










1前言
1.1 数据介绍
最近公司在推进一个项目,刚好自己在负责数据探索的部分,现在项目结束,将数据脱敏,总结一下当时的处理过程~
- 现在外部数据源提供了如下的数据:
 - 数据解释:每一条记录代表了一个用户的标签,从该用户手机app安装的记录及使用情况对用户进行了一个画像。
- 数据解释:每一条记录代表了一个用户的标签,从该用户手机app安装的记录及使用情况对用户进行了一个画像。
1.2 我们为什么要引入上面的外部数据源?
因为部分低活的用户标签不完善,无法起到精准推荐的作用,希望能够引入外部数据源,补充用户的标签,具体能达到两个方面的目的:
- 一方面补充用户的标签维度
- 一方面进行联动的推送相应内容
1.3 那我们该怎么去做?
两种思路:
- 一种思路是对一个用户对应文本描述中提取出关键词,根据关键词去补充用户标签,但这样可能无法直观看到类似的人群
- 另一种思路则是将每一个用户的描述看成一篇文档,所有的用户组成所有文档,运用LDA主题模型去探究隐藏在背后的主题,然后根据得出的结果去和业务人员沟通,看几类主题的可解释性如何,如果ok,再去反定位到每一篇文档,即每一个用户对应的主题的概率,运用软分类即可确定每一位用户的主题!这样我们的目的就完美实现啦~
2 读入数据
import pandas as pd
df = df[['device_uuid', '标签']]
df.head()
| device_uuid | 标签 | |
|---|---|---|
| 0 | CQk5NTM4ZTg3MzhhZDYxNjBmCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... |
| 1 | CQlhNWY2YWVjODFhYWNjOTFjCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... |
| 2 | CQkxY2M4MTMyMDgxMjhhMzljCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... |
| 3 | CQlmNWNkY2U0NDM2MTBjYjkyCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... |
| 4 | CQliY2U2OGM0ODUxZDdkNDEJMDgxNWY4OWI1NjIwMWUwNA... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... |
3分词处理
填坑总结:
- 一开始进行分词的时候直接就是使用结巴分词,但还应该考虑两方面的内容:
- 一个是增加停用词,即如果出现这些词就删去,比如的,标点符号等等。
- 另一个则是自定义词典,不同的业务场景会对应不一样的词典,比如这个外部数据源就会有“打车出行”等专有词汇,如果不加入词典就会分成“打车”“出行”两个词汇,所以下面分词部分也会着重说下这两块如何去做!
3.1 先原始分词
import jieba
def chinese_word_cut(mytext):
return " ".join(jieba.cut(mytext))
chinese_word_cut(df['标签'][0])
Building prefix dict from the default dictionary ...
Loading model from cache /var/folders/vx/np6lccw52hdfcz_2qswpfhch0000gn/T/jieba.cache
Loading model cost 0.682 seconds.
Prefix dict has been built succesfully.
'女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 , 0 - 6 岁 小孩 父母 , 0 - 14 岁 小孩 父母 , 消费水平 _ 高 , 已婚 , 白领 , 大陆 , 二线 城市 , 异性恋 , 有车 , 金融 理财 , 投资 理财 , 投资 理财 - 低 , 记账 , 记账 - 低 , 银行 , 银行 - 中 , 信用卡 , 信用卡 - 高 , 购物 , 网购 , 网购 - 高 , 海淘 , 海淘 - 低 , 团购 , 团购 - 低 , 新闻 阅读 , 新闻资讯 , 新闻 · 资讯 - 高 , 影音 , 电视直播 , 电视直播 - 中 , 在线视频 , 在线视频 - 低 , 在线音乐 , 在线音乐 - 低 , 聊天 社交 , 聊天 , 聊天 - 低 , 生活 服务 , 搬家 , 运动 健康 , 健康 医疗 , 健康 医疗 - 低 , 图像 , 拍摄 美化 , 拍摄 美化 - 低 , 丽人 母婴 , 美容 美妆 , 美容 美妆 - 中 , 生活 实用 , 打车 出行 , 打车 出行 - 低 , 地图 导航 , 地图 导航 - 低 , 天气 查询 , 天气 查询 - 中 , 效率 办公 , 存储 云盘 , 存储 云盘 - 低 , 游戏 , 经营策略 , 数码科技 _ 综合 科技 , 数码科技 _ 手机 , 数码科技 _ 电脑 , 数码科技 _ 数码产品 , 汽车 交通 _ 汽车 综合 资讯 , 三星 , 中国移动 , 中文 简体 , 居住地 _ 山西省 , 居住地 _ 太原市 , 家乡 _ 太原市'
- 可以看到,有些专有的词汇我是不想让其分开的,比如“打车出行”,“美容美妆”。
- 另外逗号我们是不希望有的
3.2 引入常见停用词
list_100 = list(range(100))
list_100_str = list(map(lambda x: str(x), list_100))
list_100_str[:10]
['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
#从文件导入停用词表
stpwrdpath = "stop_words.txt"
stpwrd_dic = open(stpwrdpath, encoding='gbk') # 加上编码,不然就不会显示中文了!
stpwrd_content = stpwrd_dic.read()
# print(stpwrd_content)
#将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
# 在停用词里面再把年龄 也就是具体的数字全部去掉 所以停用词加上0-100的数字!【为什么呢?因为单独提取出了年龄】
stpwrdlst = stpwrdlst + list_100_str # 先测试这一版 如果不对 就要把数字变成字符[修改了!]
print(stpwrdlst[:5]) # 看前五个停用词是啥
stpwrd_dic.close()
[',', '?', '、', '。', '“']
def word_cut(mytext):
return " ".join(x for x in jieba.cut(mytext) if x not in stpwrdlst)
word_cut(df['标签'][0])
'女 岁 父母 岁 小孩 父母 妈妈 母婴 岁 小孩 父母 岁 小孩 父母 消费水平 高 已婚 白领 大陆 二线 城市 异性恋 有车 金融 理财 投资 理财 投资 理财 低 记账 记账 低 银行 银行 中 信用卡 信用卡 高 购物 网购 网购 高 海淘 海淘 低 团购 团购 低 新闻 阅读 新闻资讯 新闻 资讯 高 影音 电视直播 电视直播 中 在线视频 在线视频 低 在线音乐 在线音乐 低 聊天 社交 聊天 聊天 低 生活 服务 搬家 运动 健康 健康 医疗 健康 医疗 低 图像 拍摄 美化 拍摄 美化 低 丽人 母婴 美容 美妆 美容 美妆 中 生活 实用 打车 出行 打车 出行 低 地图 导航 地图 导航 低 天气 查询 天气 查询 中 效率 办公 存储 云盘 存储 云盘 低 游戏 经营策略 数码科技 综合 科技 数码科技 手机 数码科技 电脑 数码科技 数码产品 汽车 交通 汽车 综合 资讯 三星 中国移动 中文 简体 居住地 山西省 居住地 太原市 家乡 太原市'
总结:可以看到一些停用词就被剔除了,完美!但是一般这个停用词在LDA模型中不是这里使用哈,而是在后面搭建LDA模型的时候—关键词提取和向量转换时,进行去除,不过本质都是一样的哈!
3.3 自定义词典
上面的停用词解决了剔除一些我们不想要的字符,那我们如何不去拆解一些我们本就不想去拆分开的字符呢?这时候自定义词典就可以闪亮登场了!
import jieba
jieba.load_userdict('dic_netease.txt')
直接将自定义的词汇粘贴到txt中即可,如果样本量很大,可以通过代码实现,少直接复制粘贴。上面直接导入即可!
现在已经导入了自定义词典了!让我们来看看分词后有什么神奇的效果?
chinese_word_cut(df['标签'][0])
'女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 , 0 - 6 岁 小孩 父母 , 0 - 14 岁 小孩 父母 , 消费水平_高 , 已婚 , 白领 , 大陆 , 二线城市 , 异性恋 , 有车 , 金融理财 , 投资理财 , 投资理财 - 低 , 记账 , 记账 - 低 , 银行 , 银行 - 中 , 信用卡 , 信用卡 - 高 , 购物 , 网购 , 网购 - 高 , 海淘 , 海淘 - 低 , 团购 , 团购 - 低 , 新闻阅读 , 新闻资讯 , 新闻 · 资讯 - 高 , 影音 , 电视直播 , 电视直播 - 中 , 在线视频 , 在线视频 - 低 , 在线音乐 , 在线音乐 - 低 , 聊天社交 , 聊天 , 聊天 - 低 , 生活服务 , 搬家 , 运动健康 , 健康医疗 , 健康医疗 - 低 , 图像 , 拍摄美化 , 拍摄美化 - 低 , 丽人母婴 , 美容美妆 , 美容美妆 - 中 , 生活实用 , 打车出行 , 打车出行 - 低 , 地图导航 , 地图导航 - 低 , 天气查询 , 天气查询 - 中 , 效率办公 , 存储云盘 , 存储云盘 - 低 , 游戏 , 经营策略 , 数码科技 _ 综合科技 , 数码科技 _ 手机 , 数码科技 _ 电脑 , 数码科技 _ 数码产品 , 汽车交通 _ 汽车综合资讯 , 三星 , 中国移动 , 中文简体 , 居住地 _ 山西省 , 居住地 _ 太原市 , 家乡 _ 太原市'
- 可以看到打车出现已经在一起了!完美!自定义词典就是这么干!
3.4 批量对这批数据进行分词处理
df['cut_label'] = df['标签'].map(chinese_word_cut)
df['cut_label'].head()
0 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,...
1 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,...
2 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,...
3 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,...
4 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,...
Name: cut_label, dtype: object
df['cut_label'][0]
'女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 , 0 - 6 岁 小孩 父母 , 0 - 14 岁 小孩 父母 , 消费水平_高 , 已婚 , 白领 , 大陆 , 二线城市 , 异性恋 , 有车 , 金融理财 , 投资理财 , 投资理财 - 低 , 记账 , 记账 - 低 , 银行 , 银行 - 中 , 信用卡 , 信用卡 - 高 , 购物 , 网购 , 网购 - 高 , 海淘 , 海淘 - 低 , 团购 , 团购 - 低 , 新闻阅读 , 新闻资讯 , 新闻 · 资讯 - 高 , 影音 , 电视直播 , 电视直播 - 中 , 在线视频 , 在线视频 - 低 , 在线音乐 , 在线音乐 - 低 , 聊天社交 , 聊天 , 聊天 - 低 , 生活服务 , 搬家 , 运动健康 , 健康医疗 , 健康医疗 - 低 , 图像 , 拍摄美化 , 拍摄美化 - 低 , 丽人母婴 , 美容美妆 , 美容美妆 - 中 , 生活实用 , 打车出行 , 打车出行 - 低 , 地图导航 , 地图导航 - 低 , 天气查询 , 天气查询 - 中 , 效率办公 , 存储云盘 , 存储云盘 - 低 , 游戏 , 经营策略 , 数码科技 _ 综合科技 , 数码科技 _ 手机 , 数码科技 _ 电脑 , 数码科技 _ 数码产品 , 汽车交通 _ 汽车综合资讯 , 三星 , 中国移动 , 中文简体 , 居住地 _ 山西省 , 居住地 _ 太原市 , 家乡 _ 太原市'
4 提取特征
- 现在已经进行了分词处理,但其实从原始的文本数据中我们可以做一些特征的提取,比如年龄,小孩年龄,是否为父母等,而这些特征将会对我们起到一定的辅助作用。
4.1 先从数据中提取出高的标签
使用正则表达式进行提取“高”标签
4.1.1 单个实验
df_demo = df['标签'][0]
df_demo
'女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,消费水平_高,已婚,白领,大陆,二线城市,异性恋,有车,金融理财,投资理财,投资理财-低,记账,记账-低,银行,银行-中,信用卡,信用卡-高,购物,网购,网购-高,海淘,海淘-低,团购,团购-低,新闻阅读,新闻资讯,新闻·资讯-高,影音,电视直播,电视直播-中,在线视频,在线视频-低,在线音乐,在线音乐-低,聊天社交,聊天,聊天-低,生活服务,搬家,运动健康,健康医疗,健康医疗-低,图像,拍摄美化,拍摄美化-低,丽人母婴,美容美妆,美容美妆-中,生活实用,打车出行,打车出行-低,地图导航,地图导航-低,天气查询,天气查询-中,效率办公,存储云盘,存储云盘-低,游戏,经营策略,数码科技_综合科技,数码科技_手机,数码科技_电脑,数码科技_数码产品,汽车交通_汽车综合资讯,三星,中国移动,中文简体,居住地_山西省,居住地_太原市,家乡_太原市'
import re
split=re.compile("[^,]*高")
try:
result=split.findall(df_demo)
except:
result=''
result
['消费水平_高', '信用卡-高', '网购-高', '新闻·资讯-高']
4.1.2 封装函数
import re
def ExtraHigh(s):
split=re.compile("[^,]*高")
try:
result=split.findall(s)
except:
result=''
return result
df['high_label'] = df['标签'].apply(ExtraHigh)
df['high_label'][10:20]
10 [消费水平_高, 商务旅行-高, 爱车-高, 新闻·资讯-高, 电视直播-高]
11 [消费水平_高, 新闻·资讯-高, 听书-高, 在线视频-高, 在线音乐-高]
12 [消费水平_高, 新闻·资讯-高, 天气查询-高]
13 [消费水平_高, 爱车-高, 新闻·资讯-高, 社区-高, 拍摄美化-高]
14 [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高, 婚恋-高, 打车出行-高, 天...
15 [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高, 婚恋-高, 打车出行-高, 天...
16 [消费水平_高, 银行-高, 网购-高, 爱车-高, 新闻·资讯-高, 音乐播放器-高, 视...
17 [消费水平_高, 银行-高, 网购-高, 爱车-高, 新闻·资讯-高, 音乐播放器-高, 视...
18 [消费水平_高, 投资理财-高, 网贷p2p-高, 网购-高, 快递-高, 中小学教育-高,...
19 [消费水平_高, 网购-高, 团购-高, 休闲旅行-高, 新闻·资讯-高, 在线视频-高, ...
Name: high_label, dtype: object
4.2 提取用户年龄
import re
def ExtraAge(s):
split=re.compile("[^,]*岁[,]")
try:
result=split.findall(s)
except:
result=''
return result
ExtraAge(df['标签'][0])
['25-34岁,']
df['age'] = df['标签'].map(ExtraAge)
(df['age'].map(str)).value_counts()
['25-34岁,'] 13712
['18-24岁,'] 5222
['35-44岁,'] 2826
Name: age, dtype: int64
4.3 提取小孩年龄
import re
def ExtraAgeKid(s):
split=re.compile("[^,]*小孩父母")
try:
result=split.findall(s)
if result == []:
result = '无'
except:
result=''
return result
ExtraAgeKid(df['标签'][0])
['0-3岁小孩父母', '0-6岁小孩父母', '0-14岁小孩父母']
df['age_kid'] = df['标签'].map(ExtraAgeKid)
(df['age_kid'].map(str)).value_counts()
无 13757
['0-3岁小孩父母', '0-6岁小孩父母', '0-14岁小孩父母'] 4301
['3-14岁小孩父母', '0-14岁小孩父母'] 2127
['3-6岁小孩父母', '0-6岁小孩父母', '3-14岁小孩父母', '0-14岁小孩父母'] 1504
['0-6岁小孩父母', '3-14岁小孩父母', '0-14岁小孩父母'] 41
['0-6岁小孩父母', '0-14岁小孩父母'] 30
Name: age_kid, dtype: int64
4.4 提取性别
def ExtraSex(x):
return df['标签'][x][:1]
df.index = range(len(df))
df['gender'] = df.index.map(ExtraSex)
print(df['gender'].head())
df['gender'].value_counts()
0 女
1 女
2 女
3 女
4 女
Name: gender, dtype: object
女 10935
男 10825
Name: gender, dtype: int64
5 思路1:使用两种关键词提取方法
关于TF-IDF和TEXT-RANK的具体原理见之前的博客:机器学习 | TF-IDF和TEXT-RANK的区别
from jieba.analyse import *
5.1 TF-IDF
df['cut_label'][0]
'女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 , 0 - 6 岁 小孩 父母 , 0 - 14 岁 小孩 父母 , 消费水平_高 , 已婚 , 白领 , 大陆 , 二线城市 , 异性恋 , 有车 , 金融理财 , 投资理财 , 投资理财 - 低 , 记账 , 记账 - 低 , 银行 , 银行 - 中 , 信用卡 , 信用卡 - 高 , 购物 , 网购 , 网购 - 高 , 海淘 , 海淘 - 低 , 团购 , 团购 - 低 , 新闻阅读 , 新闻资讯 , 新闻 · 资讯 - 高 , 影音 , 电视直播 , 电视直播 - 中 , 在线视频 , 在线视频 - 低 , 在线音乐 , 在线音乐 - 低 , 聊天社交 , 聊天 , 聊天 - 低 , 生活服务 , 搬家 , 运动健康 , 健康医疗 , 健康医疗 - 低 , 图像 , 拍摄美化 , 拍摄美化 - 低 , 丽人母婴 , 美容美妆 , 美容美妆 - 中 , 生活实用 , 打车出行 , 打车出行 - 低 , 地图导航 , 地图导航 - 低 , 天气查询 , 天气查询 - 中 , 效率办公 , 存储云盘 , 存储云盘 - 低 , 游戏 , 经营策略 , 数码科技 _ 综合科技 , 数码科技 _ 手机 , 数码科技 _ 电脑 , 数码科技 _ 数码产品 , 汽车交通 _ 汽车综合资讯 , 三星 , 中国移动 , 中文简体 , 居住地 _ 山西省 , 居住地 _ 太原市 , 家乡 _ 太原市'
5.1.1 不带得分
for keyword in extract_tags(df['cut_label'][0], topK=5): # k可选 也可以选择要不要把得分打出来
print('%s' % (keyword))
数码科技
电视直播
在线视频
父母
投资理财
help(extract_tags)
Help on method extract_tags in module jieba.analyse.tfidf:
extract_tags(sentence, topK=20, withWeight=False, allowPOS=(), withFlag=False) method of jieba.analyse.tfidf.TFIDF instance
Extract keywords from sentence using TF-IDF algorithm.
Parameter:
- topK: return how many top keywords. `None` for all possible words.
- withWeight: if True, return a list of (word, weight);
if False, return a list of words.
- allowPOS: the allowed POS list eg. ['ns', 'n', 'vn', 'v','nr'].
if the POS of w is not in this list,it will be filtered.
- withFlag: only work with allowPOS is not empty.
if True, return a list of pair(word, weight) like posseg.cut
if False, return a list of words
5.1.2 带得分
for keyword, weight in extract_tags(df['cut_label'][0], topK=4, withWeight=True): # k可选 也可以选择要不要把得分打出来
print('%s : %s' % (keyword, weight))
数码科技 : 0.5805507899516483
电视直播 : 0.29027539497582416
在线视频 : 0.29027539497582416
父母 : 0.2807938508703297
5.1.3 批量求解
def ExtrWord(s):
e1 = extract_tags(s, topK=5)
return e1
df['tf_word'] = df['cut_label'].apply(ExtrWord)
df['tf_word'][10:15]
10 [电视直播, 在线视频, 外卖, 投资理财, 网购]
11 [在线视频, 投资理财, 网购, 海淘, 商务旅行]
12 [在线视频, 外卖, 网购, 在线教育, 休闲旅行]
13 [电视直播, 在线视频, 网购, 违章查询, 在线音乐]
14 [金融财经, 在线视频, 外卖, 网购, 休闲旅行]
Name: tf_word, dtype: object
5.2 TEXT-RANK
for keyword, weight in textrank(df['cut_label'][0], topK=5, withWeight=True):
print('%s %s' % (keyword, weight))
数码科技 1.0
父母 0.6121734117319969
电视直播 0.5564012710643426
网购 0.54952782148969
居住地 0.49139059826998766
def TextRank(s):
e1 = textrank(s, topK=5)
return e1
df['tr_word'] = df['cut_label'].map(TextRank)
df['tf_word'][10:15]
10 [电视直播, 在线视频, 外卖, 投资理财, 网购]
11 [在线视频, 投资理财, 网购, 海淘, 商务旅行]
12 [在线视频, 外卖, 网购, 在线教育, 休闲旅行]
13 [电视直播, 在线视频, 网购, 违章查询, 在线音乐]
14 [金融财经, 在线视频, 外卖, 网购, 休闲旅行]
Name: tf_word, dtype: object
6 思路2:使用LDA主题模型
通过上述的工作我们已经完成了关键词的提取,但是还是无法看出这批用户有哪几大类兴趣点,于是LDA模型登场!
6.1 什么是LDA模型?
在机器学习领域,LDA是两个常用模型的简称:
- Linear Discriminant Analysis 线性判别分析【一种降维方法 后面和PCA一起在博客补充】https://www.cnblogs.com/pinard/p/6244265.html
- Latent Dirichlet Allocation。隐含狄利克雷分布
现在讨论的LDA仅指代Latent Dirichlet Allocation. LDA在主题模型中占有非常重要的地位,常用来文本分类。
定义:
- LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
- 作用:寻找多个文档内存在的潜在主题。
- LDA是一种非监督机器学习方法,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
6.2 数学推导
详情见 :
- https://blog.csdn.net/v_JULY_v/article/details/41209515
- https://zhuanlan.zhihu.com/p/31470216
6.3 LDA 中主题数目如何确定?
6.3.1 业务上:手动调参
在 LDA 中,主题的数目没有一个固定的最优解。模型训练时,需要事先设置主题数,根据训练出来的结果,手动调参(原因在于不同业务对于生成topic的要求是存在差异的),要优化主题数目,进而优化文本分类结果。
6.3.2 学术上
- 用perplexity-topic number曲线
- LDA有一个自己的评价标准叫Perplexity(困惑度),可以理解为,对于一篇文档d,我们的模型对文档d属于哪个topic有多不确定,这个不确定程度就是Perplexity。
- 其他条件固定的情况下,topic越多,则Perplexity越小,但是容易过拟合。
-
用topic_number-logP(w|T)曲线
-
基于密度的自适应最优LDA模型选择方法
- 选取初始主题数K值,得到初始模型,计算各topic之间的相似度
- 增加或减少K的值,重新训练得到模型,再次计算topic之间的相似度
- 重复迭代第二步直到得到最优的K
- 利用HDP(层次狄利克雷过程)
6.4 LDA模型的具体实现
df.head()
| device_uuid | 标签 | cut_label | high_label | age | age_kid | gender | |
|---|---|---|---|---|---|---|---|
| 0 | CQk5NTM4ZTg3MzhhZDYxNjBmCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... | 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,... | [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高] | [25-34岁,] | [0-3岁小孩父母, 0-6岁小孩父母, 0-14岁小孩父母] | 女 |
| 1 | CQlhNWY2YWVjODFhYWNjOTFjCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... | 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,... | [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高] | [25-34岁,] | [0-3岁小孩父母, 0-6岁小孩父母, 0-14岁小孩父母] | 女 |
| 2 | CQkxY2M4MTMyMDgxMjhhMzljCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... | 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,... | [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高] | [25-34岁,] | [0-3岁小孩父母, 0-6岁小孩父母, 0-14岁小孩父母] | 女 |
| 3 | CQlmNWNkY2U0NDM2MTBjYjkyCTA4MTVmODliNTYyMDFlMD... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... | 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,... | [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高] | [25-34岁,] | [0-3岁小孩父母, 0-6岁小孩父母, 0-14岁小孩父母] | 女 |
| 4 | CQliY2U2OGM0ODUxZDdkNDEJMDgxNWY4OWI1NjIwMWUwNA... | 女,25-34岁,父母,0-3岁小孩父母,妈妈,母婴,0-6岁小孩父母,0-14岁小孩父母,... | 女 , 25 - 34 岁 , 父母 , 0 - 3 岁 小孩 父母 , 妈妈 , 母婴 ,... | [消费水平_高, 信用卡-高, 网购-高, 新闻·资讯-高] | [25-34岁,] | [0-3岁小孩父母, 0-6岁小孩父母, 0-14岁小孩父母] | 女 |
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
6.4.1 定义提取特征关键词的数量
n_features = 1000
6.4.2 关键词提取和向量转换
tf_vectorizer = CountVectorizer(strip_accents='unicode',
max_features=n_features,
stop_words=stpwrdlst, # 停用词用在这!
max_df=0.5,
min_df=10)
tf = tf_vectorizer.fit_transform(df['cut_label'])
n_topics = 5
lda = LatentDirichletAllocation(n_topics=n_topics,
max_iter=10,
learning_method='online',
learning_offset=50,
random_state=23)
6.4.3 开始进行LDA拟合数据 提取主题
lda.fit(tf)
/Users/apple/anaconda3/lib/python3.6/site-packages/sklearn/decomposition/online_lda.py:314: DeprecationWarning: n_topics has been renamed to n_components in version 0.19 and will be removed in 0.21
DeprecationWarning)
LatentDirichletAllocation(batch_size=128, doc_topic_prior=None,
evaluate_every=-1, learning_decay=0.7,
learning_method='online', learning_offset=50,
max_doc_update_iter=100, max_iter=10, mean_change_tol=0.001,
n_components=10, n_jobs=None, n_topics=5, perp_tol=0.1,
random_state=23, topic_word_prior=None,
total_samples=1000000.0, verbose=0)
6.4.4 定义函数显示每个主题里面前若干个关键词
def print_top_words(model, feature_names, n_top_words):
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
注:函数argsort的补充
作用:argsort函数返回的是数组值从小到大的索引值
import numpy as np
a = np.array([1,3,4,5,7,2,6])
a.argsort()
# 正常排序是1 2 3 4 5 6 7
# 对应的索引是 0 5 1 2 3 6 4
array([0, 5, 1, 2, 3, 6, 4])
n_top_words = 5
tf_feature_names = tf_vectorizer.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)
Topic #0:
美容美妆 数码科技 金融财经 存储云盘 休闲旅行
Topic #1:
娱乐 生活 体育 综合娱乐 科技
Topic #2:
打车出行 休闲旅行 外卖 邮箱 存储云盘
Topic #3:
买车 汽车 爱车 汽车交通 有车
Topic #4:
父母 小孩 育儿社区 美容美妆 团购
6.4.5 可视化展示
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
6.4.6 如何反向定位到每一个人属于哪一个主题
docs = lda.fit_transform(tf)
/Users/apple/anaconda3/lib/python3.6/site-packages/sklearn/decomposition/online_lda.py:314: DeprecationWarning: n_topics has been renamed to n_components in version 0.19 and will be removed in 0.21
DeprecationWarning)
docs
array([[0.47307049, 0.00389658, 0.2138838 , 0.00398295, 0.30516618],
[0.47307049, 0.00389658, 0.2138838 , 0.00398295, 0.30516618],
[0.47307049, 0.00389658, 0.2138838 , 0.00398295, 0.30516618],
...,
[0.1610961 , 0.00255204, 0.25369255, 0.19298993, 0.38966939],
[0.31746614, 0.00457675, 0.27187681, 0.00463559, 0.40144471],
[0.06701105, 0.00546047, 0.44921981, 0.00561896, 0.4726897 ]])
- 列1~列5 对应每一篇文档属于主题1~5的概率
- 现在取一行最大就可以对应一篇文档属于哪个主题的可能性最大
def CalTopic(docs, i):
# docs:训练好的模型拟合原有数据之后 得到每一篇文档对应到不同主题的概率
# i表示文档i
topic_most_pr = docs[i].argmax()
return topic_most_pr
df['topic'] = df.index.map(lambda x: CalTopic(docs, x))
df['topic'].value_counts()
4 7021
2 6744
0 4865
3 2042
1 1088
Name: topic, dtype: int64
注:上述产生的0~4主题可以和下图对应主题对应上!

但是我们还得去做一件事情就是将这个主题和可视化中的图对应上即可!
具体方法见下面
df['topic'] = df['topic'].map(str)
dic_top = {'0':3, '1':5, '2':1, '3':4, '4': 2}
df['topic_pic'] = df['topic'].map(dic_top)
df['topic_pic'].value_counts()
2 7021
1 6744
3 4865
4 2042
5 1088
Name: topic_pic, dtype: int64
6.4.7 结果展示
是一个动态交互的网页结果,但是还没找到很好地方法直接分享链接。
现在分别把每一类主题图片展示:
(注:下图为demo结果,所以样本量可能和上述有差异)
-
主题解释:

现在确定了主题,就可以实现一开始的两个目的: -
一方面补充用户的标签维度
-
一方面定位到不同主题的人群进行联动的推送相应内容
-
主题1:
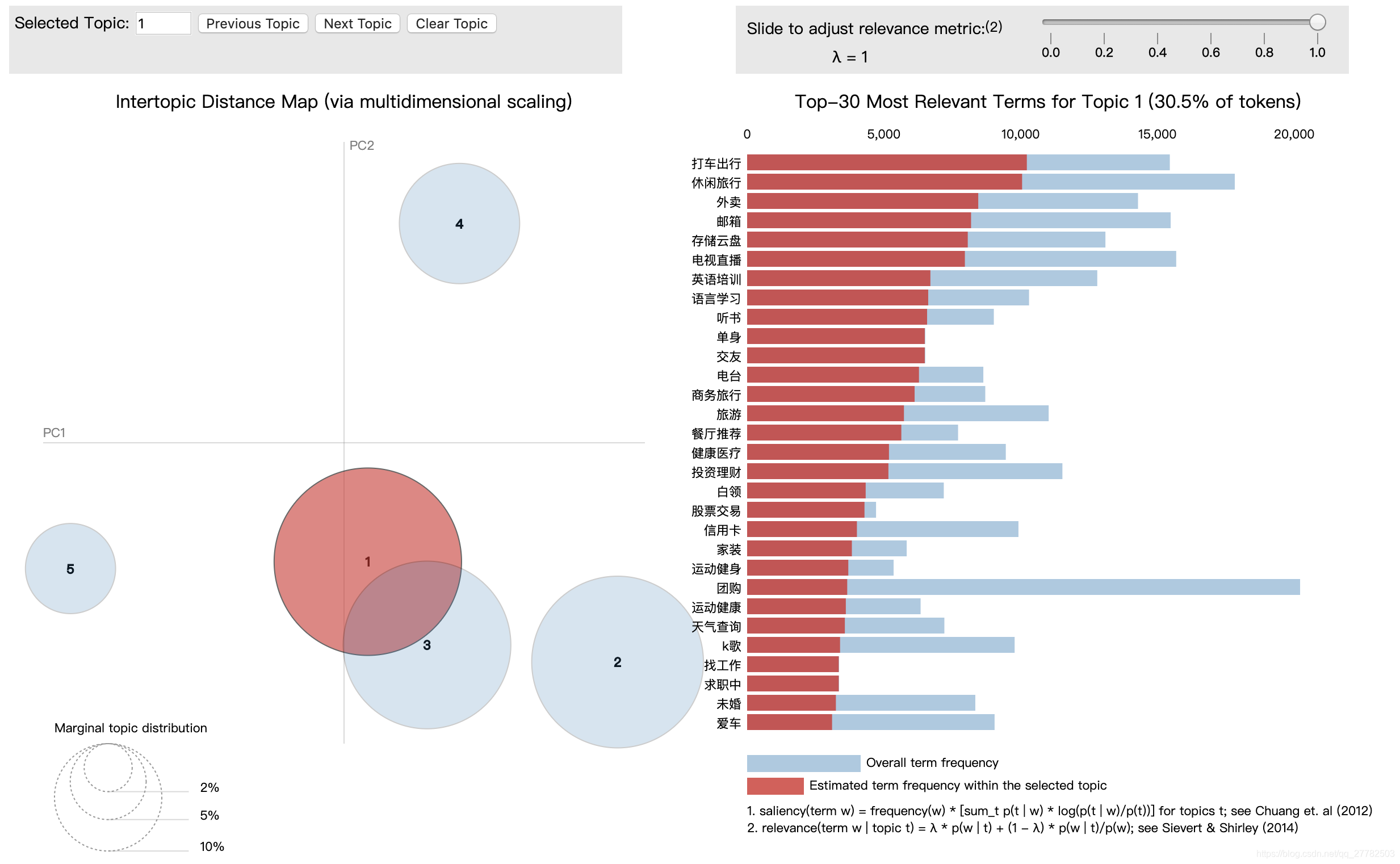
-
主题2:
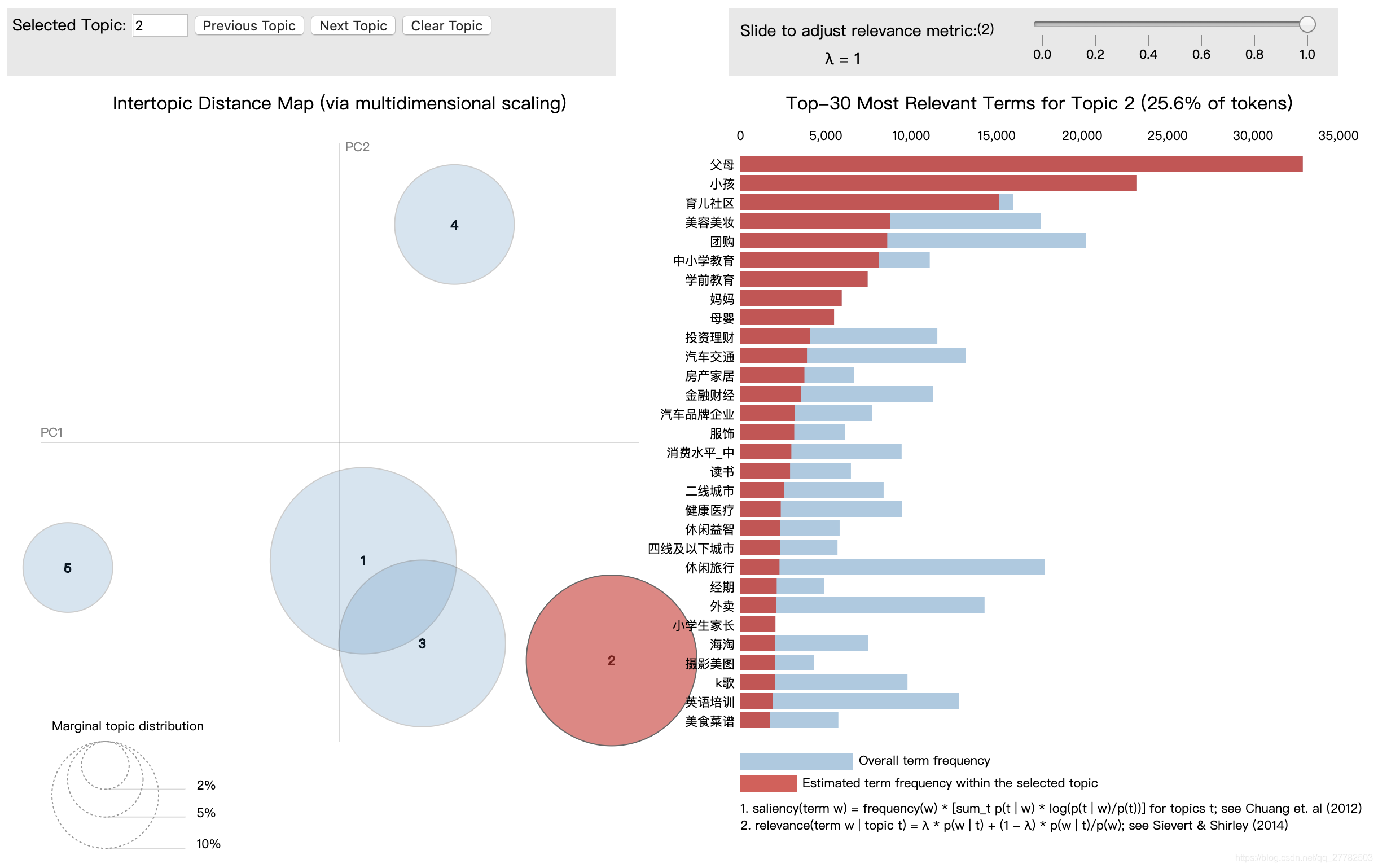
-
主题3:
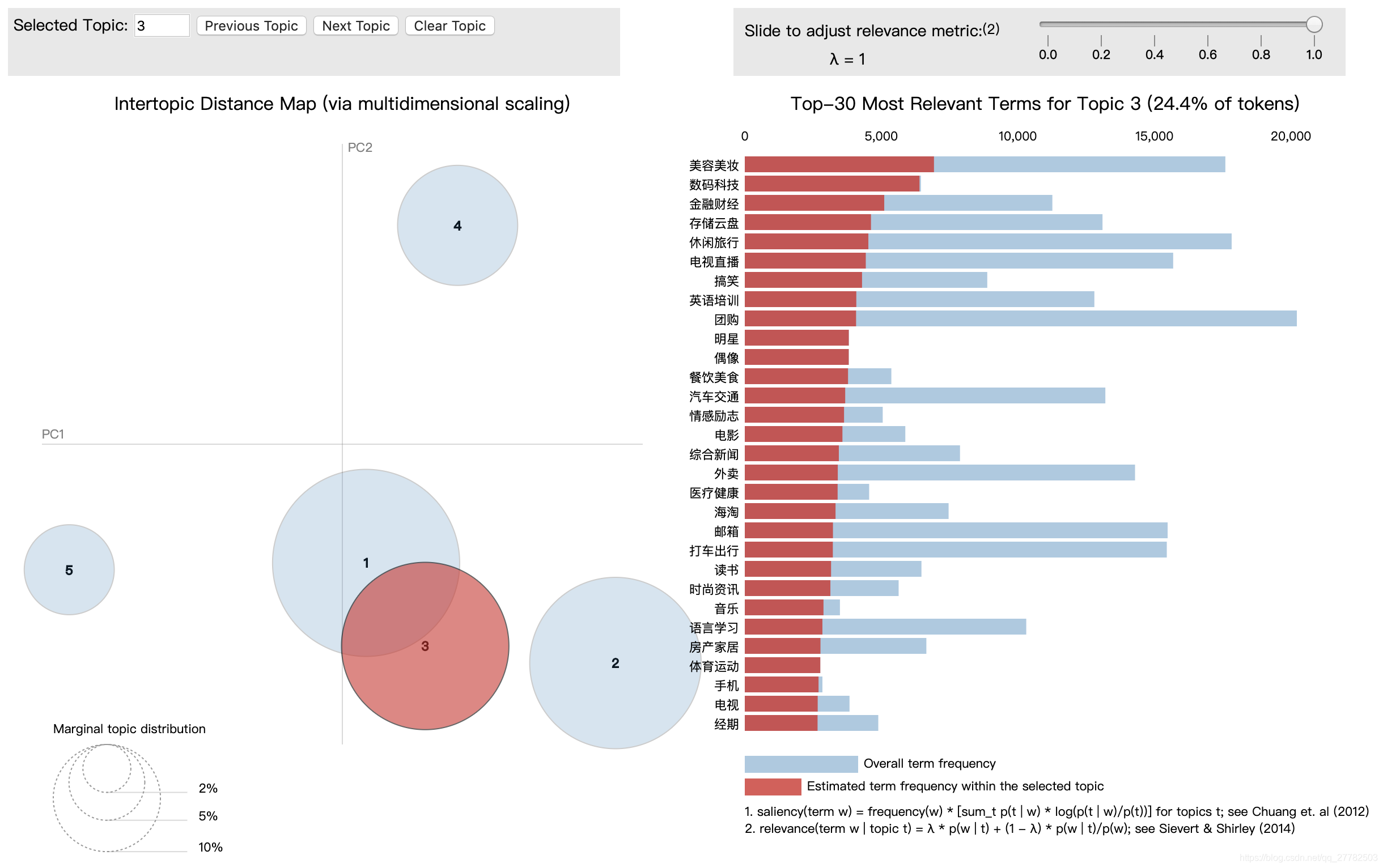
-
主题4:
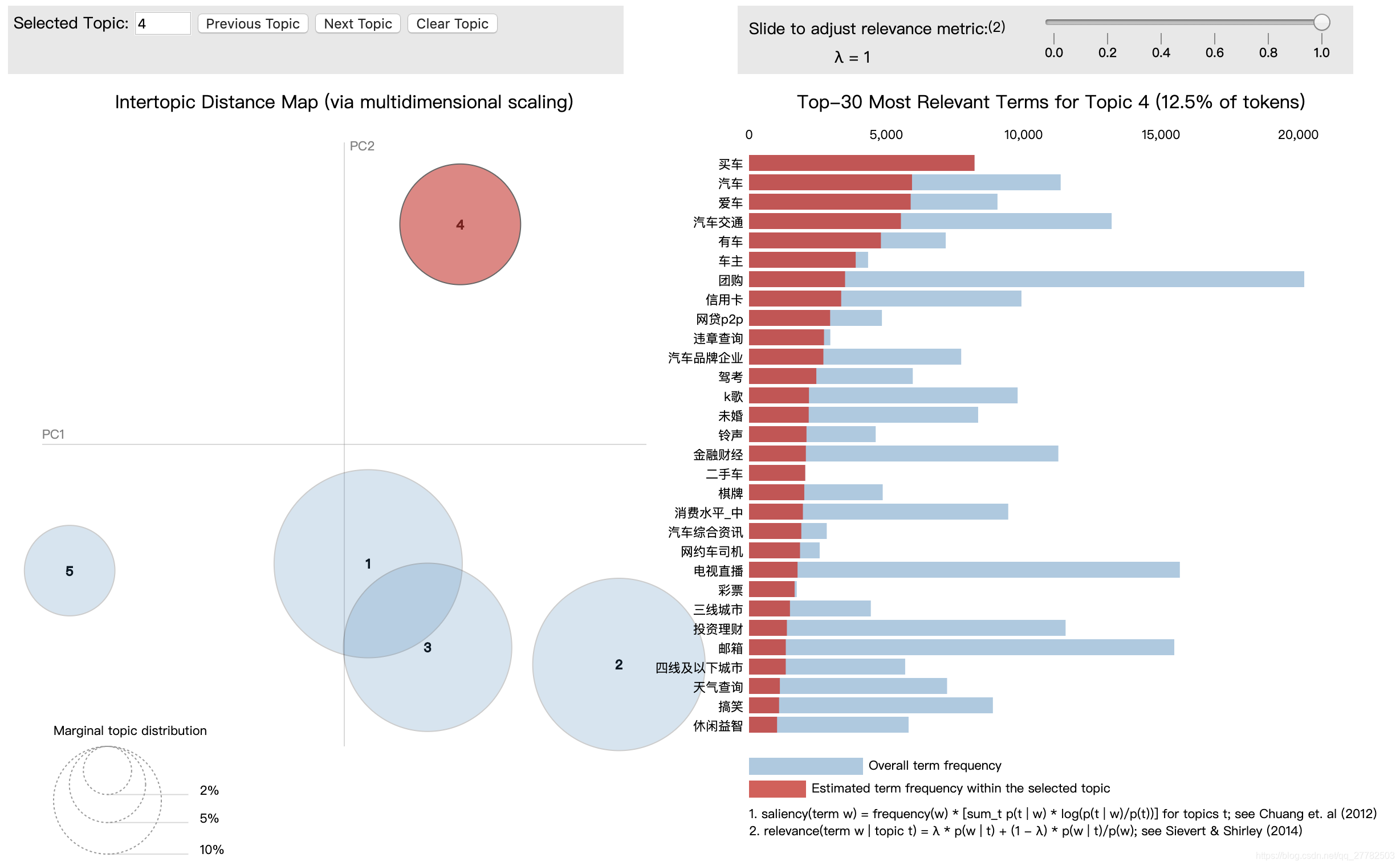
-
主题 5:
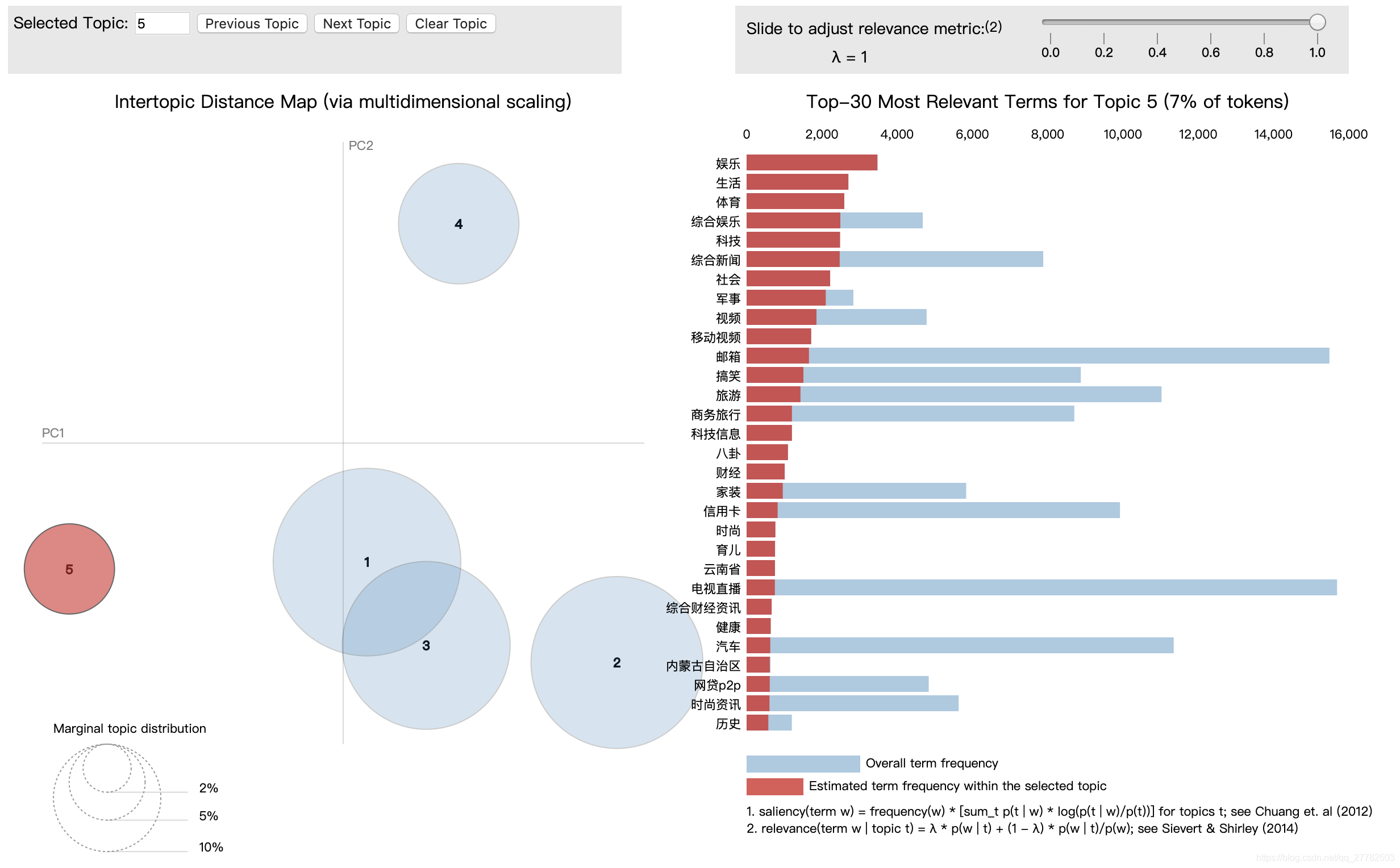
6.4.8 数据探索
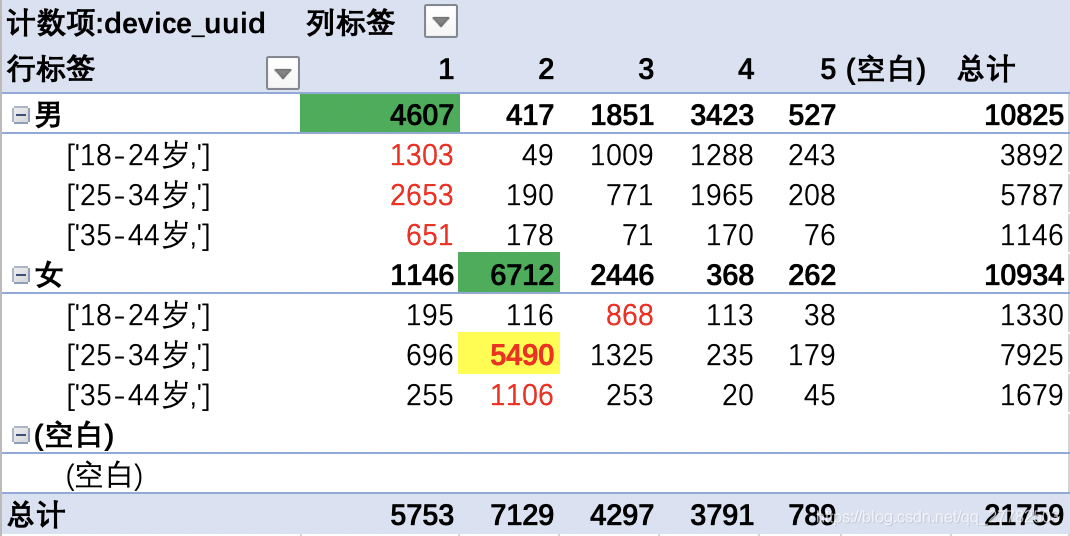
6.5 LDA模型的封装
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.externals import joblib # 目的:保存模型 也可以选择pickle等保存模型,请随意
from sklearn.decomposition import LatentDirichletAllocation
import pyLDAvis
import pyLDAvis.sklearn
def print_top_words(model, feature_names, n_top_words):
# 函数功能:打印每个主题的前几个关键词
for topic_idx, topic in enumerate(model.components_):
print("Topic #%d:" % topic_idx)
print(" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
print()
def CalTopic(docs, i):
# 函数作用:定位每篇文档的主题
# docs:训练好的模型拟合原有数据之后 得到每一篇文档对应到不同主题的概率
# i表示文档i
topic_most_pr = docs[i].argmax()
return topic_most_pr
def LdaModel(df, n_topics, iter_num):
# df已经准备好的数据 有cut_label列
# n_topics:主题数
# iter_num:迭代次数
# 1 数据准备
# df = pd.read_excel('LDA模型数据准备.xlsx')
# 2 停用词导入及增加
list_100 = list(range(100))
list_100_str = list(map(lambda x: str(x), list_100))
# 从文件导入停用词表
stpwrdpath = "stop_words.txt"
stpwrd_dic = open(stpwrdpath, encoding='gbk') # 加上编码,不然就不会显示中文了!
stpwrd_content = stpwrd_dic.read()
# print(stpwrd_content)
#将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
# 在停用词里面再把年龄 也就是具体的数字全部去掉 所以停用词加上0-100的数字!
stpwrdlst = stpwrdlst + list_100_str # 先测试这一版 如果不对 就要把数字变成字符[修改了!]
stpwrd_dic.close()
# 3 关键字提取和向量转换
n_features = 1000
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features = n_features,
stop_words = stpwrdlst,
max_df = 0.5,
min_df = 10
)
tf = tf_vectorizer.fit_transform(df['cut_label'])
# 存储上述tf 节省时间
# joblib.dump(tf_vectorizer,tf_ModelPath )
# #得到存储的tf_vectorizer,节省预处理时间
# tf_vectorizer = joblib.load(tf_ModelPath)
# tf = tf_vectorizer.fit_transform(df['cut_label'])
# 4 搭建LDA模型
lda = LatentDirichletAllocation(n_components = n_topics,
max_iter=iter_num,
learning_method='online',
learning_offset=50,
random_state=23)
# 5 拟合模型
lda.fit(tf) # tf即为Document_word Sparse Matrix
# 6 查看模型结果
n_top_words = 10
tf_feature_names = tf_vectorizer.get_feature_names()
print_top_words(lda, tf_feature_names, n_top_words)
# 7 可视化展示的数据准备
pyLDAvis.enable_notebook()
pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
data = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
# 8 定位到每个人的主题
docs = lda.fit_transform(tf)
# 重新定义索引
df.index = range(len(df))
df['topic'] = df.index.map(lambda x: CalTopic(docs, x))
return docs, data, df
docs_, data_, df_ = LdaModel(df, 5, 50) # 表示5个主题 迭代50次
pyLDAvis.show(data_)
后续可以按照上述方法定位到每一个人的主题 然后再去做进一步的数据探索
7 参考
- https://zhuanlan.zhihu.com/p/31470216
- http://www.voidcn.com/article/p-zxtbxynk-kn.html
- https://www.zhihu.com/question/32286630
- https://blog.csdn.net/v_july_v/article/details/41209515
- https://www.cnblogs.com/pinard/p/6831308.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









