)要在Scala中编写应用程序,您将需要使用兼容的Scala版本(例如2.12.X)。
要编写Spark应用程序,您需要在Spark上添加Maven依赖项。可通过Maven Central在以下位置获得Spark:
groupId = org.apache.spark
artifactId = spark-core_2.12
version = 2.4.5
另外,如果您想访问HDFS群集,则需要hadoop-client为您的HDFS版本添加依赖项 。
groupId = org.apache.hadoop
artifactId = hadoop-client
version = <your-hdfs-version>
最后,您需要将一些Spark类导入到程序中。添加以下行:
1.Spark1.x
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
2.Spark2.x
import org.apache.spark.sql.SparkSession
备注:在Spark 1.3.0之前,需要显式import org.apache.spark.SparkContext._启用必要的隐式转换。
三.初始化Spark
Spark程序必须做的第一件事是创建一个SparkContext/SparkSession对象,该对象告诉Spark如何访问集群。要创建一个SparkContext您首先需要构建一个SparkConf对象【SparkSession中不是必须】,其中包含有关您的应用程序的信息。
每个JVM只能激活一个SparkContext/SparkSession。在创建新的SparkContext/SparkSession之前,必须先stop()之前激活的。
val conf = new SparkConf().setAppName(appName).setMaster(master)
val sc = new SparkContext(conf)
val spark = SparkSession.builder().master("local[2]").appName(s"${this.getClass.getSimpleName}").getOrCreate()
该appName参数是您的应用程序显示在集群UI上的名称。 master是Spark,Mesos或YARN群集URL或特殊的“本地”字符串,以本地模式运行。实际上,当在集群上运行时,将不希望master在程序中进行硬编码,而是在其中启动应用程序spark-submit并在其中接收。但是,对于本地测试和单元测试,您可以传递“ local”以在内部运行Spark。
四.Shell
在Spark Shell中,已经在名为的变量中为您创建了一个特殊的可识别解释器的SparkContext sc。制作自己的SparkContext将不起作用。可以使用–master参数设置上下文连接到哪个主机,还可以通过将逗号分隔的列表传递给参数来将JAR添加到类路径–jars。还可以通过在–packages参数中提供逗号分隔的Maven坐标列表,从而将依赖项(例如Spark Packages)添加到Shell会话中。可能存在依赖项的任何其他存储库(例如Sonatype)都可以传递给–repositories参数。例如,要bin/spark-shell在四个核心上运行,请使用:
$ ./bin/spark-shell --master local[4]
或者,也可以添加code.jar到其类路径中,使用:
$ ./bin/spark-shell --master local[4] --jars code.jar
要使用Maven坐标包含依赖项,请执行以下操作:
$ ./bin/spark-shell --master local[4] --packages "org.example:example:0.1"
有关选项的完整列表,请运行spark-shell --help。在后台, spark-shell调用更通用的spark-submit脚本。
五.RDD
Spark围绕弹性分布式数据集(RDD)的概念展开,RDD是可并行操作的元素的容错集合。创建RDD的方法有两种:并行化 驱动程序中的现有集合,或引用外部存储系统(例如共享文件系统,HDFS,HBase或提供Hadoop InputFormat的任何数据源)中的数据集。
1.并行集合
通过在驱动程序(Scala )中的现有集合上调用SparkContext的parallelize方法来创建并行集合Seq。复制集合的元素以形成可以并行操作的分布式数据集。例如,以下是创建包含数字1到5的并行化集合的方法:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
创建后,分布式数据集(distData)可以并行操作。例如,我们可能会调用distData.reduce((a, b) => a + b)以添加数组的元素。
并行集合的一个重要参数是将数据集切入的分区数【也称分片数】。Spark将为集群的每个分区运行一个任务。通常,群集中的每个CPU都需要2-4个分区。通常,Spark会尝试根据集群自动设置分区数。但是,也可以通过将其作为第二个参数传递给parallelize(例如sc.parallelize(data, 10))来手动设置它。
2.外部数据源
Spark可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统,HDFS,Cassandra,HBase,Amazon S3等。Spark支持文本文件,SequenceFiles和任何其他Hadoop InputFormat。
可以使用SparkContext的textFile方法创建文本文件RDD 。此方法需要一个URI的文件(本地路径的机器上,或一个hdfs://,s3a://等URI),并读取其作为行的集合。这是一个示例调用:
scala> val distFile = sc.textFile("data.txt")
distFile: org.apache.spark.rdd.RDD[String] = data.txt MapPartitionsRDD[10] at textFile at <console>:26
一旦创建,distFile就可以通过数据集操作对其进行操作。例如,可以使用map和reduce操作将所有行的大小相加,如下所示:
distFile.map(s => s.length).reduce((a, b) => a + b)
关于使用Spark读取文件的一些注意事项:
- 如果在本地文件系统上使用路径,则还必须在工作节点上的相同路径上访问该文件。将文件复制到所有工作服务器,或者使用网络安装的共享文件系统。
- Spark的所有基于文件的输入方法(包括textFile)都支持在目录,压缩文件和通配符上运行。例如,可以使用:
textFile("/my/directory")
textFile("/my/directory/*.txt")
textFile("/my/directory/*.gz")
- 该textFile方法还采用可选的第二个参数来控制文件的分区数。默认情况下,Spark为文件的每个块创建一个分区(HDFS中的块默认为128MB),但是也可以通过传递更大的值来请求更大数量的分区。请注意,分区不能少于块。
除了文本文件,Spark的Scala API还支持其他几种数据格式:
- SparkContext.wholeTextFiles可以读取包含多个小文本文件的目录,并将每个小文本文件作为(文件名,内容)对返回。与相比textFile,会在每个文件的每一行返回一条记录。分区由数据局部性决定,在某些情况下,数据局部性可能导致分区太少。对于这些情况,wholeTextFiles提供一个可选的第二个参数来控制最小数量的分区。
- 对于SequenceFiles,请使用SparkContext的sequenceFile[K, V]方法,其中K和V是文件中键和值的类型。这些应该是Hadoop的Writable接口的子类,例如IntWritable和Text。此外,Spark允许您为一些常见的可写对象指定本机类型。例如,sequenceFile[Int, String]将自动读取IntWritables和Texts。
- 对于其他Hadoop InputFormat,可以使用该SparkContext.hadoopRDD方法,该方法采用任意JobConf输入格式类,键类和值类。使用与使用输入源进行Hadoop作业相同的方式设置这些内容。还可以SparkContext.newAPIHadoopRDD基于“新” MapReduce API(org.apache.hadoop.mapreduce)将其用于InputFormats 。
- RDD.saveAsObjectFile和SparkContext.objectFile支持以包含序列化Java对象的简单格式保存RDD。尽管它不如Avro这样的专用格式有效,但它提供了一种保存任何RDD的简便方法。
3.RDD操作
RDD支持两种类型的操作:转换(从现有操作中创建新数据集)和动作(action),在对数据集执行计算后,将值返回给驱动程序。例如,map是一个转换,该转换将每个数据集元素都传递给一个函数,并返回代表结果的新RDD。另一方面,这reduce是一个使用某些函数聚合RDD的所有元素并将最终结果返回到驱动程序的操作(尽管也有并行操作reduceByKey返回了分布式数据集)。
Spark中的所有转换都是惰性的,因为它们不会立即计算出结果。相反,他们只记得应用于某些基本数据集(例如文件)的转换。仅当动作要求将结果返回给驱动程序时才计算转换。这种设计使Spark可以更高效地运行。例如,我们可以认识到通过创建的数据集map将在中使用,reduce并且仅将结果返回reduce给驱动程序,而不是将较大的映射数据集返回给驱动程序。
默认情况下,每次在其上执行操作时,可能都会重新计算每个转换后的RDD。但是,您也可以使用(或)方法将RDD 保留在内存中,在这种情况下,Spark会将元素保留在群集中,以便下次查询时可以更快地进行访问。还支持将RDD持久存储在磁盘上,或在多个节点之间复制。
六.本地模式与集群模式
为了执行作业,Spark将RDD操作的处理分解为任务,每个任务都由执行程序执行。在执行之前,Spark计算任务的闭包。闭包是执行者在RDD上执行其计算时必须可见的那些变量和方法。此闭包被序列化并发送给每个执行器。
发送给每个执行程序的闭包中的变量都是副本,因此,在函数中引用计数器时foreach,它不再是驱动程序节点上的计数器。驱动程序节点的内存中仍然存在一个计数器,但是执行者将不再看到该计数器!执行者仅从序列化闭包中看到副本。因此,由于对计数器的所有操作都引用了序列化闭包内的值,所以计数器的最终值仍将为零。
在本地模式下,在某些情况下,该foreach函数实际上将在与驱动程序相同的JVM中执行,并且将引用相同的原始计数器,并且实际上可能会对其进行更新。
为确保在此类情况下行为明确,应使用Accumulator。Spark中的累加器专门用于提供一种机制,用于在集群中的各个工作节点之间拆分执行时安全地更新变量。本指南的“累加器”部分将详细讨论这些内容。
通常,闭包-像循环或局部定义的方法之类的结构,不应用于突变某些全局状态。Spark不定义或保证从闭包外部引用的对象的突变行为。某些执行此操作的代码可能会在本地模式下工作,但这只是偶然的情况,此类代码在分布式模式下将无法正常运行。如果需要一些全局聚合,请使用累加器。
七.Transformations算子
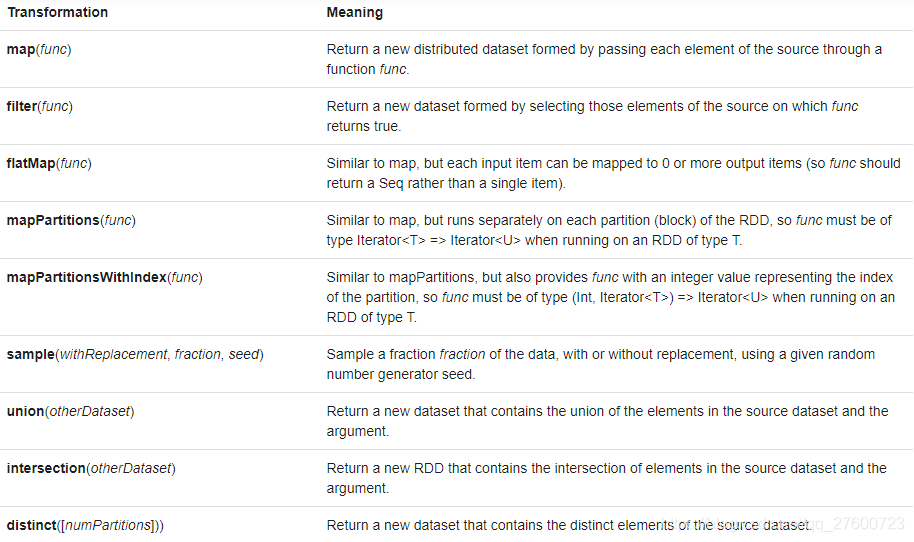
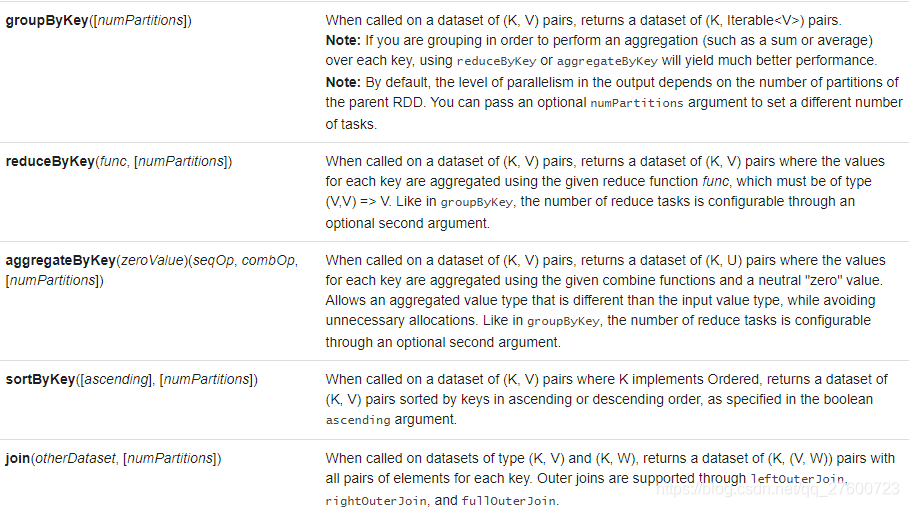

八.Actions算子
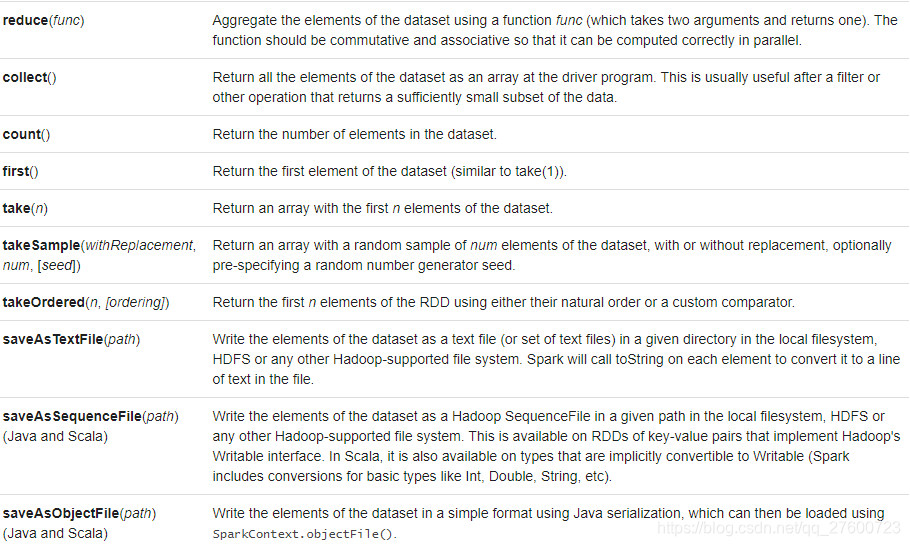

九.RDD持久性
Spark中最重要的功能之一是跨操作将数据集持久化(或缓存)在内存中。当保留RDD时,每个节点都会将其计算的所有分区存储在内存中,并在该数据集(或从该数据集派生的数据集)上的其他操作中重用它们。这样可以使以后的操作更快(通常快10倍以上)。缓存是用于迭代算法和快速交互使用的关键工具。
可以使用persist()或cache()方法将RDD标记为要保留。第一次在操作中对其进行计算时,它将被保存在节点上的内存中。Spark的缓存是容错的-如果RDD的任何分区丢失,它将使用最初创建它的转换自动重新计算。
此外,每个持久化的RDD可以使用不同的存储级别进行存储,例如,允许将数据集持久化在磁盘上、持久化在内存中或作为序列化的Java对象(以节省空间)在节点之间复制。通过将一个StorageLevel对象(Scala, Java, Python)传递给来设置这些级别 persist()。该cache()方法是使用默认存储级别StorageLevel.MEMORY_ONLY(将反序列化的对象存储在内存中)的简写。完整的存储级别集是:

注意: 在Python中,存储的对象将始终使用Pickle库进行序列化,因此,是否选择序列化级别都无关紧要。Python中的可用存储级别包括MEMORY_ONLY,MEMORY_ONLY_2, MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY,和DISK_ONLY_2。
reduceByKey即使没有用户调用,Spark也会自动将某些中间数据保留在随机操作中(例如)persist。这样做是为了避免在混洗期间节点发生故障时重新计算整个输入。我们仍然建议用户persist如果打算重复使用它,请调用生成的RDD。
Spark的存储级别旨在在内存使用率和CPU效率之间提供不同的权衡。建议通过以下过程选择一个:
- 如果RDD与默认的存储级别(MEMORY_ONLY)相称,请保持这种状态。这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行。
- 如果不是,请尝试使用MEMORY_ONLY_SER并选择一个快速的序列化库,以使对象的空间效率更高,但仍可以快速访问【Java和Scala】。
- 除非用于计算数据集的代价很昂贵或数据量过大,否则不建议保存到磁盘上。否则,重新计算分区可能与从磁盘读取分区一样快。
- 如果要快速恢复故障,请使用复制的存储级别(例如,如果使用Spark来处理来自Web应用程序的请求)。所有存储级别都通过重新计算丢失的数据来提供完全的容错能力,但是复制的存储级别可以继续在RDD上运行任务,而不必等待重新计算丢失的分区。
十.RDD去持久化
Spark自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)的方式丢弃旧的数据分区。如果要手动删除RDD而不是等待它脱离缓存,请使用该RDD.unpersist()方法。

















 1297
1297

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









