







 过拟合在机器学习中指模型过于复杂,导致对训练数据过度拟合,影响预测性能。增加数据量和运用正规化如L1/L2正则化、交叉验证等方法能有效防止过拟合。过拟合模型在训练数据上表现好,但对新数据可能误差高。了解训练误差与验证误差的关系有助于识别并避免过拟合。
过拟合在机器学习中指模型过于复杂,导致对训练数据过度拟合,影响预测性能。增加数据量和运用正规化如L1/L2正则化、交叉验证等方法能有效防止过拟合。过拟合模型在训练数据上表现好,但对新数据可能误差高。了解训练误差与验证误差的关系有助于识别并避免过拟合。
在统计学和机器学习中,overfitting一般在描述统计学模型随机误差或噪音时用到。它通常发生在模型过于复杂的情况下,如参数过多等。overfitting会使得模型的预测性能变弱,并且增加数据的波动性。
看下图:

绿线表示overfitting的模型,黑线表示正则化模型。虽然绿线最符合训练数据,但它太依赖于它,并且与黑线相比,新的未看见的数据可能具有更高的错误率。说白了, 就是机器学习模型于自信。 已经到了自负的阶段了。说到自负的坏处, 就是在自己的小圈子里表现非凡, 不过在现实的大圈子里却往往处处碰壁。所以在这里可以自负和过拟合画上等号。
underfitting 发生在统计模型和机器学习算法无法捕获数据的基本趋势时例如:当拟合一个线性模型到非线性数据时。就会发生underfitting,模型的预测性能就会很差了。
下图就是欠 - 均衡 - 过 拟合的对比图。
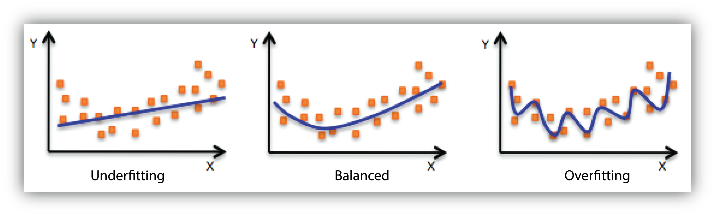
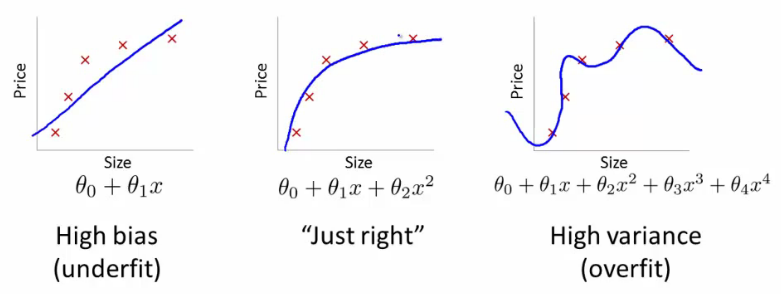
如何避免过拟合
增加数据量, 大部分过拟合产生的原因是因为数据量太少了.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









