










🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+

目录
Tomotopy简介
tomotopy 是 tomoto(主题建模工具)的 Python 扩展,它是用 C++ 编写的基于 Gibbs 采样的主题模型库。支持的主题模型包括 LDA、DMR、HDP、MG-LDA、PA 和 HPA, 利用现代 CPU 的矢量化来最大化速度。
当前版本的 tomotopy 支持的主题模型包括:
-
潜在狄利克雷分配(LDAModel)
-
标记的 LDA(LLDA 模型)
-
部分标记的 LDA(PLDA 模型)
-
监督LDA(SLDA模型)
-
Dirichlet 多项回归 (DMRModel)
-
广义狄利克雷多项回归 (GDMRModel)
-
分层狄利克雷过程 (HDPModel)
-
分层LDA(HLDA模型)
-
多粒 LDA(MGLDA 模型)
-
弹珠盘分配(PAModel)
-
分层 PA (HPAModel)
-
相关主题模型(CTModel)
-
动态主题模型 (DTModel)
-
基于伪文档的主题模型(PTModel)。
安装
pip install tomotopy支持的操作系统和 Python 版本是:
-
Linux (x86-64) 和 Python >= 3.6
-
macOS >= 10.13 与 Python >= 3.6
-
Windows 7 或更高版本(x86、x86-64),Python >= 3.6
-
使用 Python >= 3.6 的其他操作系统:需要从源代码编译(使用 c++14 兼容编译器)
安装后,只需导入即可启动tomotopy。
Tomotopy的性能
tomotopy使用 Collapsed Gibbs-Sampling (CGS) 来推断主题的分布和单词的分布。通常 CGS 比 [gensim 的 LdaModel] 使用的变分贝叶斯 (VB) 收敛得更慢,但它的迭代可以计算得更快。此外,tomotopy可以利用具有 SIMD 指令集的多核 CPU,从而加快迭代速度。
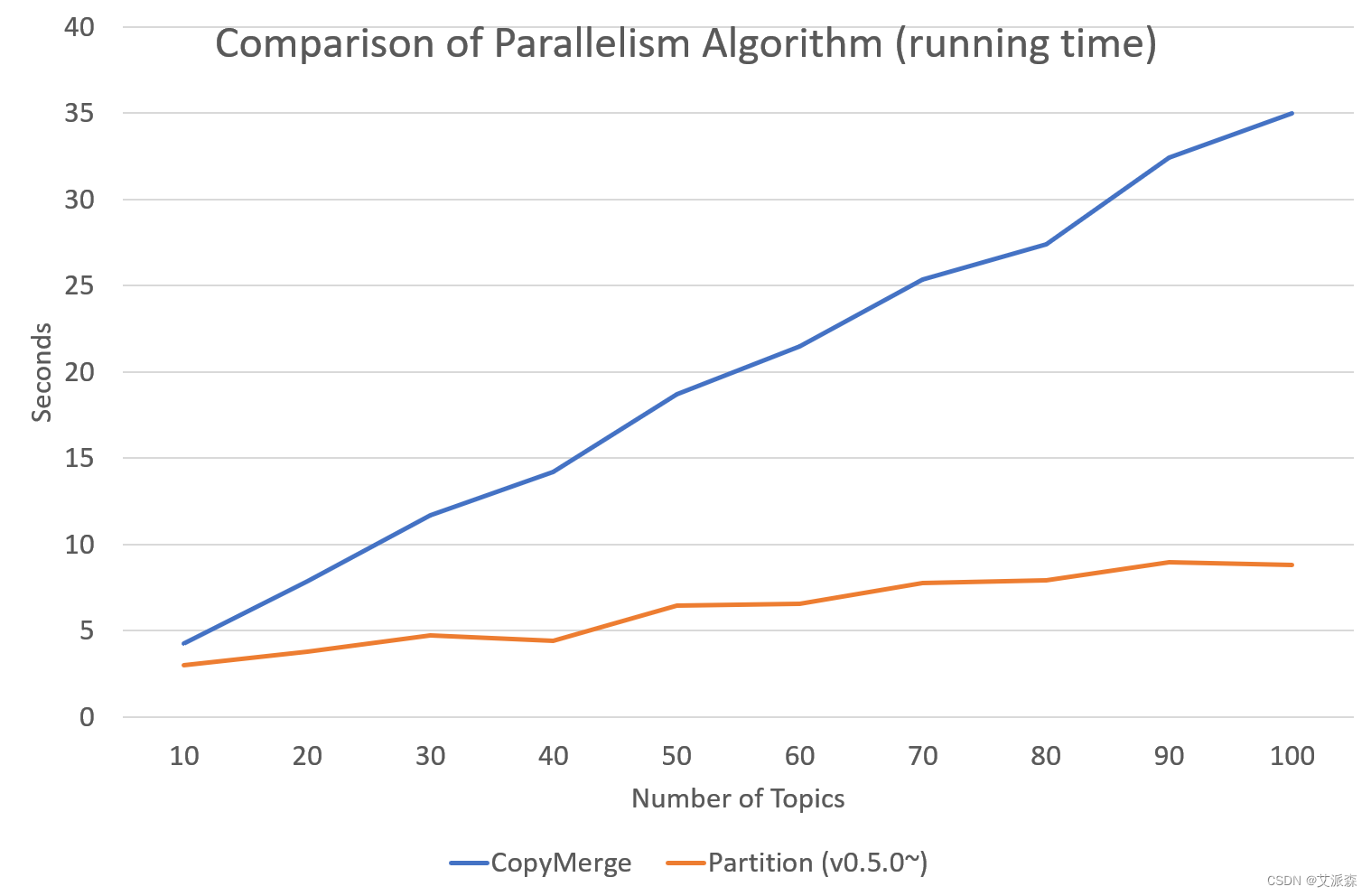
下图显示了tomotopy和gensim之间 LDA 模型运行时间的比较。输入数据由来自英语维基百科的 1000 个随机文档组成,包含 1,506,966 个单词(约 10.1 MB)。 tomotopy训练 200 次迭代,gensim训练 10 次迭代。
实战案例
1.加载数据
首先使用pandas导入数据集,该数据集为某新闻网站里的新闻报道。
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('data.csv')
data.head()
2.中文分词
import re
import jieba
def chinese_word_cut(mytext):
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
test = '杜兰特低迷雷霆加时灭太阳 德克23分小牛1分负灰熊新浪体育讯北京时间3月7日,雷霆主场加时险胜太阳;小牛在最后时刻失利,以1分之差败给灰熊;凯尔特人客场险胜雄鹿。以下是这三场比赛的综述:太阳118-雷霆122(加时)(点击观看视频集锦)雷霆(39-22)三连胜。拉塞尔-威斯布鲁克拿下了32分11次助攻,凯文-杜兰特则表现平平,14投仅3中,得18分,塞尔吉-伊巴卡15分7个篮板。替补出场的詹姆斯-哈登最后时刻立功,拿下了26分,平了个人生涯纪录,他还抢下6个篮板。太阳(32-29)功亏一篑。文斯-卡特得了29分,史蒂夫-纳什11分14次助攻,在NBA总助攻榜上,他超越了伊塞亚-托马斯,排第六。马尔辛-戈塔特20分8个篮板。终场前11.6秒,威斯布鲁克两罚两中,雷霆领先3分。太阳暂停后由卡特投中一记三分,将比分扳成109-109。雷霆最后一投不中,双方进加时。太阳在加时打了一半后才首次得分,达德利和卡特相继三分命中,他们以115-113超出。两队各投失一球后,哈登在终场前34.3秒连投带罚拿下3分,雷霆又取得1分的优势。哈登成为英雄,此后他又抢断得手,威斯布鲁克两罚一中。太阳仍有机会,卡特此后三分线外造成犯规,但遗憾的是他三罚仅一中,太阳仍落后1分。雷霆不再浪费机会,威斯布鲁克和杜兰特连续四次罚球命中,锁定胜局。灰熊104-小牛103小牛(45-17)八连胜终止。德克-诺维茨基拿下了23分,罗德里格-布博瓦15分,替补出场的杰森-特里26分,肖恩-马里昂10分12个篮板。灰熊(35-29)艰难过关,本赛季三度击败了小牛,这是他们史上首次在一个赛季中对小牛胜多负少。扎克-兰多夫投中制胜一球,拿下了27分9个篮板,迈克-康利17分10次助攻,马克-加索尔16分10个篮板。替补出场的肖恩-巴蒂尔11分11个篮板。上半场小牛以55-38领先,不过灰熊第三节砍下41分,三节过后以79-78反超。第四节两队多次战成平手。比赛还有4分19秒时,小牛以95-91领先,康利和亚瑟相继投篮命中,灰熊连得5分,以96-95反超。终场前14.3秒,巴蒂尔抢下进攻篮板,反手上篮,灰熊以102-101领先。小牛暂停后由诺维茨基还以一球,领先权再度易手,此时离比赛结束只有3.1秒。3.1秒已经足够,兰多夫接康利传球后中距离跳投命中,灰熊又一次反超。小牛在最后0.3秒无力创造奇迹,功亏一篑。凯尔特人89-雄鹿83(点击观看视频集锦)凯尔特人(46-15)五连胜。保罗-皮尔斯得了23分,奈纳德-科斯蒂奇17分,凯文-加内特14分11个篮板,雷-阿伦13分,拉简-隆多8助攻8失误。雄鹿(23-38)二连败。布兰顿-詹宁斯得了23分、6个篮板和5次助攻,约翰-萨尔蒙斯11分6次助攻。替补出场的理查德-巴莫特19分。隆多是联盟最会传球的球员之一,但今天他却变成失误高手,失误跟助攻一样多。他的表现也影响了凯尔特人整体,绿衫军全场打得很艰难。上半场凯尔特人以43-49落后,第三节他们以26-16胜出,才将比分反超。终场前2分35秒,雷-阿伦中投命中,凯尔特人以84-82领先。雄鹿在3分钟内一分未得,而凯尔特人由加内特又投中一球,终场前38秒以86-82领先。雄鹿好不容易罚球得了1分,但皮尔斯在终场前17.9秒连投带罚拿下3分,凯尔特人以89-83领先,锁定胜局。(吴哥)'
chinese_word_cut(test)'杜兰特 低迷 雷霆 加时 太阳 德克 小牛 分负 灰熊 体育讯 北京 时间 雷霆 主场 加时 险胜 太阳 小牛 时刻 失利 分之差 败给 灰熊 凯尔特人 客场 险胜 雄鹿 三场 比赛 综述 太阳 雷霆 加时 点击 观看 集锦 雷霆 三连胜 拉塞尔 斯布鲁克 拿下 助攻 凯文 杜兰特 表现 平平 投仅 塞尔吉 伊巴 篮板 替补 出场 詹姆斯 哈登 时刻 立功 拿下 平了 生涯 纪录 抢下 篮板 太阳 功亏一篑 文斯 卡特 史蒂夫 纳什 助攻 助攻 榜上 超越 伊塞亚 托马斯 马尔辛 塔特 篮板 终场 斯布鲁克 两罚 两中 雷霆 领先 太阳 暂停 卡特 投中 一记 三分 比分 扳成 雷霆 投不中 加时 太阳 加时 一半 首次 得分 达德利 卡特 相继 三分 命中 超出 两队 投失 一球 哈登 终场 连投 带罚 拿下 雷霆 优势 哈登 英雄 此后 抢断 得手 斯布鲁克 两罚 一中 太阳 机会 卡特 此后 三分 线外 犯规 遗憾 三罚 一中 太阳 落后 雷霆 浪费 机会 斯布鲁克 杜兰特 连续 四次 罚球 命中 锁定 胜局 灰熊 小牛 小牛 连胜 终止 德克 诺维茨基 拿下 罗德里格 布博瓦 替补 出场 杰森 特里 肖恩 马里昂 篮板 灰熊 艰难 过关 本赛季 三度 击败 小牛 这是 史上 首次 赛季 小牛 胜多 负少 扎克 兰多夫 投中 制胜 拿下 篮板 迈克 康利 助攻 马克 加索尔 篮板 替补 出场 肖恩 巴蒂尔 篮板 上半场 小牛 领先 灰熊 第三节 三节 过后 反超 第四节 两队 战成 平手 比赛 小牛 领先 康利 亚瑟 相继 投篮 命中 灰熊 反超 终场 巴蒂尔 抢下 进攻 篮板 反手 上篮 灰熊以 领先 小牛 暂停 诺维茨基 一球 领先 再度 易手 比赛 结束 足够 兰多夫 接康利 传球 中距离 跳投 命中 灰熊 反超 小牛 无力 创造 奇迹 功亏一篑 凯尔特人 雄鹿 点击 观看 集锦 凯尔特人 连胜 保罗 皮尔斯 奈纳德 科斯蒂 凯文 加内特 篮板 阿伦 拉简 隆多 助攻 失误 雄鹿 连败 兰顿 詹宁斯得 篮板 助攻 约翰 萨尔 蒙斯 助攻 替补 出场 理查德 巴莫 隆多 联盟 最会 传球 球员 失误 高手 失误 助攻 表现 影响 凯尔特人 整体 绿衫 全场 打得 艰难 上半场 凯尔特人 落后 第三节 胜出 比分 反超 终场 阿伦 中投 命中 凯尔特人 领先 雄鹿 分钟 一分 未得 凯尔特人 加内特 投中 终场 领先 雄鹿 好不容易 罚球 皮尔斯 终场 连投 带罚 拿下 凯尔特人 领先 锁定 胜局 吴哥'data["content_cutted"] = data.content.apply(chinese_word_cut)
data.head()
3. 确定主题数K
import tomotopy as tp
def find_k(docs, min_k=1, max_k=20, min_df=2):
# min_df 词语最少出现在2个文档中
import matplotlib.pyplot as plt
scores = []
for k in range(min_k, max_k):
mdl = tp.LDAModel(min_df=min_df, k=k, seed=555)
for words in docs:
if words:
mdl.add_doc(words)
mdl.train(20)
coh = tp.coherence.Coherence(mdl)
scores.append(coh.get_score())
plt.plot(range(min_k, max_k), scores)
plt.xlabel("number of topics")
plt.ylabel("coherence")
plt.show()
find_k(docs=data['content_cutted'], min_k=1, max_k=10, min_df=2)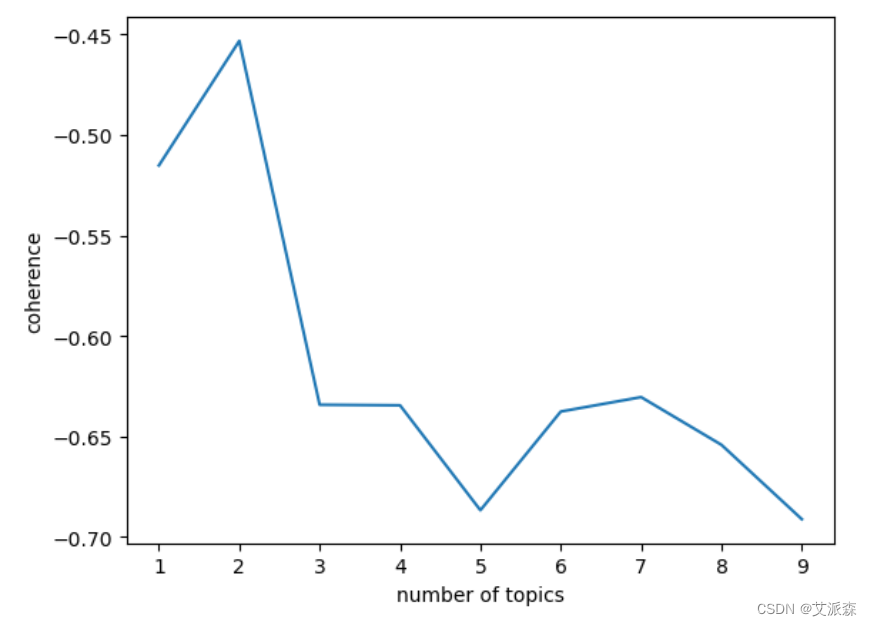
有上图看出,图形最低点为5或9,显然5最合适,9就过拟合了,所以最佳主题数为5。
4.训练模型
# 初始化LDA
mdl = tp.LDAModel(k=5, min_df=2, seed=555)
for words in data['content_cutted']:
#确认words 是 非空词语列表
if words:
mdl.add_doc(words=words.split())
#训 练
mdl.train()
# 查看每个topic feature words
for k in range(mdl.k):
print('Top 20 words of topic #{}'.format(k))
print(mdl.get_topic_words(k, top_n=20))
print('\n')打印结果:
Top 20 words of topic #0
[('中国', 0.012998578138649464), ('发展', 0.009862315841019154), ('合作', 0.00640487065538764), ('工作', 0.0056208050809800625), ('国家', 0.005139030050486326), ('国际', 0.004713934380561113), ('拍摄', 0.004449430387467146), ('关系', 0.0032497155480086803), ('电影', 0.0031646962743252516), ('建设', 0.0031458032317459583), ('北京', 0.0029379785992205143), ('经济', 0.002900192281231284), ('地区', 0.002777386922389269), ('社会', 0.002711260924115777), ('支持', 0.0026167952455580235), ('世界', 0.002607348607853055), ('希望', 0.002569562289863825), ('领域', 0.0025317759718745947), ('计划', 0.0024278636556118727), ('活动', 0.002380630699917674)]
Top 20 words of topic #1
[('比赛', 0.016710450872778893), ('火箭', 0.010061717592179775), ('球队', 0.009697807021439075), ('篮板', 0.008291344158351421), ('球员', 0.007986446842551231), ('时间', 0.007888092659413815), ('防守', 0.006048872135579586), ('热火', 0.0060193659737706184), ('表现', 0.005724303890019655), ('奇才', 0.005094837862998247), ('助攻', 0.00487845903262496), ('进攻', 0.0046030678786337376), ('科比', 0.004553890787065029), ('赛季', 0.0043571824207901955), ('体育讯', 0.0042096516117453575), ('湖人', 0.004199816379696131), ('詹姆斯', 0.004170309752225876), ('三分', 0.003934260457754135), ('命中', 0.003924424760043621), ('对手', 0.003904754063114524)]
Top 20 words of topic #2
[('电影', 0.016132455319166183), ('导演', 0.008549179881811142), ('发现', 0.007281528320163488), ('时间', 0.0059233298525214195), ('很多', 0.0054479604586958885), ('研究', 0.005364959128201008), ('影片', 0.005357413552701473), ('观众', 0.004474584944546223), ('科学家', 0.004346310626715422), ('票房', 0.004150126129388809), ('拍摄', 0.003697393462061882), ('北京', 0.003546482417732477), ('一种', 0.0034106627572327852), ('上映', 0.003335207235068083), ('地球', 0.0032371152192354202), ('消息', 0.0031692052725702524), ('生活', 0.0031314773950725794), ('娱乐', 0.0030635674484074116), ('发生', 0.003010748652741313), ('角色', 0.002988112159073353)]
Top 20 words of topic #3
[('中国', 0.00796604622155428), ('台湾', 0.00669356482103467), ('美国', 0.006248713470995426), ('人民币', 0.004965886007994413), ('报道', 0.003238207660615444), ('经济', 0.0031864808406680822), ('文物', 0.0028243924025446177), ('日本', 0.002783010946586728), ('工作', 0.0027002478018403053), ('国家', 0.002627830021083355), ('香港', 0.002576103201135993), ('媒体', 0.002317468635737896), ('包括', 0.002296777907758951), ('地震', 0.002296777907758951), ('相关', 0.0022553964518010616), ('两岸', 0.0021829786710441113), ('信用卡', 0.0021622879430651665), ('美元', 0.0021415972150862217), ('价格', 0.0020484887063503265), ('艺术', 0.0020277979783713818)]
Top 20 words of topic #4
[('基金', 0.0364646315574646), ('银行', 0.014307986944913864), ('投资', 0.012498501688241959), ('市场', 0.012406881898641586), ('产品', 0.006123312283307314), ('亿元', 0.005947708152234554), ('债券', 0.00511549785733223), ('管理', 0.0047871945425868034), ('风险', 0.004565780982375145), ('资金', 0.0042985575273633), ('股票', 0.004107683431357145), ('投资者', 0.004100048448890448), ('收益', 0.004031334072351456), ('业务', 0.003954984247684479), ('企业', 0.003939714282751083), ('人士', 0.003748840419575572), ('发行', 0.0035808715038001537), ('增长', 0.0035274268593639135), ('规模', 0.003489251947030425)]
# 查看话题模型信息
mdl.summary()<Basic Info>
| LDAModel (current version: 0.12.4)
| 2500 docs, 566206 words
| Total Vocabs: 64857, Used Vocabs: 29850
| Entropy of words: 9.00108
| Entropy of term-weighted words: 9.00108
| Removed Vocabs: <NA>
|
<Training Info>
| Iterations: 10, Burn-in steps: 0
| Optimization Interval: 10
| Log-likelihood per word: -9.31939
|
<Initial Parameters>
| tw: TermWeight.ONE
| min_cf: 0 (minimum collection frequency of words)
| min_df: 2 (minimum document frequency of words)
| rm_top: 0 (the number of top words to be removed)
| k: 5 (the number of topics between 1 ~ 32767)
| alpha: [0.1] (hyperparameter of Dirichlet distribution for document-topic, given as a single `float` in case of symmetric prior and as a list with length `k` of `float` in case of asymmetric prior.)
| eta: 0.01 (hyperparameter of Dirichlet distribution for topic-word)
| seed: 555 (random seed)
| trained in version 0.12.4
|
<Parameters>
| alpha (Dirichlet prior on the per-document topic distributions)
| [0.59691167 0.49684513 0.59214205 0.5938972 0.5040762 ]
| eta (Dirichlet prior on the per-topic word distribution)
| 0.01
|
<Topics>
| #0 (105560) : 中国 发展 合作 工作 国家
| #1 (101375) : 比赛 火箭 球队 篮板 球员
| #2 (132230) : 电影 导演 发现 时间 很多
| #3 (96363) : 中国 台湾 美国 人民币 报道
| #4 (130678) : 基金 银行 投资 市场 产品topic解读
根据每个话题top20的特征词,5个话题解读为:
科技| #0 (105560) : 中国 发展 合作 工作 国家
体育| #1 (101375) : 比赛 火箭 球队 篮板 球员
娱乐| #2 (132230) : 电影 导演 发现 时间 很多
时政| #3 (96363) : 中国 台湾 美国 人民币 报道
财经| #4 (130678) : 基金 银行 投资 市场 产品
5.可视化
import pyLDAvis
import numpy as np
# 在notebook显示
pyLDAvis.enable_notebook()
# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freq
prepared_data = pyLDAvis.prepare(
topic_term_dists,
doc_topic_dists,
doc_lengths,
vocab,
term_frequency,
start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始
sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)
# 可视化结果存到html文件中
# pyLDAvis.save_html(prepared_data, 'ldavis.html')
# notebook中显示
pyLDAvis.display(prepared_data)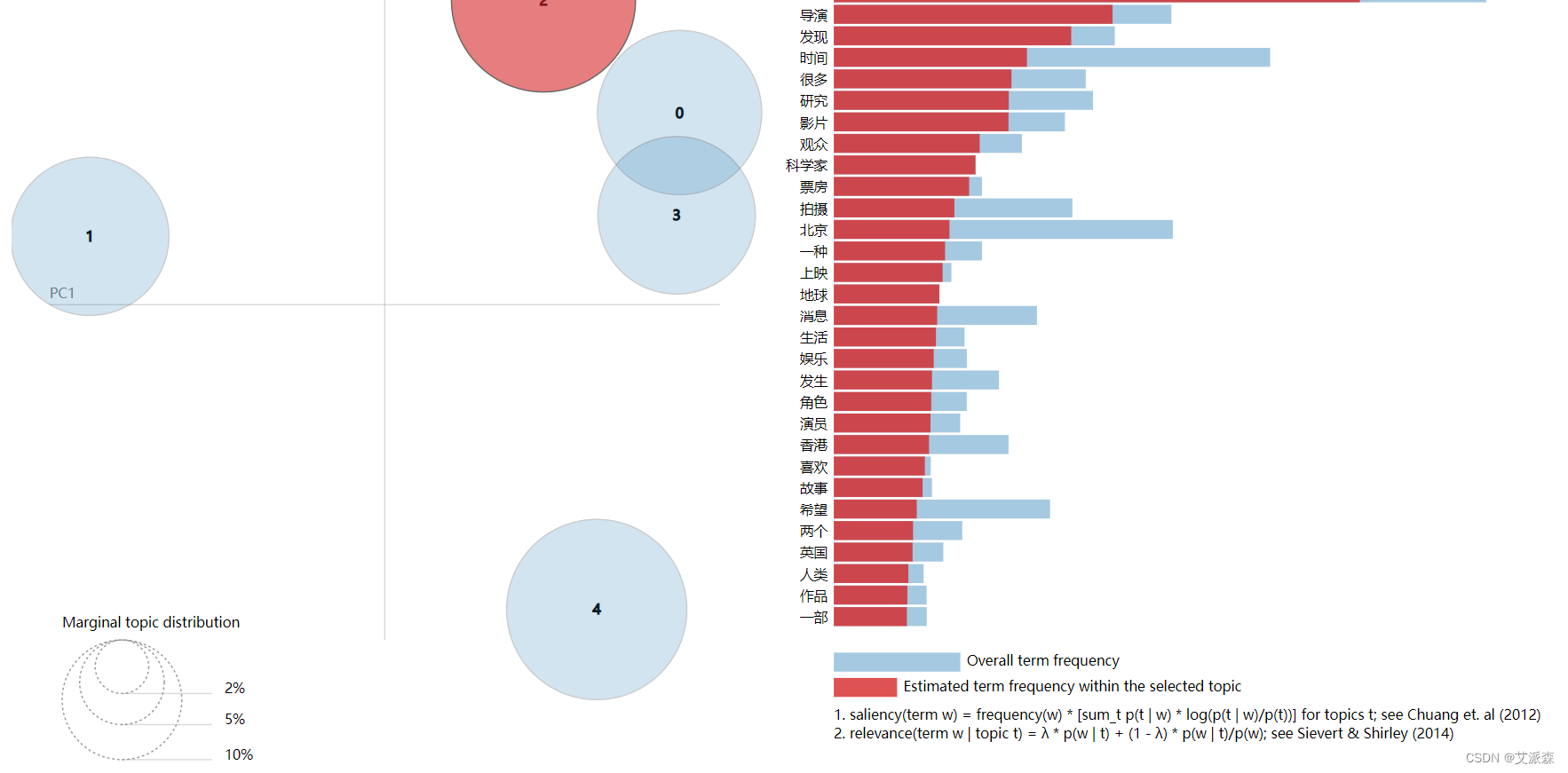
6.预测
# 预测
doc = '杜兰特低迷雷霆加时灭太阳 德克23分小牛1分负灰熊新浪体育讯北京时间3月7日,雷霆主场加时险胜太阳;小牛在最后时刻失利,以1分之差败给灰熊;凯尔特人客场险胜雄鹿。以下是这三场比赛的综述:太阳118-雷霆122(加时)(点击观看视频集锦)雷霆(39-22)三连胜。拉塞尔-威斯布鲁克拿下了32分11次助攻,凯文-杜兰特则表现平平,14投仅3中,得18分,塞尔吉-伊巴卡15分7个篮板。替补出场的詹姆斯-哈登最后时刻立功,拿下了26分,平了个人生涯纪录,他还抢下6个篮板。太阳(32-29)功亏一篑。文斯-卡特得了29分,史蒂夫-纳什11分14次助攻,在NBA总助攻榜上,他超越了伊塞亚-托马斯,排第六。马尔辛-戈塔特20分8个篮板。终场前11.6秒,威斯布鲁克两罚两中,雷霆领先3分。太阳暂停后由卡特投中一记三分,将比分扳成109-109。雷霆最后一投不中,双方进加时。太阳在加时打了一半后才首次得分,达德利和卡特相继三分命中,他们以115-113超出。两队各投失一球后,哈登在终场前34.3秒连投带罚拿下3分,雷霆又取得1分的优势。哈登成为英雄,此后他又抢断得手,威斯布鲁克两罚一中。太阳仍有机会,卡特此后三分线外造成犯规,但遗憾的是他三罚仅一中,太阳仍落后1分。雷霆不再浪费机会,威斯布鲁克和杜兰特连续四次罚球命中,锁定胜局。灰熊104-小牛103小牛(45-17)八连胜终止。德克-诺维茨基拿下了23分,罗德里格-布博瓦15分,替补出场的杰森-特里26分,肖恩-马里昂10分12个篮板。灰熊(35-29)艰难过关,本赛季三度击败了小牛,这是他们史上首次在一个赛季中对小牛胜多负少。扎克-兰多夫投中制胜一球,拿下了27分9个篮板,迈克-康利17分10次助攻,马克-加索尔16分10个篮板。替补出场的肖恩-巴蒂尔11分11个篮板。上半场小牛以55-38领先,不过灰熊第三节砍下41分,三节过后以79-78反超。第四节两队多次战成平手。比赛还有4分19秒时,小牛以95-91领先,康利和亚瑟相继投篮命中,灰熊连得5分,以96-95反超。终场前14.3秒,巴蒂尔抢下进攻篮板,反手上篮,灰熊以102-101领先。小牛暂停后由诺维茨基还以一球,领先权再度易手,此时离比赛结束只有3.1秒。3.1秒已经足够,兰多夫接康利传球后中距离跳投命中,灰熊又一次反超。小牛在最后0.3秒无力创造奇迹,功亏一篑。凯尔特人89-雄鹿83(点击观看视频集锦)凯尔特人(46-15)五连胜。保罗-皮尔斯得了23分,奈纳德-科斯蒂奇17分,凯文-加内特14分11个篮板,雷-阿伦13分,拉简-隆多8助攻8失误。雄鹿(23-38)二连败。布兰顿-詹宁斯得了23分、6个篮板和5次助攻,约翰-萨尔蒙斯11分6次助攻。替补出场的理查德-巴莫特19分。隆多是联盟最会传球的球员之一,但今天他却变成失误高手,失误跟助攻一样多。他的表现也影响了凯尔特人整体,绿衫军全场打得很艰难。上半场凯尔特人以43-49落后,第三节他们以26-16胜出,才将比分反超。终场前2分35秒,雷-阿伦中投命中,凯尔特人以84-82领先。雄鹿在3分钟内一分未得,而凯尔特人由加内特又投中一球,终场前38秒以86-82领先。雄鹿好不容易罚球得了1分,但皮尔斯在终场前17.9秒连投带罚拿下3分,凯尔特人以89-83领先,锁定胜局。(吴哥)'
words = chinese_word_cut(doc)
# 构造tomotopy需要的数据
doc_inst = mdl.make_doc(words=words.split())
topic_dist, ll = mdl.infer(doc_inst)
print("Topic Distribution for Unseen Docs: ", topic_dist)Topic Distribution for Unseen Docs: [0.03505888 0.9144849 0.0410907 0.00784167 0.00152388]输出的结果是该文档是每个主题的概率值,可以发现主题2(#1)的概率最大,也就是体育类的话题。
补充:指定主题特征词
如果对数据比较了解,已经知道有一些主题,可以把比较明显的词语分配给指定的topic_id。
import tomotopy as tp
mdl = tp.LDAModel(k=5, min_df=2, seed=555)
for words in data['content_cutted']:
#确认words 是 非空词语列表
if words:
mdl.add_doc(words=words.split())
# 把word科技 分配给topic_0, 权重设置为1, 其他topic权重设置为0.1,注意这里的range(5) 5是对应的k值
mdl.set_word_prior('科技', [1.0 if k == 0 else 0.1 for k in range(5)])
# 把word比赛 分配给topic_1, 权重设置为1, 其他topic权重设置为0.1
mdl.set_word_prior('比赛', [1.0 if k == 1 else 0.1 for k in range(5)])
# 把word影视 分配给topic_2, 权重设置为1, 其他topic权重设置为0.1
mdl.set_word_prior('影视', [1.0 if k == 2 else 0.1 for k in range(5)])
# 把word国家 分配给topic_3, 权重设置为1, 其他topic权重设置为0.1
mdl.set_word_prior('国家', [1.0 if k == 3 else 0.1 for k in range(5)])
# 把word财经 分配给topic_4, 权重设置为1, 其他topic权重设置为0.1
mdl.set_word_prior('财经', [1.0 if k == 4 else 0.1 for k in range(5)])
mdl.train()
mdl.summary() <Basic Info>
| LDAModel (current version: 0.12.4)
| 2500 docs, 566206 words
| Total Vocabs: 64857, Used Vocabs: 29850
| Entropy of words: 9.00108
| Entropy of term-weighted words: 9.00108
| Removed Vocabs: <NA>
|
<Training Info>
| Iterations: 10, Burn-in steps: 0
| Optimization Interval: 10
| Log-likelihood per word: -9.18584
|
<Initial Parameters>
| tw: TermWeight.ONE
| min_cf: 0 (minimum collection frequency of words)
| min_df: 2 (minimum document frequency of words)
| rm_top: 0 (the number of top words to be removed)
| k: 5 (the number of topics between 1 ~ 32767)
| alpha: [0.1] (hyperparameter of Dirichlet distribution for document-topic, given as a single `float` in case of symmetric prior and as a list with length `k` of `float` in case of asymmetric prior.)
| eta: 0.01 (hyperparameter of Dirichlet distribution for topic-word)
| seed: 555 (random seed)
| trained in version 0.12.4
|
<Parameters>
| alpha (Dirichlet prior on the per-document topic distributions)
| [0.5278153 0.3733458 0.5314604 0.52304363 0.4286112 ]
| eta (Dirichlet prior on the per-topic word distribution)
| 0.01
|
<Topics>
| #0 (106047) : 发现 研究 时间 科学家 美国
| #1 (105760) : 比赛 火箭 球队 时间 篮板
| #2 (123916) : 电影 导演 影片 观众 很多
| #3 (110731) : 中国 发展 国家 工作 国际
| #4 (119752) : 基金 银行 市场 投资 亿元
文末推荐

参与福利
- 抽奖方式:评论区随机抽取2位小伙伴免费送出!
- 参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,拒绝内卷!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
- 活动截止时间:2023-06-03 20:00:00
- 京东自营店购买链接:https://item.jd.com/13738563.html
名单公布时间:2023-06-03 21:00:00


















 318
318











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











